 如何在聲音頻譜嵌入中加入記憶機制
如何在聲音頻譜嵌入中加入記憶機制
編者按:Kanda機器學習工程師Daniel Rothmann撰寫的機器聽覺系列第四篇,講解如何在聲音頻譜嵌入中加入記憶機制。
歡迎回來!這一系列文章將詳細介紹奧胡斯大學和智能揚聲器生產商Dynaudio A/S合作開發的實時音頻信號處理框架。
如果你錯過了之前的文章,可以點擊下面的鏈接查看:
AI在音頻處理上的潛力
基于頻譜圖和CNN處理音頻有何問題?
基于自編碼器學習聲音嵌入表示
在上一篇文章中,我們介紹了人類是如何體驗聲音的,在耳蝸形成頻譜印象,接著由腦干核團“編碼”,并借鑒其思路,基于自編碼器學習聲音頻譜嵌入。在這篇文章中,我們將探索如何構建用來理解聲音的人工神經網絡,并在頻譜聲音嵌入生成中集成記憶。
余音記憶
聲音事件的含義,很大程度上源于頻譜特征間的時域相互關系。
有一個事實可以作為例證,取決于語音的時域上下文的不同,人類聽覺系統會以不同方式編碼同樣的音位1。這意味著,取決于之前的語音,音位/e/在神經方面可能意味著完全不同的東西。
進行聲音分析時,記憶很關鍵。因為只有在某處實際存儲了之前的印象,才可能將之前的印象與“此刻”的印象相比較。
人類的短期記憶組件既包括感官記憶也包括工作記憶2。人類對聲音的感知依靠聽覺感官記憶(有時稱為余音記憶)。C. Alain等將聽覺感官記憶描述為“聽覺感知的關鍵初始階段,使聽者可以整合傳入的聽覺信息和存儲的之前的聽覺事件的表示”2。
從計算的角度出發,我們可以將余音記憶視作即刻聽覺印象的短期緩沖區。
余音記憶的持續時間有所爭議。D. Massaro基于純音和語音元音掩碼的研究主張持續時間約為250毫秒,而A. Treisman則根據雙耳分聽試驗主張持續時間約為4秒3。從在神經網絡中借鑒余音記憶思路的角度出發,我們不必糾結感官存儲的余音記憶的固定時長。我們可以在神經網絡上測試幾秒鐘范圍內的記憶的效果。
進入循環
在數字化頻譜表示中可以相當直截了當地實現感官記憶。我們可以簡單地分配一個環形緩沖區用來儲存之前時步的頻譜,儲存頻譜的數量預先定義。

環形緩沖區是一種數據結構,其中包含一個視作環形的數組,窮盡數組長度后索引循環往復為04.
在我們的例子中,可以使用一個長度由所需記憶量決定的多維數組,環形緩沖區的每個索引指向某一特定時步的完整頻率頻譜。計算出新頻譜后,將其寫入緩沖區,如果緩沖區已滿,就覆蓋最舊的時步。
在填充緩沖區的過程中,我們會更新兩個指針:標記最新加入元素的尾指針,和標記最舊元素的頭指針(即緩沖區的開始)4。
下面是一個環形緩沖區的Python實現的例子(作者為Eric Wieser):
class CircularBuffer(): # 初始化NumPy數組和頭/尾指針 def __init__(self, capacity, dtype=float): self._buffer = np.zeros(capacity, dtype) self._head_index = 0 self._tail_index = 0 self._capacity = capacity # 確保頭指針和尾指針循環往復 def fix_indices(self): if self._head_index >= self._capacity: self._head_index -= self._capacity self._tail_index -= self._capacity elif self._head_index < 0: ? ? ? ? ? ?self._head_index += self._capacity ? ? ? ? ? ?self._tail_index += self._capacity ? ?# 在緩沖區中插入新值,如緩沖區已滿,覆蓋舊值 ? ?def insert(self, value): ? ? ? ?if self.is_full(): ? ? ? ? ? ?self._head_index += 1 ? ? ? ?self._buffer[self._tail_index % self._capacity] = value ? ? ? ?self._tail_index += 1 ? ? ? ?self.fix_indices()
降低輸入尺寸
為了存儲一整秒的頻率頻譜(每時步5毫秒),我們需要一個包含200個元素的緩沖區,其中每個元素包含頻率幅度的數組。如果我們需要類人的頻譜解析度,這些數組將包含3500個值。然后200個時步就需要處理700000個值。
將長度為700000的輸入傳給人工神經網絡,在算力上太昂貴了。降低頻譜和時域解析度,或者保存更短時期的頻譜信息,可以緩解這一問題。
我們也可以借鑒Wavenet架構,使用空洞因果卷積(dilated causal convolutions)以優化原始音頻樣本中的大量序列數據的分析。如A. Van Den Oord等所言,空洞卷積是應用于大于自身長度的區域,以特定步驟跳過輸入值的過濾器5。
最近傳入的頻率數據在瞬時聲音分析中起決定性作用,根據這一假定,我們可以用空洞頻譜緩沖區來降低算力記憶的大小。
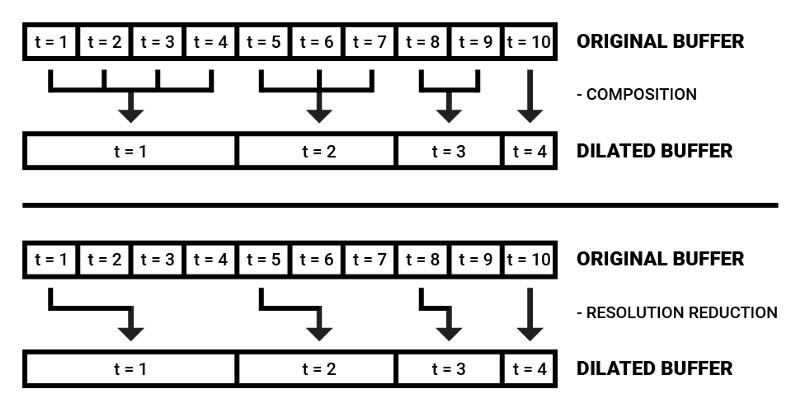
空洞緩沖區的值可以直接選擇單個值,也可以組合若干時步,提取平均數或中位數。
空洞頻譜緩沖區背后的動機是在記憶中保留最近的頻譜印象的同時,以高效的方式同時保持關于上下文的部分信息。
下面是使用Gammatone濾波器組構造空洞頻譜的代碼片段。注意這里使用的是離線處理,不過濾波器組也同樣可以實時應用,在環形緩沖區中插入頻譜幀。
from gammatone import gtgramimport numpy as npclass GammatoneFilterbank: def __init__(self, sample_rate, window_time, hop_time, num_filters, cutoff_low): self.sample_rate = sample_rate self.window_time = window_time self.hop_time = hop_time self.num_filters = num_filters self.cutoff_low = cutoff_low def make_spectrogram(self, audio_samples): return gtgram.gtgram(audio_samples, self.sample_rate, self.window_time, self.hop_time, self.num_filters, self.cutoff_low) def make_dilated_spectral_frames(self, audio_samples, num_frames, dilation_factor): spectrogram = self.make_spectrogram(audio_samples) spectrogram = np.swapaxes(spectrogram, 0, 1) dilated_frames = np.zeros((len(spectrogram), num_frames, len(spectrogram[0]))) for i in range(len(spectrogram)): for j in range(num_frames): dilation = np.power(dilation_factor, j) if i - dilation < 0: ? ? ? ? ? ? ? ? ? ?dilated_frames[i][j] = spectrogram[0] ? ? ? ? ? ? ? ?else: ? ? ? ? ? ? ? ? ? ?dilated_frames[i][j] = spectrogram[i - dilation] ? ? ? ?return dilated_frames
可視化空洞頻譜緩沖區
嵌入緩沖區
在人類記憶的許多模式中,感官記憶經過選擇性記憶這個過濾器,以避免短時記憶信息過載3。由于人類的認知資源有限,分配注意力到特定聽覺感知以優化心智能量的消耗是一項優勢。
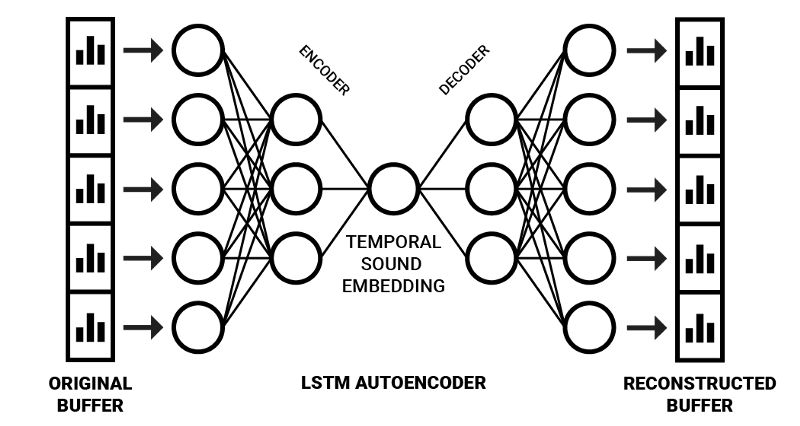
我們可以通過擴展自編碼器神經網絡架構實現這一方法。基于這一架構,我們可以給它傳入空洞頻率頻譜緩沖,以生成嵌入,而不是僅僅傳入瞬時頻率信息,這就結合了感官聲音記憶和選擇性注意瓶頸。為了處理序列化信息,我們可以使用序列到序列自編碼器架構6。
序列到序列(Seq2Seq)模型通常使用LSTM單元編碼序列數據(例如,一個英語句子)為內部表示(該表示包含整個句子的壓縮“含義”)。這個內部表示之后可以解碼回一個序列(例如,一個含義相同的西班牙語句子)7。
以這種方式得到的聲音嵌入,可以使用算力負擔低的簡單前饋神經網絡分析、處理。
據下圖所示訓練完網絡后,右半部分(解碼部分)可以“砍掉”,從而得到一個編碼時域頻率信息至壓縮空間的網絡。在這一領域,Y. Chung等的Audio Word2Vec取得了優秀的結果,通過應用Seq2Seq自動編碼器架構成功生成了可以描述語音錄音的序列化語音結構的嵌入6。使用更多樣化的輸入數據,它可以生成以更一般的方式描述聲音的嵌入。
基于Keras
依照之前描述的方法,我們用Keras實現一個生成音頻嵌入的Seq2Seq自動編碼器。我將它稱為聽者網絡,因為它的目的是“聽取”傳入的聲音序列,并將它壓縮為一個更緊湊的有意義表示,以供分析和處理。
我們使用了UrbanSound8K數據集(包含3小時左右的音頻)訓練這個網絡。UrbanSound8K數據集包含歸好類的環境音片段。我們使用Gammatone濾波器組處理聲音,并將其分割為8時步的空洞頻譜緩沖區(每個包含100個頻譜濾波器)。
from keras.models import Modelfrom keras.layers import Input, LSTM, RepeatVectordef prepare_listener(timesteps, input_dim, latent_dim, optimizer_type, loss_type): inputs = Input(shape=(timesteps, input_dim)) encoded = LSTM(int(input_dim / 2), activation="relu", return_sequences=True)(inputs) encoded = LSTM(latent_dim, activation="relu", return_sequences=False)(encoded) decoded = RepeatVector(timesteps)(encoded) decoded = LSTM(int(input_dim / 2), activation="relu", return_sequences=True)(decoded) decoded = LSTM(input_dim, return_sequences=True)(decoded) autoencoder = Model(inputs, decoded) encoder = Model(inputs, encoded) autoencoder.compile(optimizer=optimizer_type, loss=loss_type, metrics=['acc']) return autoencoder, encoder

網絡架構
聽者網絡的損失函數使用均方誤差,優化算法使用Adagrad,在一張NVIDIA GTX 1070上訓練了50個epoch,達到了42%的重建精確度。因為訓練耗時比較長,所以我在訓練進度看起來還沒有飽和的時候就停止了訓練。我很想知道,基于更大的數據集和更多算力資源訓練后這一模型表現如何。
肯定還有很多可以改進的地方,不過下面的圖像表明,在3.2的壓縮率下,模型捕捉到了輸入序列的大致結構。
-
頻譜
+關注
關注
7文章
887瀏覽量
45786 -
數字化
+關注
關注
8文章
8857瀏覽量
62171 -
機器學習
+關注
關注
66文章
8441瀏覽量
133093
原文標題:機器聽覺:四、在自編碼器架構中加入記憶機制
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Protel在線教程:如何在PCB文件中加漢字





 工商網監
工商網監
評論