 從頭開始編寫任何機器學習算法的6個步驟
從頭開始編寫任何機器學習算法的6個步驟
本文以單層感知器為案例,介紹從頭開始編寫任何機器學習算法的6個步驟。這些方法可以很容易地用于其他機器學習算法。
從頭開始編寫算法是一種有益的體驗,當你最終點擊運行的那一刻,你會了解算法背后真正發生了什么。
如果你以前用scikit-learn實現過這個算法,從頭開始編寫就會很容易?不是這樣。
有些算法只是比其他算法更復雜,所以可以從簡單的開始,比如單層感知器(Perceptron)。
本文將以感知器為案例,引導你完成從頭開始編寫算法的6個步驟。這種方法可以很容易地用于編寫其他機器學習算法。
1. 對算法有一個基本的了解
這又回到了我最初所說的。如果你不了解基礎知識,請不要從頭開始處理算法。至少,你應該能夠回答以下問題:
它是什么?
它通常用于做什么?
什么時候不能使用它?
對于感知器,上面三個問題的答案是:
單層感知器是最基本的神經網絡,通常用于二進制分類問題(1或0,“是”或“否”)。
它是一個線性分類器,因此只有在存在線性決策邊界的情況下才能有效使用。一些簡單的用途可以是情緒分析(正面或負面反應)或貸款違約預測(“會違約”,“不會違約”)。對于這兩種情況,決策邊界都必須是線性的。
如果決策邊界是非線性的,那么你實際上無法使用感知器。對于這些問題,需要使用其他算法。
2. 找到各種類型的學習資源
在對模型有了基本的了解之后,是時候開始進行研究了。我建議使用大量資源。有些人用教科書學得更好,有些人用視頻學得更好。就我個人而言,我喜歡使用各種類型的資源。對于數學細節,教科書的解釋很好,但對于更實際的例子,我更喜歡看博客文章和YouTube視頻。
對于感知器,這里有一些很棒的資源。
教材:
《統計學習基礎》,第4.5.1節
《深入理解機器學習:從原理到算法》,第21.4節
博客:
JasonBrownlee的Machine Learning Mastery系列文章,其中一篇是《如何用Python從頭開始實現感知器算法》:
https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/
SebastianRaschka的博客,Single-Layer Neural Networks and Gradient Descent
https://sebastianraschka.com/Articles/2015_singlelayer_neurons.html
視頻:
感知器訓練:
https://www.youtube.com/watch?v=5g0TPrxKK6o
Perceptron算法的工作原理:
https://www.youtube.com/watch?v=1XkjVl-j8MM
3. 將算法分解為塊
現在,我們已經收集了需要的資料,是時候開始學習了。與其從頭到尾閱讀書本或博客文章,不如先瀏覽一下章節標題和其他重要信息。寫下要點,并嘗試概述算法。
在瀏覽完這些資料后,我們可以將Perceptron算法分解為以下幾個塊(chunks):
初始化權重
將輸入乘以權重,并求和
將結果與閾值進行比較,并計算輸出(1或0)
更新權重
重復這個過程
將算法分解成這樣的塊,可以使得學習更容易。基本上,我已經使用偽代碼概述了這個算法,現在可以回過頭來填寫細節了。 下面這張圖是第二步的筆記,即權重和輸入的點積:

4. 從一個簡單的例子開始
在整理好算法相關的筆記后,是時候開始在代碼中實現它了。
在深入研究一個復雜的問題之前,我想先從一個簡單的例子開始。對于感知器,NAND gate(與非門)是一個完美的簡單數據集。如果兩個輸入都為真(1),則輸出為假(0),否則輸出為真。下面是數據集的一個示例:
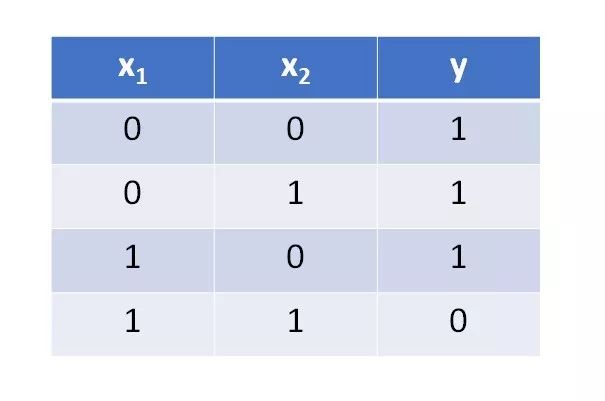
現在,有了一個簡單的數據集,我將開始實現我在步驟3中概述的算法。最好將這個算法分成塊編寫并進行測試,而不是試圖一次性寫完。這樣在剛開始時更容易調試。
下面是我在步驟3中概述的算法點積部分的Python代碼示例:
5. 使用可信的實現進行驗證
我們已經編寫了代碼,并針對一個小數據集進行了測試,現在是時候擴展到更大的數據集了。為了確保我們的代碼在這個更復雜的數據集上正確工作,最好在一個可信的實現上對其進行測試。對于感知器,我們可以使用scikit-learn中的實現。
為了測試代碼,我將檢查權重。如果正確地實現了算法,我的權重應該與scikit-learn中感知器的權重相匹配。
一開始,我沒有得到相同的權重,這是因為我不得不調整scikit-learn Perceptron中的默認設置。我并不是每次都實現一個新的隨機狀態,而只是一個fixed seed,所以不得不關閉它。shuffling也是這樣,也需要關閉它。為了匹配學習率,我將eta0改為0.1。最后,我關閉了fit_intercept選項。我在特征數據集中包含了一個1的虛擬列,所以已經自動擬合了偏差項。
這引出了另一個重要的問題。在驗證模型的現有實現時,你需要非常清楚模型的輸入。你不應盲目地使用模型,而要總是質疑你的假設,以及每個輸入的確切含義。
6. 寫下你的過程
這個過程的最后一步可能是最重要的。 你已經完成所有的學習工作,做了筆記,從頭開始編寫了算法,并將它與可信的實現進行了比較。那么不要讓所有這些工作白白浪費掉。編寫流程非常重要,原因是:
你會得到更深刻的理解,因為這樣做相當于在教別人你剛學到的東西。你可以向潛在的雇主展示它。證明你可以利用機器學習庫實現算法是一回事,但如果你可以從頭開始實現一個算法,那就更令人印象深刻了。
結論
從頭開始編寫算法是一種非常有益的體驗。這是深入了解模型、構建一個令人印象深刻的項目組合的好方法。
記得要慢慢來,從簡單的事情開始吧。最重要的是,一定要記錄和分享你的工作。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101171 -
算法
+關注
關注
23文章
4630瀏覽量
93355 -
機器學習
+關注
關注
66文章
8438瀏覽量
133086
原文標題:只需6步,從頭開始編寫機器學習算法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
經典算法大全(51個C語言算法+單片機常用算法+機器學十大算法)
MikroElektronika的mikroBUS Click板是否從頭開始的制作?
ARM嵌入式系統設計:從頭開始構建還是使用SBC?
Excel本身就能編寫大量基礎機器學習算法

如果要從事機器學習方面的研發,可以按照以下幾個步驟學習
TensorFlow Quantum將允許用戶編寫Quantum應用程序
PyTorch教程4.4之從頭開始實現Softmax回歸

PyTorch教程-3.4. 從頭開始執行線性回歸






 工商網監
工商網監
評論