 淺析英特爾QSV技術在FFmpeg中的具體實現與使用
淺析英特爾QSV技術在FFmpeg中的具體實現與使用
本文來自英特爾資深軟件工程師張華在LiveVideoStackCon 2018講師熱身分享,并由LiveVideoStack整理而成。在分享中張華介紹了英特爾GPU硬件架構,并詳細解析了英特爾QSV技術在FFmpeg中的具體實現與使用。
1、處理器整體架構
大家知道,英特爾的圖形處理GPU被稱為“核芯顯卡”,與CPU集成封裝在同一個芯片上,上圖展示的是芯片的內部結構。
1.1 發展
英特爾從lvy Bridge架構開始就嘗試將GPU與CPU集成在中央處理芯片中并逐代發展到Skylake架構。初期的Ivy Bridge架構中GPU所占的面積非常小,而到現在的第五代處理器架構Skylake已經實現十分成熟的GPU集成技術,GPU在芯片中所占的面積已經超過了一半。在未來我們將推出基于PCI-E的獨立顯卡,為PC帶來更大的圖像性能提升。
1.2 基礎功能模塊
上圖展示的是一款GPU所具備的一些基礎功能模塊。英特爾的核芯顯卡分為普通的Intel HD Graphics與性能強大的Intel Iris (Pro)Graphics,其中硬件結構的變化決定性能的高低。我們知道,GPU中的Slice個數越多,處理單元的組織方式越多,性能便越強大。Intel HD Graphics也就是GT2中只有一個Slice,而對于Iris系列中的GT3則有兩個Slice;GT3e相對于GT3增加了eDRAM使其具有更快的內存訪問速度,而GT4e則增加到三個Slice。GPU的基礎功能模塊主要由EU以及相關的Media Processing(MFX)等組成。一個Slice中有三個Sub-Slice,Sub-Slice中包含具體的EU和Media Sampler模塊作為最基本的可編程處理單元,GPU相關的任務都是在EU上進行。而Media Processing中還集成了一個被稱為MFX的獨立模塊,主要由Media Format Codec(MFX)與VQE組成。MFX可將一些處理任務通過Fix Function打包,固定于一個執行單元中進行統一的編解碼處理,不調用EU從而實現提高EU處理3D圖形等任務的速度。Video Quality Engine(VQE)提供De-interlace與De-Noise等視頻處理任務,在編解碼中使用EU是為了得到更高的視頻編碼質量。
1.3 結構演進
上圖展示的是英特爾幾代核芯顯卡產品在結構上的變化。最早的Haswell架構也就是v3系列中的EU個數相對較少,最多為40個;而到Broadwell架構的GT3中集成了2個Slice,EU個數隨之增加到48個,圖像處理性能也隨之增強。從Broadwell架構發展到Skylake架構,除了EU與Slice格式增加的變化,MFX的組織也有相應改進。Broadwell架構是將MFX集成于一個Slice中,一個Slice集成一個MFX;而到Skylake架構之后Slice的個數增加了但MFX的個數并沒有,此時的MFC便集成在Slice之外。隨著組織方式的改變,核芯顯卡的功能也隨之改變:Skylake增加了HEVC的Decoder、PAK增加了基于HEVC的處理功能等改進為核芯顯卡整體處理性能帶來了顯著提升,第六代以后的核芯顯卡也都主要沿用GT3的架構組織。
上文介紹了核芯顯卡硬件上的模塊結構,接下來我將具體介紹Quick Sync Video Acceleration。從Driver分發下來的Command Stream回通過多條路徑在GPU上得到執行:如果命令屬于編解碼的Fix Function則會由MFX執行,部分與視頻處理相關的命令會由VQE執行,其他的命令則會由EU執行。而編碼過程主要分為兩部分:ENC與PAK。ENC主要通過硬件實現Rate Control、Motion Estimation、Intra Prediction、Mode Decision等功能;PAK進行Motion Comp、Intra Prediction、Forward Quant、Pixel Reconstruction、Entropy Coding等功能。在目前的英特爾架構中,Media SDK通過API對硬件進行統一的調度與使用,同時我們提供更底層的接口Flexible Encoder Interface(FEI)以實現更優秀的底層調度與更好的處理效果。
2、軟件策略
接下來我將介紹英特爾的軟件策略。最底層的FFmpeg可允許開發者將QSV集成進FFmpeg中以便于開發,而Media SDK則主要被用于編解碼處理,FFmpeg可把整個多媒體處理有效結合。如果開發者認為傳統的Media SDK的處理質量無法達到要求或碼率控制不符合某些特定場景,那么可以通過調用FEI等更底層的接口對控制算法進行優化;最頂層的OpenCL接口則利用GPU功能實現邊緣計算等處理任務,常見的Hybrid編碼方式便使用了OpenCL。除此之外OpenCL也可實現一些其他的并行處理功能,例如與AI相關的一些計算。
2.1 Media SDK
Media SDK分為以下幾個版本:Community Edition是一個包含了基本功能的部分免費版本,Essential Edition與Professional Edition則是具有更多功能的收費版本,可實現例如hybrid HEVC 編碼,Audio的編解碼、Video Quality Caliper Tool等諸多高級功能和分析工具的集合。
1)軟件架構
上圖主要介紹的是Media Server Studio Software Stack軟件架構,我們基于此架構實現FFmpeg的加速。
這里需要強調的是:
a)OpenGL (mesa)與linux內核一直是開源的項目,但之前版本的MSS中存在一些私有的內核補丁,并對操作系統的或對Linux的內核版本有特殊要求。
b)HD Graphics Driver for Linux之前是一個閉源的方案,而現在的MSDK 和用戶態驅動(iHD驅動)都已經實現開源。現在我們正在制作一個基于開源版本的Release,未來大家可以通過此開源平臺獲得更好的技術支持。
2)編解碼支持
關于編解碼支持,其中我想強調的是HEVC 8 bit 與10 bit的編解碼。在Gen 9也就是Skylake上并不支持硬件級別的HEVC 10 bit解碼,面對這種情況我們可以通過混合模式實現對HEVC 10 bit的編解碼功能。最新E3v6(Kabylake)雖然只有較低性能的GPU配置,但可以支持HEVC 10 bit解碼,HEVC 10 bit編碼功能則會在以后發布的芯片中提供。
2.2 QSV到FFmpeg的集成思路
FFmpeg集成的思路主要如下:
1)FFmpeg QSV Plugins:將SDK作為FFmpeg的一部分進行封裝,其中包括Decoder、Encoder與VPP Filter處理。
2)VAPPI Plugin:Media對整個英特爾GPU的軟件架構而言,從最底層的linux內核,中間有用戶態驅動,對外的統一的接口就是VAAPI。Media SDK的硬件加速就是基于VAAPI開發,同時增加了很多相關的功能,其代碼更為復雜;而現在增加的VAAPI Plugin則會直接調用LibAV使軟硬件結合更為緊密。
接下來我將介紹如何將SDK集成到FFmpeg中,一共分為AVDecoder、AVEncoder、AVFilter三個部分。
1)AVFilter
AVFilter主要是利用硬件的GPU實現Video Processor功能,其中包括vpp_qsv、overlay_qsv、hwupload_qsv,其中我們重點開發了overlay_qsv,vpp_qsv與hwupload_qsv。 如果在一個視頻處理的pipeline中有多個VPP的實例運行,會對性能造成很大的影響。我們的方案是實現一個大的VPP Filter中集成所有功能并通過設置參數實現調用,避免了多個VPP的實例存在。但是為什么將vpp_qsv與overlay_qsv分開?這是因為無法在一個VPP實例中同時完成compositor和一些視頻處理功能(像de-interlace等)。英特爾核芯顯卡內顯存中的存儲格式為NV12, 和非硬件加速的模塊聯合工作時,需要對Frame Buffer進行從系統內存到顯卡顯存的復制過程,hwupload_qsv提供了在系統內存和顯卡內存之間進行快速幀轉換的功能。
2)AVEncoder
AVEncoder目前支持H264、HEVC、MPEG-2等解碼的硬件加速。
3)AVDecoder
AVDecoder目前支持H264、HEVC、MPEG-2等協議的硬件加速。
最理想的方案是在整條視頻處理的Pipeline中都使用顯卡內存從而不存在內存之間的幀拷貝,從而達到最快的處理速度,但在實際應用中我們很多時候是做不到這一點。將MSDK集成進FFmpeg中時需要解決內存轉換的問題,例如VPP Filter不支持一些功能或原始碼流并不在Decoder支持的列表中。上圖中粉色與綠色的轉換表示的就是數據從顯存到系統內存再到顯存之間的轉換。我們在實踐中經常會遇到處理性能的急劇變化,可能的原因就是一些非硬件處理的模塊和硬件加速的模塊存在與同一個pipeline中,從而對整體性能造成影響。這是因為進行了額外的內存拷貝過程,一旦優化不足則會極大影響性能。具體進行內存分配時我們使用了hwcontext,這是FFmpeg在3.0之后增加的一個功能。我們基于FFmpeg中hwcontext的機制實現了hwcontext_qsv,從而對硬件的初始化與內存分配進行很好的管理。
3、對比MSS與FFmpeg+QSV
下面我將分享MSS與FFmpeg+QSV的異同。二者支持相同的編解碼器與視頻處理。
二者的差異有:
1)MSS 僅提供了一套庫和工具,用戶必須基于 MSS進行二次開發;而FFmpeg 是一個流行的多媒體開放框架, QSV的GPU加速只是其中的一部分。
2)MSS的庫中提供 了VPP 接口,用戶要實現某些功能必須進行二次開發。而目前,FFmpeg+QSV已存在2個開發好的Filter,并且在Filter中集成了MSS 支持的所有功能,并提供更加簡單的選項進行配置,這些功能對用戶而言都是方便使用的。
3)在內存管理上,MSS的開發人員必須管理自己的內存;而FFmpeg 提供基本的內存管理單元并實現系統內存的統一調用,集成了硬件級別的內存處理機制。
4) FFmpeg 提供了一定的容錯機制與 a/v 同步機制;FFmpeg+QSV 模塊充分利用這些機制來提高兼容性,像使用ffmpeg的parse工具進行視頻流預處理。
5)處理流程上,MSS的用戶在使用MSS模塊之前必須自己開發Mux/Demux或其他必要的模塊;而FFmpeg+QSV 由于是基于 MSS 實現并添加了特殊的邏輯, 每個模塊都可與 FFmpeg 的其他模塊一起工作。
可以說FFmpeg有很強大的媒體支持,相對于傳統的MSS在保證性能與質量的前提下為用戶節省很多工作量并顯著提升開發效率。
4、實踐與測試
上圖展示的是我們在Skylake也就是Gen 9上測試硬件轉碼能力的結果。GT2、GT31、GT41三個型號性能遞增;TU1、TU2、TU4、TU7表示編解碼性能與圖像質量的均衡程度,其中TU7表示最快的處理速度和較差的圖像質量,TU1表示基于大量計算得到的較高圖像質量。
上圖展示的是Skylake對HEVC支持的性能數據,其中的分辨率為1080P,其實HEVC 4K60p也能得到很好的性能。隨著輸出圖像質量的提升,轉碼速度也會相應降低,但在正常使用中我們主要根據需求平衡性能與質量,在較短時間內實現較高質量的轉碼輸出。
如果重點分析圖像質量,在實踐中我們建議使用Medium模式得到相對較優的性能與質量。隨著參數的變化,PSNR與圖像的整體細節會出現較明顯變化。
Source Code主要有以下兩種途徑:可以從FFmpeg上直接clone,也可以訪問Intel的Github獲得相應源代碼。Intel的github上的分支中的FFmpeg qsv模塊是經過Intel的測試,相對而言問題更少運行更加穩定,大家也可以在Intel的Github上提出相關問題,我們會對部分問題進行解答。
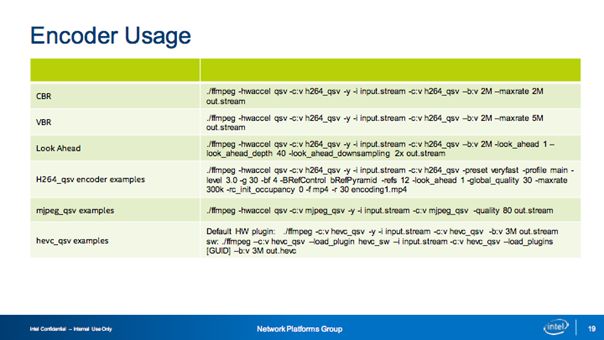
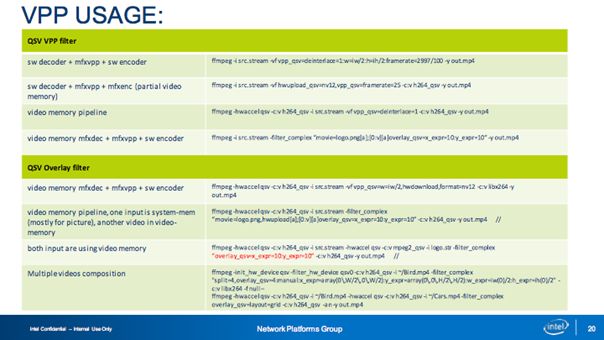

上圖展示的是實踐中可能需要的一些使用命令參考,其中我想強調的是Overlay Filter,在這里我們支持多種模式,包括插入臺標的、電視墻等,也可在視頻會議等場景中實現人工指定確定畫面中每一個圖片的位置等效果。
-
英特爾
+關注
關注
61文章
10009瀏覽量
172344 -
gpu
+關注
關注
28文章
4777瀏覽量
129362
原文標題:英特爾QSV技術在FFmpeg中的實現與使用
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英特爾與Stellantis Motorsports攜手推進自適應控制技術
英特爾推出全新英特爾銳炫B系列顯卡

使用PyTorch在英特爾獨立顯卡上訓練模型
英特爾IT的發展現狀和創新動向
回溯英特爾在跨越半個世紀的發展歷程
英特爾是如何實現玻璃基板的?
英特爾OCI芯粒在新興AI基礎設施中實現光學I/O(輸入/輸出)共封裝
英特爾實現光學IO芯粒的完全集成

英特爾CEO:AI時代英特爾動力不減
英特爾宣布代工虧損70億美元

英特爾首推面向AI時代的系統級代工
英特爾首推面向AI時代的系統級代工—英特爾代工






 工商網監
工商網監
評論