 扇貝是如何實現深度追蹤模型并運用到英語學習者詞匯水平評估中去
扇貝是如何實現深度追蹤模型并運用到英語學習者詞匯水平評估中去
背景
扇貝,作為一個擁有超過八千萬用戶的移動英語學習平臺,一直在探索如何利用數據來提供更精準的個性化教育。更快速、科學地評估用戶詞匯水平,不僅可以有效提高用戶的學習效率,也可以幫助我們為每位用戶制定更個性化的學習內容。
我們通過應用 TensorFlow,在深度知識追蹤系統上可以實時地預測用戶對詞表上每個詞回答正確的概率 (如圖 1 所示)。本文將介紹扇貝是如何實現深度追蹤模型并運用到英語學習者詞匯水平評估中去。
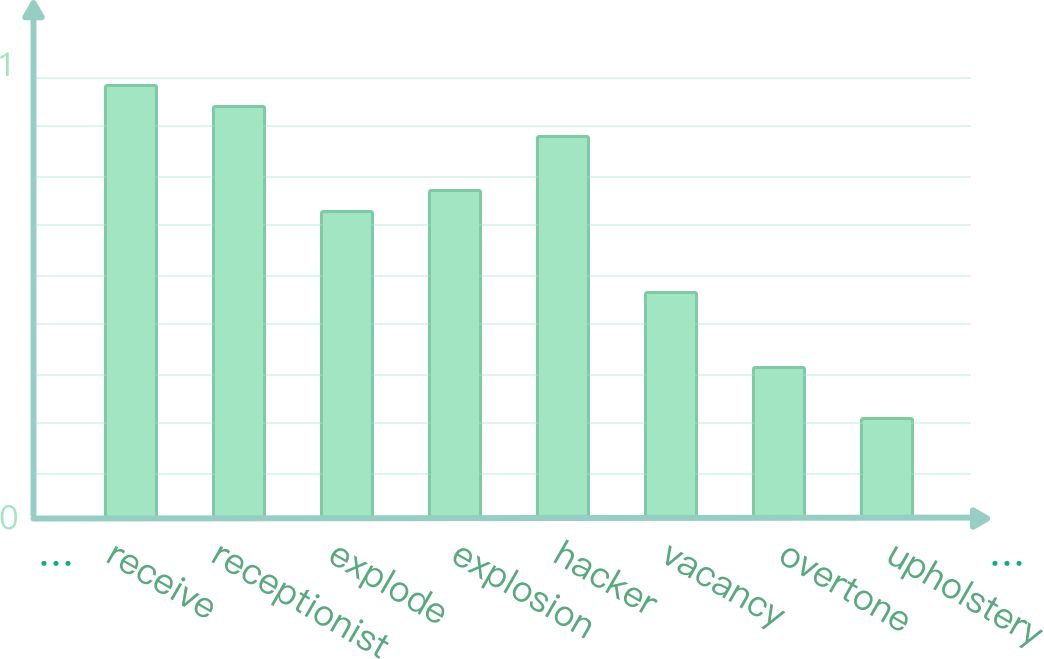
圖 1:實時預測答詞正確率
模型介紹
基于先前大量線上詞匯量測試記錄,我們的總序列數量已經累積到千萬級別,這為使用深度學習模型提供了堅實的基礎。模型方面,我們選用了斯坦福大學 Piech Chris 等人在 NIPS 2015 發表的 Deep Knowledge Tracing (DKT) 模型 [1],該模型在 Khan Academy Data 上進行了驗證,有著比傳統 BKT 模型更好的效果。由表 1 可見,相比 Khan Academy Data,扇貝詞匯量測試數據的題目數量和所涉及用戶量都要更大,序列長度也更長,這些不同也是我們在模型調優過程中面臨的最大挑戰。
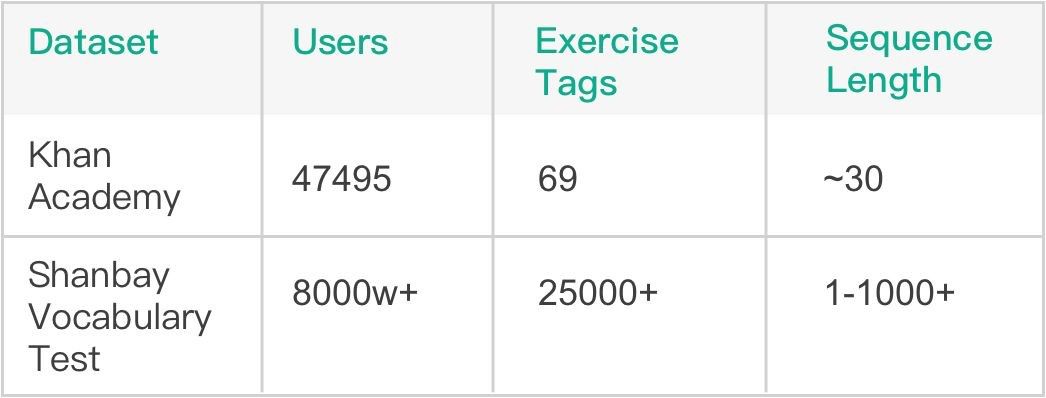
表 1:Khan Math 和 Shanbay Vocab 數據對比
Baseline 模型結構為單層 LSTM ,如圖 2 所示,輸入 xt 是用戶當前 action(所答單詞和正確與否)的 embedding,可以用 one-hot encodings 或者是 compressed representations。輸出 yt 代表模型預測用戶對詞表中每個詞回答正確的概率。
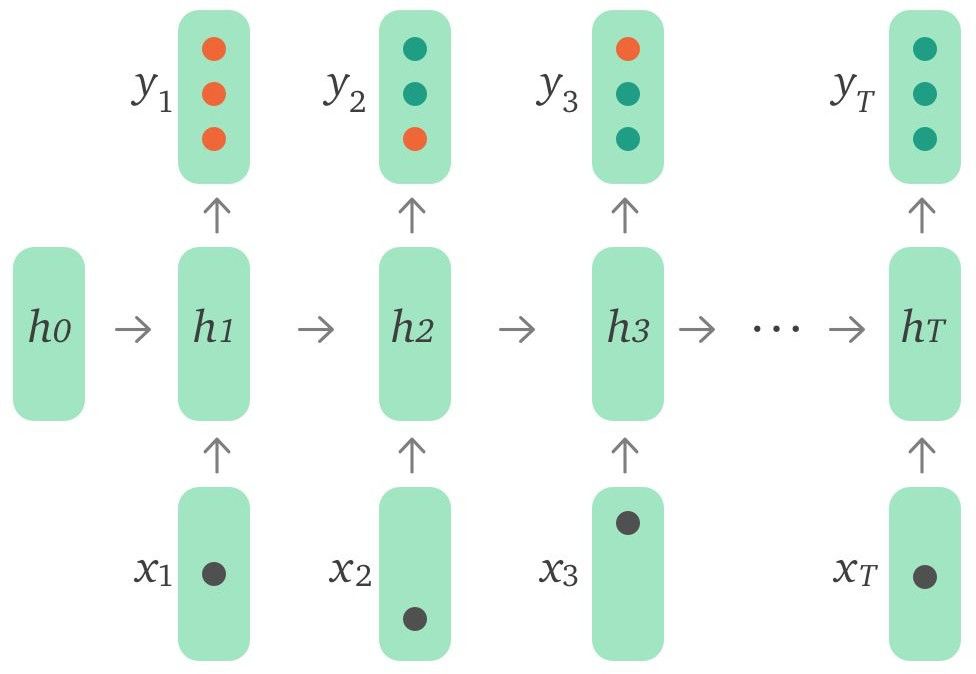
圖 2:DKT 模型結構
模型改進
按照原論文思路實現的 baseline ,在 Khan Academy Data 上能較好地復現論文結果。針對實際應用場景,我們使用 TensorFlow 實現了相應模型,在如下幾方面做出改進,嘗試提升模型性能。
數據預處理
通過觀察發現,原始數據存在如下幾個問題:
少量異常用戶數據占比過高
部分用戶測試序列過短,提供的信息不足
存在少量極低頻詞
經過數據清洗后,模型準確率有 1.3% 左右的提升。
引入外部特征
DKT 原模型的輸入只有當前題目和用戶回答正確與否,事實上用戶答題過程中相關的一些其他信息也是可以作為特征輸入到模型中的。下面列出了其中一些有代表性的特征:
Time - 用戶第一次遇到該單詞時回答所花費的時間
Attempt count - 用戶第幾次遇到該單詞
First action - 用戶的第一個動作是直接回答還是求助系統給出提示信息
Word level - 先驗單詞等級
使用這些特征的方式有多種,可以通過自編碼器編碼后輸入,也可以作為特征向量與 input embeddings 拼接后輸入,還可以直接和 LSTM 輸出的 hidden state 拼接后進行預測。這些特征的使用進一步將模型準確率提升了約 2.1%。我們還對不同特征能夠帶來的影響進行了對比實驗,發現 Time 和 Attempt count 是最重要的兩個特征維度,而其他特征帶來的影響則很有限。
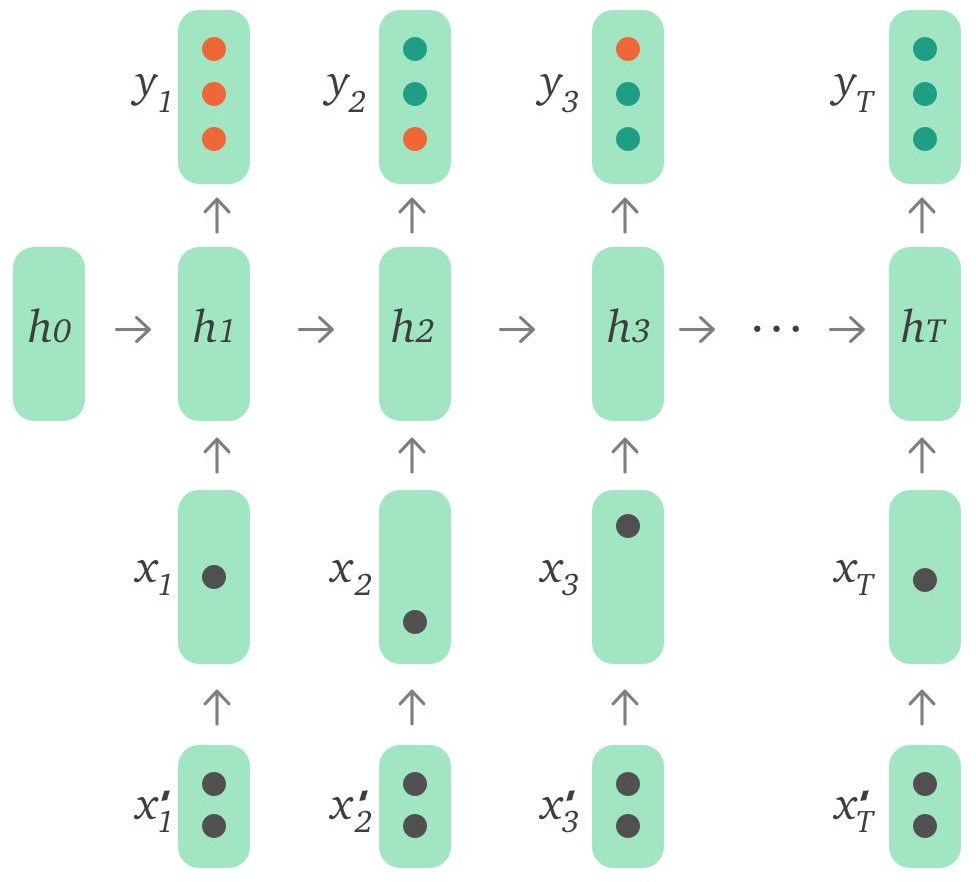
圖 3:引入外部特征的 DKT 模型
長序列依賴
傳統 LSTM 模型使用了門控函數,雖然有效緩解了梯度消失問題,但面對超長序列的時候仍然無法避免。此外,由于使用了 tanh 函數,在多層 LSTM 中,層與層之間的梯度消失問題依然存在。所以現階段多層 LSTM 大多是采用 2~3 層,最多不超過 4 層。為了解決數據中存在的超長序列長期依賴問題,我們選用了 Shuai Li 等人在 CVPR 2018 發表的 Independently Recurrent Neural Network (IndRNN) 模型 [2]。 IndRNN 將層內神經元解耦,讓它們相互獨立,同時使用 ReLU 激活函數,有效解決了層內以及層間的梯度消失和爆炸問題,使得模型層數和能夠學習到的序列長度大大增加。如圖 4 所示,對于 Adding Problem (評價 RNN 模型的典型問題),當序列長度到達 1000 時, LSTM 已經無法降低均方誤差,而 IndRNN 仍然可以快速地收斂到一個非常小的誤差。
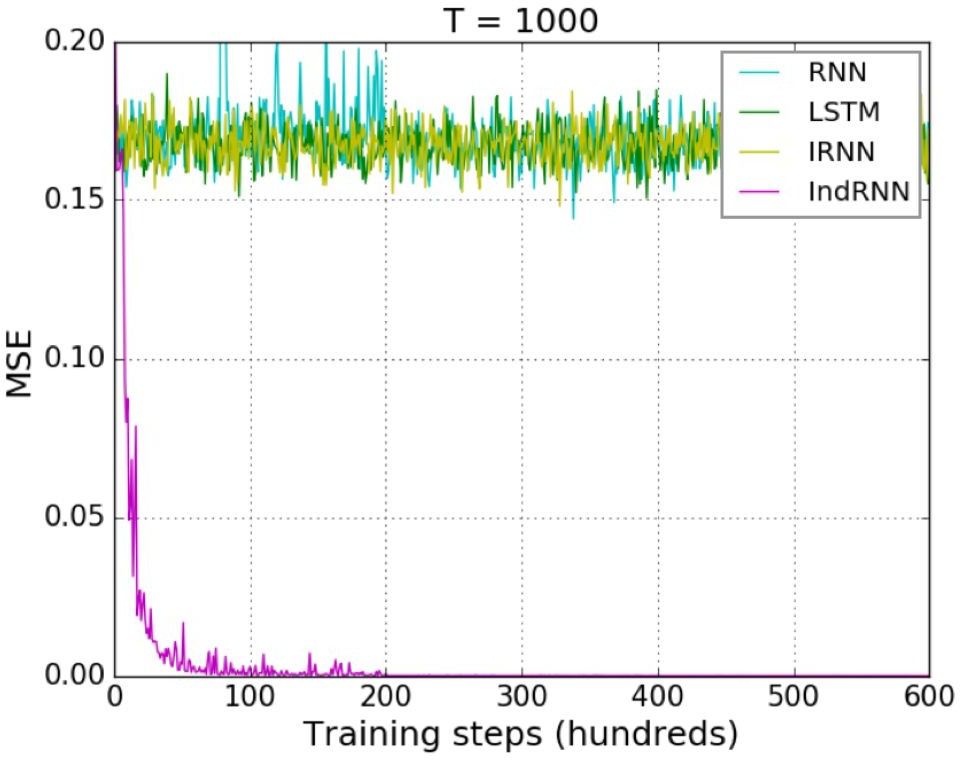
圖 4:對 Adding Problem,各種 RNN 對長序列的收斂情況對比
IndRNN 的引入,有效地解決了數據中超長序列長期依賴問題,進一步將模型準確率提升了 1.2%。
超參數調優
在手動調參的模型已經得到了不錯表現的基礎上,我們希望通過自動調參來進一步優化模型。可調整的一些參數有:
RNN 結構類型 - LSTM,GRU,IndRNN
RNN 層數和連接方式
學習率和 Decay 步數
Input 和 RNN 維度
Dropout 大小
在自動調參算法中,Grid Search(網格搜索)、Random Search(隨機搜索)和 Bayesian Optimization(貝葉斯優化)[3] 較為主流。網格搜索的問題在于容易遭遇維度災難,而隨機搜索則不能利用先驗知識來更好地選擇下一組超參數,只有貝葉斯優化是 “很可能” 比建模工程師調參能力更好的算法。因為它能利用先驗知識高效地調節超參數。貝葉斯優化方法在目標函數未知且計算復雜度高的情況下很強大,該算法的基本思想是基于采樣數據使用貝葉斯定理估計目標函數的后驗分布,然后再根據分布選擇下一個采樣的超參數組合。
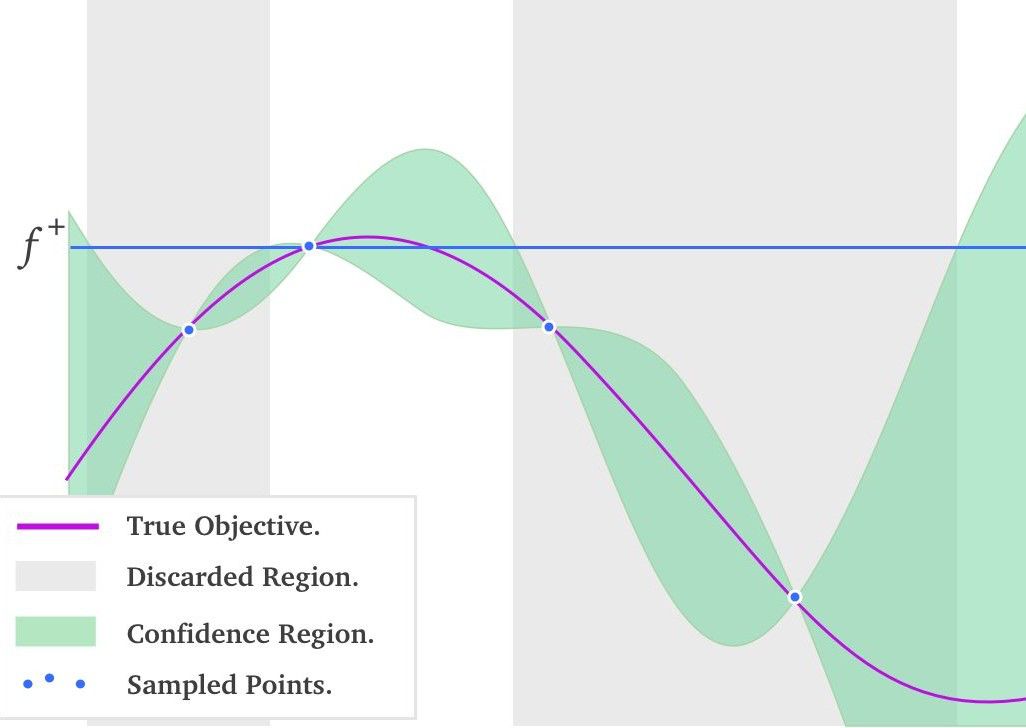
圖 5:一維黑盒函數的貝葉斯優化過程
圖 5 中紅線代表真實的黑盒函數分布,綠色區域代表根據已采樣點計算出的各位置處的置信區間。此刻要做的事情就是選擇下一個采樣點,選擇均值大稱為 exploitation,選擇方差大稱為 exploration。均值大的點會更有把握獲得更優的解,而方差更大的點會更有機會得到全局最優。所以如何決定 exploitation 和 exploration 比例,是需要根據使用場景決定的。發揮這個功能的是一個叫做 acquisition function 的函數,它被用來權衡 exploitation 和 exploration 。常用的 acquisition function 有 Upper Condence Bound, Expected Improvement, Entropy Search 等。有了 acquisition function 后,就能以它取得最大值處的超參數,作為貝葉斯優化算法推薦的下一個超參數值。這個結果是根據超參數間的聯合概率分布求出來,并且均衡了 exploritation 和 exploration 后得到的結果。
使用了貝葉斯優化調參后,模型的準確率進一步提升了 1.7%。
模型部署
我們使用 TensorFlow Serving 作為模型部署上線的方案。在上線前我們有利用一些模型壓縮技術來減少模型大小,并根據 TensorFlow Serving Batching Guide [4] 來找到最優的 batching config 參數。
模型壓縮
模型壓縮有很多種方式,參數共享和剪枝、參數量化、低秩分解等。從簡單易行的角度考慮,我們借鑒了 LSTMP [5] 中 projection layer 的思想,對最終輸出層的 embedding matrix 進行了分解,增加了一個 projection layer。這么做的原因在于模型最終輸出詞表維度很大,因此模型大部分參數都集中在輸出層。分解后模型大小減少到原來的一半,而模型準確率卻沒有損失。
此外,DKT 模型的 hidden state 對于每個用戶而言是不同的,所以基于長期學習需求,我們需要為每位用戶保存這個向量來作為 user embedding。但如果這個向量維度較大的話,面對大量潛在用戶,存儲壓力是非常大的,所以我們嘗試著去降低這個向量維度。起初的方案是使用 LSTMP,但實驗發現,直接降低這個維度對模型準確率損害是很低的。將維度降低到 baseline 模型的五分之一,對準確率幾乎沒有負面影響,這個結果也超出了我們的預期。
TensorFlow Serving Batching 調優
根據官方 performance tuning guide,對于線上預測系統,我們將 num_batch_threads 設為 CPU 的核心數量,max_batch_size 設為一個很大的值,同時 batch_timeout_micros 設為 0 . 隨后在 1~10millisecond 范圍內調整 batch_timeout_micros,找到最優配置。經過測試發現,在同樣的計算資源下,使用調優過后的 Batching config,并發量是不使用時候的 2~2.5 倍。
總結和展望
本文以詞匯水平評估場景為例,介紹了 TensorFlow 在 Computer-Aided Language Learning(計算機輔助語言學習)中的應用。通過對一系列論文結果的復現、改進以及調優,成功將 DKT 模型上線,為數千萬用戶提供了更科學的詞匯測試方案。
后續我們會繼續探究如何將 DKT 模型更深入地應用到扇貝單詞的單詞學習場景中去。同時還會將單詞題拓展到更泛性的練習題上去,在更廣的領域,更多的視角上進行知識追蹤,從而更高效地幫助用戶進行英語學習。用 AI 給教育賦能,是扇貝不變的追求。
-
編碼器
+關注
關注
45文章
3667瀏覽量
135243 -
深度學習
+關注
關注
73文章
5513瀏覽量
121551 -
tensorflow
+關注
關注
13文章
329瀏覽量
60631
原文標題:扇貝 : 應用 TensorFlow 實現深度知識追蹤
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
分享15余年EMC設計經驗,讓學習者成為高規格設計師!
網絡環境的出現對于學習者的深遠影響
網絡環境中學習者新特征的具體分析
什么是深度學習?使用FPGA進行深度學習的好處?
基于深度學習模型的點云目標檢測及ROS實現
如何基于深度學習模型訓練實現圓檢測與圓心位置預測

如何基于深度學習模型訓練實現工件切割點位置預測






 工商網監
工商網監
評論