") 自然語言處理的ELMO使用
自然語言處理的ELMO使用
1、概述
word embedding 是現(xiàn)在自然語言處理中最常用的 word representation 的方法,常用的word embedding 是word2vec的方法,然而word2vec本質(zhì)上是一個(gè)靜態(tài)模型,也就是說利用word2vec訓(xùn)練完每個(gè)詞之后,詞的表示就固定了,之后使用的時(shí)候,無論新句子上下文的信息是什么,這個(gè)詞的word embedding 都不會(huì)跟隨上下文的場(chǎng)景發(fā)生變化,這種情況對(duì)于多義詞是非常不友好的。例如英文中的 Bank這個(gè)單詞,既有河岸的意思,又有銀行的意思,但是在利用word2vec進(jìn)行word embedding 預(yù)訓(xùn)練的時(shí)候會(huì)獲得一個(gè)混合多種語義的固定向量表示。即使在根據(jù)上下文的信息能明顯知道是“銀行”的情況下,它對(duì)應(yīng)的word embedding的內(nèi)容也不會(huì)發(fā)生改變。
ELMO的提出就是為了解決這種語境問題,動(dòng)態(tài)的去更新詞的word embedding。ELMO的本質(zhì)思想是:事先用語言模型在一個(gè)大的語料庫(kù)上學(xué)習(xí)好詞的word embedding,但此時(shí)的多義詞仍然無法區(qū)分,不過沒關(guān)系,我們接著用我們的訓(xùn)練數(shù)據(jù)(去除標(biāo)簽)來fine-tuning 預(yù)訓(xùn)練好的ELMO 模型。作者將這種稱為domain transfer。這樣利用我們訓(xùn)練數(shù)據(jù)的上下文信息就可以獲得詞在當(dāng)前語境下的word embedding。作者給出了ELMO 和Glove的對(duì)比
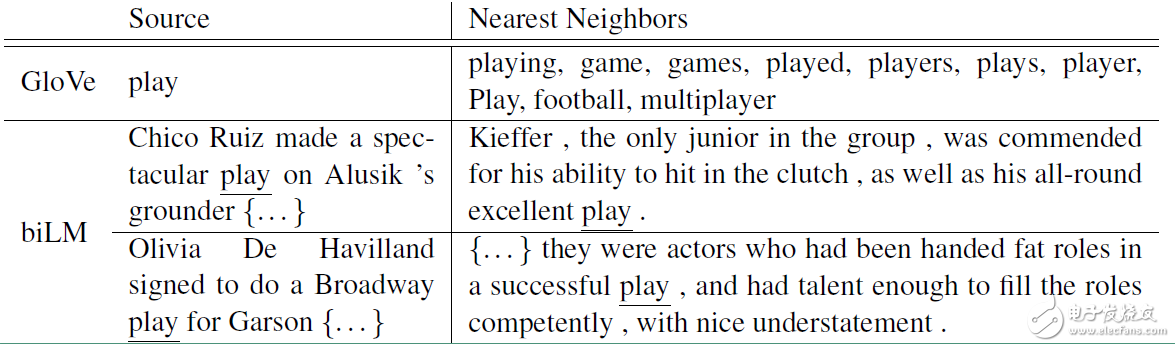
對(duì)于Glove訓(xùn)練出來的word embedding來說,多義詞play,根據(jù)他的embedding 找出的最接近的其他單詞大多數(shù)幾種在體育領(lǐng)域,這主要是因?yàn)橛?xùn)練數(shù)據(jù)中包含play的句子大多數(shù)來源于體育領(lǐng)域,之后在其他語境下,play的embedding依然是和體育相關(guān)的。而使用ELMO,根據(jù)上下文動(dòng)態(tài)調(diào)整后的embedding不僅能夠找出對(duì)應(yīng)的“表演”相同的句子,還能保證找出的句子中的play對(duì)應(yīng)的詞性也是相同的。接下來看看ELMO是怎么實(shí)現(xiàn)這樣的結(jié)果的。
2、模型結(jié)構(gòu)
ELMO 基于語言模型的,確切的來說是一個(gè) Bidirectional language models,也是一個(gè) Bidirectional LSTM結(jié)構(gòu)。我們要做的是給定一個(gè)含有N個(gè)tokens的序列
t1, t2, ... , tN
其前向表示為:
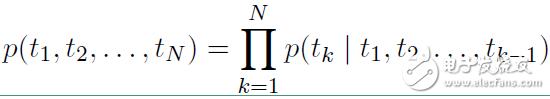
反向表示為:
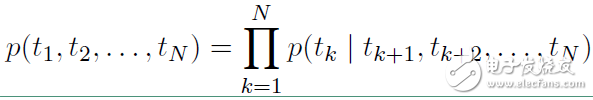
從上面的聯(lián)合概率來看是一個(gè)典型的語言模型,前向利用上文來預(yù)測(cè)下文,后向利用下文來預(yù)測(cè)上文。假設(shè)輸入的token是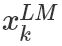 ,在每一個(gè)位置 k ,每一層LSTM 上都輸出相應(yīng)的context-dependent的表征
,在每一個(gè)位置 k ,每一層LSTM 上都輸出相應(yīng)的context-dependent的表征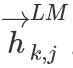 。
。
這里 j = 1 , 2 , ... , L ,L 表示LSTM的層數(shù)。頂層的LSTM 輸出,通過softmax層來預(yù)測(cè)下一個(gè)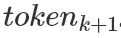 。
。
對(duì)數(shù)似然函數(shù)表示如下:
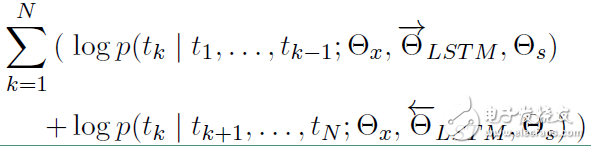
模型的結(jié)構(gòu)圖如下:
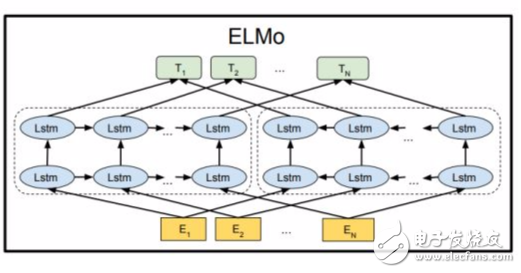
ELMO 模型不同于之前的其他模型只用最后一層的輸出值來作為word embedding的值,而是用所有層的輸出值的線性組合來表示word embedding的值。
對(duì)于每個(gè)token,一個(gè)L層的 biLM要計(jì)算出 2L + 1 個(gè)表征:
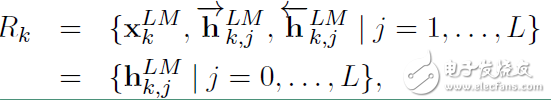
在上面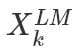 等于
等于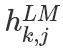 ,表示的是token層的值。
,表示的是token層的值。
在下游任務(wù)中會(huì)把 Rk壓縮成一個(gè)向量:
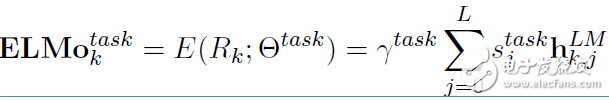
其中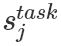 是softmax標(biāo)準(zhǔn)化權(quán)重,γtask?是縮放系數(shù),允許任務(wù)模型去縮放整個(gè)ELMO向量。
是softmax標(biāo)準(zhǔn)化權(quán)重,γtask?是縮放系數(shù),允許任務(wù)模型去縮放整個(gè)ELMO向量。
ELMO的使用主要有三步:
1)在大的語料庫(kù)上預(yù)訓(xùn)練 biLM 模型。模型由兩層bi-LSTM 組成,模型之間用residual connection 連接起來。而且作者認(rèn)為低層的bi-LSTM層能提取語料中的句法信息,高層的bi-LSTM能提取語料中的語義信息。
2)在我們的訓(xùn)練語料(去除標(biāo)簽),fine-tuning 預(yù)訓(xùn)練好的biLM 模型。這一步可以看作是biLM的domain transfer。
3)利用ELMO 產(chǎn)生的word embedding來作為任務(wù)的輸入,有時(shí)也可以即在輸入時(shí)加入,也在輸出時(shí)加入。
ELMO 在六項(xiàng)任務(wù)上取得了the state of the art ,包括問答,情感分析等任務(wù)。總的來說,ELMO提供了詞級(jí)別的動(dòng)態(tài)表示,能有效的捕捉語境信息,解決多義詞的問題。
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7536瀏覽量
88641 -
人工智能
+關(guān)注
關(guān)注
1796文章
47666瀏覽量
240288
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
python自然語言
【推薦體驗(yàn)】騰訊云自然語言處理
什么是自然語言處理?
自然語言處理常用模型解析

什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論