 Facebook出品的時序分析庫Prophet
Facebook出品的時序分析庫Prophet
編者按:Mail.Ru Search數據分析負責人Egor Polusmak介紹了Facebook出品的時序分析庫Prophet.
時序預測在數據分析中有廣泛應用,例如:
在線服務明年需要的服務器數量
指定日期超市的日用品需求量
可交易的金融資產明天的收盤價
有相當多預測未來趨勢的不同方法,例如,ARIMA、ARCH、回歸模型、神經網絡。
本文將介紹Prophet,Facebook在2017年2月23日開源的時序預測庫。我們也將用它預測Medium每天發表的文章數。
概覽
導言
Prophet預測模型
Prophet實踐
安裝
數據集
探索性可視分析
進行預測
預測質量評估
可視化
Box-Cox變換
總結
相關資源
導言
據Facebook研究院的文章所言,Prophet原本是為創建高質量的商業預測而研發的。Prophet嘗試處理許多商業時序數據中常見的困難:
人類行為導致的季節性效應:周、月、年循環,公共假期的峰谷;
新產品和市場事件導致的趨勢變動;
離群值。
據稱在許多情形下,默認配置的Prophet就可以生成媲美經驗豐富的分析師的預測。
此外,Prophet有一些直觀而易于解釋的定制功能,以供逐漸改善預測模型。特別重要的是,即使不是時序分析的專家,也可以理解這些參數。
據文章所言,Prophet的適用對象和場景很廣泛:
面向廣泛的分析師受眾,這些受眾可能在時序領域沒有很多經驗;
面向廣泛的預測問題;
自動估計大量預測的表現,包括標出可能的問題,以供分析師進一步調查。
Prophet預測模型
下面讓我們仔細看看Prophet是如何工作的。本質上,這個庫使用的是加性回歸模型:y(t) = g(t) + s(t) + h(t) + ?t
其中:
趨勢g(t)建模非周期性變動;
季節性s(t)建模周期性變動;
假日成分h(t)提供關于假日和事件的信息。
下面我們將討論這些模型成分的一些重要性質。
趨勢
Prophet庫實現兩種趨勢模型。
第一種是非線性飽和增長。它可以用邏輯增長模型表示:
其中:
C是承載量(曲線的最大值)
k是增長率(曲線的“陡峭程度”)
m是偏置參數
這一邏輯回歸等式可供建模非線性飽和增長,即數值的增長率隨增長而下降。一個典型的例子是應用或網站的用戶增長。
C和k實際上不一定是常量,可能隨著時間而發生變動。Prophet支持自動和手動調整這兩個參數,既可以通過擬合提供的歷史數據自行選擇最佳的趨勢改變點,也可以讓分析師手動指定增長率和承載量變動的時間點。
第二種趨勢模型是增長率恒定的簡單分段線性模型,最適合不存在飽和的線性增長。
季節性
周季節性通過虛擬變量建模:monday、tuesday、wednesday、thursday、friday、saturday(周一到周六)。這些變量的值為0還是為1取決于是星期幾。sunday(周日)變量沒有加入,因為上述六個變量都取0即可表示周日。相反,如果再引入周日變量,那么每個變量都可以通過另外六個變量的線性組合表示,這種變量之間的相關性會對模型產生不利影響。
年季節性通過傅里葉級數建模。
0.2版加入了新的日季節性特性,可以使用日以下尺度的時序數據并做出日以下尺度的預測。
假日和事件
h(t)表示每年的可預測反常日期,例如黑色星期五。
分析師需要提供定制的事件列表以利用這一特性。
誤差
最后的誤差項?t表示模型未反映的信息,通常建模為高斯噪聲。
Prophet評測
Facebook的論文(見相關資源)對比了Prophet和其他幾種時序預測方法。根據他們的研究,相比其他模型,Prophet顯著降低了預測誤差(使用平均絕對百分誤差測量預測精確度)。
為了便于理解上面的評測結果,下面簡單溫習下平均絕對百分誤差(MAPE)的概念。
將實際(歷史)值記為yi,模型給出的預測值記為?i。那么預測誤差ei= yi- ?i,相對預測誤差pi= ei/yi.
由此,我們定義MAPE = mean(|pi|)
MAPE廣泛用于測量預測精確性,因為它將誤差表示為百分比,因此可以用于不同數據集上的模型評估。
此外,評估預測算法時,為了了解誤差的絕對值,可以計算平均絕對誤差(MAE):MAE = mean(|ei|)
稍微講下和Prophet作對比的算法。大多數都相當簡單,經常用作基線:
naive是一個過度簡化的預測方法,僅僅根據上一時間點的觀測預測所有未來值。
snavie,類似naive,不過考慮了季節性因素。例如,在周季節性數據的情形下,用上周一的數據預測未來每周一的數據,用上周二的數據預測未來每周二的數據,以此類推。
mean,使用數據的平均值作為預測。
arima是自回歸集成移動平均的簡稱,參見第9課了解這一算法的細節。
ets是指數平滑的簡稱,參見第9課了解詳情。
Prophet實踐
安裝
首先安裝Prophet庫。Prophet支持Python和R語言。選擇哪種語言取決于個人偏好和項目需求。我們這里將使用Python。
Python下可以通過pip安裝:
pip install fbprophet
R也有對應的CRAN包。
引入所需模塊并初始化環境:
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
數據集
我們將預測Medium上每天發布的文章數。
首先載入數據集(數據集下載地址見文末):
df = pd.read_csv('../../data/medium_posts.csv', sep=' ')
接著,我們丟棄除了published(發布日期)和url(可以作為文章的唯一標識)之外的所有特征,順便移除可能存在的重復值和缺失值。
df = df[['published', 'url']].dropna().drop_duplicates()
接下來我們需要轉換published為時間日期格式,因為pandas默認視為字符串。
df['published'] = pd.to_datetime(df['published'])
根據時間排序dataframe,然后查看前三條記錄。
df.sort_values(by=['published']).head(n=3)
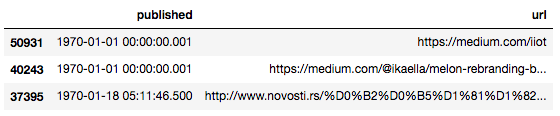
Medium是從2012年8月15日起開放的。然而,如你所見,至少有一些行的發布日期更早,這些極可能是不合法的。我們將清洗時序數據,限制一下時間范圍:
df = df[(df['published'] > '2012-08-15') &
(df['published'] < '2017-06-26')].
sort_values(by=['published'])
df.head(n=3)

最后3條:
df.tail(n=3)

由于需要預測發布文章數,我們將聚合、計數給定時間點的不同文章數。我們將相應的新增列命名為posts(帖子):
aggr_df = df.groupby('published')[['url']].count()
aggr_df.columns = ['posts']
實踐中我們感興趣的是一天發布的文章數,但是當前數據屬于日尺度以下的時序:
aggr_df.head(n=3)
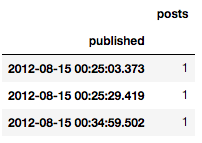
為了修正這一點,我們需要根據時間“箱”聚合文章數。在時序分析中,這一過程稱為重采樣。并且,如果我們降低了數據的采樣率,那么這稱為降采樣。
幸運的是,pandas內置這一功能:
daily_df = aggr_df.resample('D').apply(sum)
daily_df.head(n=3)
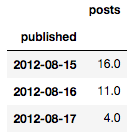
探索性可視分析
一般來說,查看數據的圖形表示可能提供幫助和指引。我們將在整個時間區間上創建時序圖,這可能提供季節性和明顯的異常偏離的線索。
首先我們引入并初始化Plotly庫,以創建美觀的交互圖:
from plotly.offline import init_notebook_mode, iplot
from plotly import graph_objs as go
# 初始化plotly
init_notebook_mode(connected=True)
我們還將定義一個用于繪圖的幫助函數:
def plotly_df(df, title=''):
"""可視化dataframe所有列為線圖。"""
common_kw = dict(x=df.index, mode='lines')
data = [go.Scatter(y=df[c], name=c, **common_kw) for c in df.columns]
layout = dict(title=title)
fig = dict(data=data, layout=layout)
iplot(fig, show_link=False)
讓我們試著直接繪制數據集:
plotly_df(daily_df, title='Posts on Medium (daily)')
即使Plotly提供了縮放功能,這樣的高頻數據仍舊很難分析。除了明顯的增長和加速趨勢外,很難從這樣的圖形中推斷出什么有意義的結論。
為了減少噪聲,我們將按周重采樣文章數。順便提下,分箱之外,其他降噪的技術還包括移動平均平滑和指數平滑等。
我們將降采樣的dataframe保存到另一個變量中,因為之后我們將按日處理數據:
weekly_df = daily_df.resample('W').apply(sum)
plotly_df(weekly_df, title='Posts on Medium (weekly)')
從幫助分析師預測的角度來說,這張圖的效果更好。
Plotly提供的最有用的功能之一是快速深入不同時間段,這有助于更好地理解數據以及找到關于可能的趨勢、周期性、反常效應的線索。
例如,放大連續幾年會顯示對應基督教節日的時間點,這些對人類行為有重大影響。
根據上圖,我們將省略2015年之前的觀測。頭幾年每天發布的文章數很低,可能給預測增加噪聲,因為模型可能不得不擬合這些異常的歷史數據而不能更好地利用最近幾年更相關、更具指示性的數據。
daily_df = daily_df.loc[daily_df.index >= '2015-01-01']
daily_df.head(n=3)
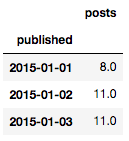
基于可視化分析,我們可以看到我們的數據集呈現出一個顯著的不斷增長的趨勢。同時也展示了周積極性和年季節性,還有每年中的一些異常日期。
進行預測
Prophet的API和sklearn很相似。首先創建一個模型,接著調用fit方法,最后做出預測。fit方法的輸入是一個包含兩列的DataFrame:
ds(datestamp),類型必須是date或datetime。
y是想要預測的數值。
我們先引入庫并關閉不重要的診斷信息:
from fbprophet importProphet
import logging
logging.getLogger().setLevel(logging.ERROR)
轉換dataframe至Prophet要求的格式:
df = daily_df.reset_index()
df.columns = ['ds', 'y']
df.tail(n=3)
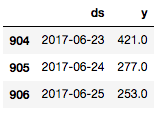
Prophet的作者建議至少根據幾個月的數據進行預測,如果有超過一年的歷史數據就最理想了。很幸運,我們這里有好幾年的數據可供模型擬合。
為了測量預測的質量,我們需要將數據集分為歷史部分(數據的前部,也是最大部分)和預測部分(時間線的最后部分)。我們從數據集中移除最后一個月的數據,作為測試目標:
prediction_size = 30
train_df = df[:-prediction_size]
train_df.tail(n=3)
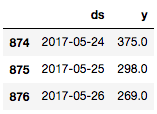
現在我們需要創建一個新的Prophet對象(模型),我們可以傳入模型的參數,但是這里我們將使用默認值。接著在訓練數據集上調用fit方法訓練模型。
m = Prophet()
m.fit(train_df);
然后我們使用輔助函數Prophet.make_future_dataframe創建一個dataframe,其中包括所有歷史日期,以及之前留置的未來30天。
future = m.make_future_dataframe(periods=prediction_size)
future.tail(n=3)

調用predict方法,傳入我們想要創建預測的日期后就可以預測新值了。如果像這里一樣同時提供歷史數據,那除了預測之外我們還能得到歷史的內擬合。
forecast = m.predict(future)
forecast.tail(n=3)

在結果dataframe中,我們可以看到很多描繪預測的列,包括趨勢成分、季節性成分,還有它們的置信區間。預測本身存儲于yhat列。
Prophet庫內置可視化工具,方便迅速評估結果。
首先,Prophet.plot方法可以繪制所有預測的數據點:
m.plot(forecast);
這張圖沒有提供多少信息。我們唯一能得出的結論是模型將許多數據點視為離群值。
在我們的情形中,Prophet.plot_components函數也許要有用得多。它讓我們可以分別觀察模型的不同成分:趨勢、年季節性、周季節性。如果給模型提供了關于假日和事件的信息,圖形也會顯示相關信息。
m.plot_components(forecast);
從趨勢圖中,我們可以看到,Prophet很好地擬合了2016年末后的加速增長趨勢。從周季節性圖中,我們可以得出結論,和工作日相比,周六、周日的新文章較少。而年季節性圖清楚地顯示了圣誕節那一天的迅猛下跌。
預測質量評估
讓我們計算預測的最后30天的誤差測度,以便評估算法的質量。為此,我們需要觀測yi和相應的預測值?i。
看下Prophet為我們創建的forecast對象:
print(', '.join(forecast.columns))
結果:
ds, trend, trend_lower, trend_upper, yhat_lower, yhat_upper, seasonal, seasonal_lower, seasonal_upper, seasonalities, seasonalities_lower, seasonalities_upper, weekly, weekly_lower, weekly_upper, yearly, yearly_lower, yearly_upper, yhat
我們看到,其中沒有歷史值。我們需要從原數據集df中獲取實際值y,然后和forecast對象中的預測值比較。為此我們定義一個輔助函數:
def make_comparison_dataframe(historical, forecast):
return forecast.set_index('ds')[['yhat', 'yhat_lower', 'yhat_upper']].join(historical.set_index('ds'))
應用這一函數:
cmp_df = make_comparison_dataframe(df, forecast)
cmp_df.tail(n=3)
我們再定義一個計算MAPE和MAE的輔助函數:
def calculate_forecast_errors(df, prediction_size):
df = df.copy()
df['e'] = df['y'] - df['yhat']
df['p'] = 100 * df['e'] / df['y']
predicted_part = df[-prediction_size:]
error_mean = lambda error_name: np.mean(np.abs(predicted_part[error_name]))
return {'MAPE': error_mean('p'), 'MAE': error_mean('e')}
然后用它計算MAPE和MAE:
for err_name, err_value in
calculate_forecast_errors(cmp_df, prediction_size).items():
print(err_name, err_value)
結果:
MAPE 22.7243579814
MAE 70.452857085
可視化
現在讓我們自行可視化Prophet創建的模型。它將包括實際值、預測值和置信區間。
首先,我們繪制較短時期內的圖形,這樣數據點更容易分辨。接著,我們只顯示模型在預測期間內的表現(最后30天)。這兩個測度看起來能帶來更清晰的圖形。
最后,我們將使用Plotly讓圖形可以交互,這對探索很重要。
我們將定義一個輔助函數show_forecast并調用它:
def show_forecast(cmp_df, num_predictions, num_values, title):
def create_go(name, column, num, **kwargs):
points = cmp_df.tail(num)
args = dict(name=name, x=points.index, y=points[column], mode='lines')
args.update(kwargs)
return go.Scatter(**args)
lower_bound = create_go('Lower Bound', 'yhat_lower', num_predictions,
line=dict(width=0),
marker=dict(color="444"))
upper_bound = create_go('Upper Bound', 'yhat_upper', num_predictions,
line=dict(width=0),
marker=dict(color="444"),
fillcolor='rgba(68, 68, 68, 0.3)',
fill='tonexty')
forecast = create_go('Forecast', 'yhat', num_predictions,
line=dict(color='rgb(31, 119, 180)'))
actual = create_go('Actual', 'y', num_values,
marker=dict(color="red"))
data = [lower_bound, upper_bound, forecast, actual]
layout = go.Layout(yaxis=dict(title='Posts'), title=title, showlegend = False)
fig = go.Figure(data=data, layout=layout)
iplot(fig, show_link=False)
show_forecast(cmp_df, prediction_size, 100, 'New posts on Medium')
初看起來模型預測的均值還挺合理的。從圖上看,之所以之前算出來的MAPE值比較高,可能是因為模型沒能捕捉周季節性增長高峰的放大效應。
我們還可以從圖中得出的結論是,許多實際值位于置信區間之外。Prophet也許不太適合方差不穩定的時序,至少在默認設置下是如此。我們將通過轉換數據來嘗試修正這一點。
Box-Cox變換
目前為止,我們使用的都是Prophet的默認設置,數據也基本上是原始數據。我們這里不打算討論如何調整模型的參數,不過,即使在不動默認參數的情況下,還是有提升的空間。在這一節,我們將在原始時序上應用Box-Cox變換,看看會有什么效果。
簡單介紹下這一變換。這一單調數據變換可以穩定方差。我們將使用單參數Box-Cox變換:
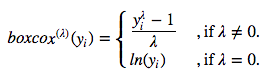
使用上式的逆函數可以還原至原數據的尺度:
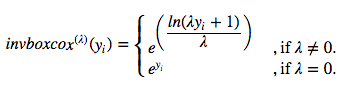
相應的Python函數:
def inverse_boxcox(y, lambda_):
return np.exp(y) if lambda_ == 0else np.exp(np.log(lambda_ * y + 1) / lambda_)
首先,我們準備數據,設置索引:
train_df2 = train_df.copy().set_index('ds')
接著,我們應用Scipy的stats.boxcox函數(Box-Cox變換)。這里它將返回兩個值,第一個值是轉換后的序列,第二個值是找到的最優λ值(最大似然):
train_df2['y'], lambda_prophet = stats.boxcox(train_df2['y'])
train_df2.reset_index(inplace=True)
創建一個新Prophet模型,并重復之前的擬合-預測流程:
m2 = Prophet()
m2.fit(train_df2)
future2 = m2.make_future_dataframe(periods=prediction_size)
forecast2 = m2.predict(future2)
然后通過逆函數和已知的λ值反轉Box-Cox變換:
for column in ['yhat', 'yhat_lower', 'yhat_upper']:
forecast2[column] = inverse_boxcox(forecast2[column],
lambda_prophet)
復用之前創建對比dataframe和計算誤差的代碼:
cmp_df2 = make_comparison_dataframe(df, forecast2)
for err_name, err_value in calculate_forecast_errors(cmp_df2, prediction_size).items():
print(err_name, err_value)
結果:
MAPE 11.5921879552
MAE 39.072031256
毫無疑問,模型的質量提升了。
最后,讓我們繪制最新結果的可視化圖形,和之前的放一起對比下。
show_forecast(cmp_df, prediction_size, 100, 'No transformations')
show_forecast(cmp_df2, prediction_size, 100, 'Box–Cox transformation')
轉換前
轉換后
很明顯,第二張圖中的預測值更加接近真實值。
總結
我們介紹了Prophet這一開源的時序預測庫,并進行了一些時序預測的實踐。
如我們所見,Prophet并不神奇,開箱即用的預測并不理想。它仍然需要數據科學家在必要的時候探索預測結果,調整模型參數,轉換數據。
不過,這一個用戶友好、易于定制的庫。在某些情形下,單單將分析師事先知道的異常日期納入考慮這一功能就會帶來很大的不同。
總的來說,Prophet庫值得收入你的分析工具箱。
相關資源
GitHub上的Prophet官方倉庫:https://github.com/facebook/prophet
Prophet官方文檔:https://facebookincubator.github.io/prophet/docs/quick_start.html
Sean J. Taylor和Benjamin Letham的論文Forecasting at scale解釋了作為Prophet基礎的算法。
Chris Moffitt寫的Prophet概覽(以預測網站流量為例):http://pbpython.com/prophet-overview.html
Rob J. Hyndman和George Athanasopoulos寫的Forecasting: principles and practice——很好的關于時序預測的一本書(有在線版)
本文配套的Jupyter Notebook: git.io/fpslo
Medium數據集:https://drive.google.com/file/d/1G3YjM6mR32iPnQ6O3f6rE9BVbhiTiLyU/view
課程回顧
機器學習開放課程系列至此告一段落,所以這里列下之前的十課:
Pandas探索性分析
可視化
分類、決策樹、K近鄰
線性分類、線性回歸
Bagging、隨機森林
特征工程
PCA、聚類
Vowpal Wabbit
時序數據
梯度提升
配套視頻(目前更新到第6課):https://youtu.be/QKTuw4PNOsU
連喵星人也被課程吸引(來源:Yulia Kameneva)
配套Kaggle競賽:
基于網頁會話檢測惡意用戶:https://www.kaggle.com/c/catch-me-if-you-can-intruder-detection-through-webpage-session-tracking2
預測Medium文章推薦數:https://www.kaggle.com/c/how-good-is-your-medium-article/
-
Facebook
+關注
關注
3文章
1429瀏覽量
55001 -
數據集
+關注
關注
4文章
1209瀏覽量
24835
原文標題:機器學習開放課程(終):基于Facebook Prophet預測未來
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Facebook背后的軟件揭秘
時序分析基本概念介紹——時序庫Lib,除了這些你還想知道什么?

區塊鏈移動社交類預測平臺“Prophet Set”可為用戶提供不同類型的預測事件
時序基礎分析

超過4.19億的Facebook用戶ID電話信息被泄露,數據庫已被刪除
正點原子FPGA靜態時序分析與時序約束教程







 工商網監
工商網監
評論