 AlphaZero:一個算法通吃三大棋類
AlphaZero:一個算法通吃三大棋類
近日,谷歌旗下的人工智能實驗室DeepMind研究團隊在《科學》雜志上發表封面論文,公布了通用算法AlphaZero和測試數據。《科學》雜志評價稱,通過單一算法就能夠解決多個復雜問題,是創建通用的機器學習系統、解決實際問題的重要一步。該論文的作者包括AlphaGo的核心研發人員戴維·席爾瓦(David Silver)和DeepMind創始人戴密斯·哈薩比斯(Demis Hassabis)等。
2018年12月7日的《科學》雜志封面
AlphaGo首次為人們所熟知是2016年與圍棋世界冠軍李世石進行圍棋人機大戰,并最終以4比1的總比分獲勝。實際上早在2016年1月谷歌就在國際學術期刊《自然》雜志上發表封面文章,介紹AlphaGo在沒有任何讓子的情況下以5:0完勝歐洲冠軍、職業圍棋二段樊麾。
2016年1月28日《自然》雜志封面
2017年10月18日,DeepMind團隊公布了最強版阿爾法圍棋,代號AlphaGo Zero。彼時DeepMind表示,棋類AI的算法主要基于復雜的枚舉,同時需要人工進行評估,人們在過去幾十年內已經將這種方法做到極致了。而AlphaGo Zero在圍棋中的超人表現,則是通過與自己下棋練習出來的。
現在DeepMind研究團隊將這種方法推廣到AlphaZero的算法中,AlphaZero最長花了13天“自學成才”,隨后與世界冠軍級的棋類AI對決:
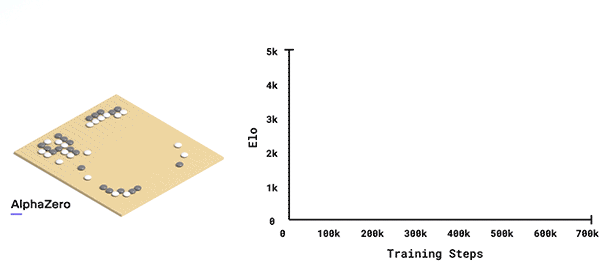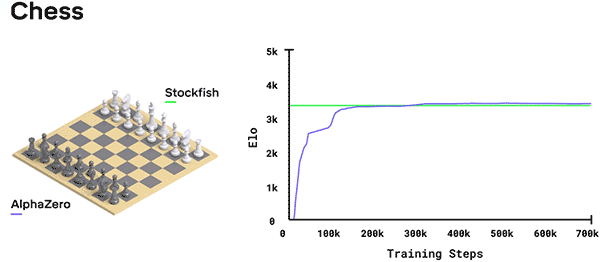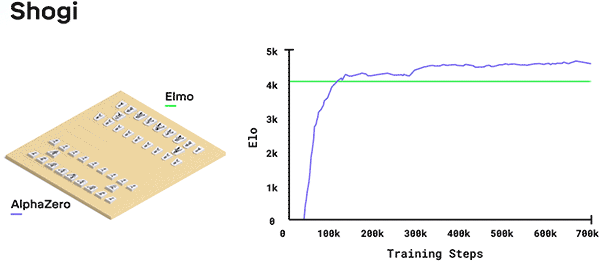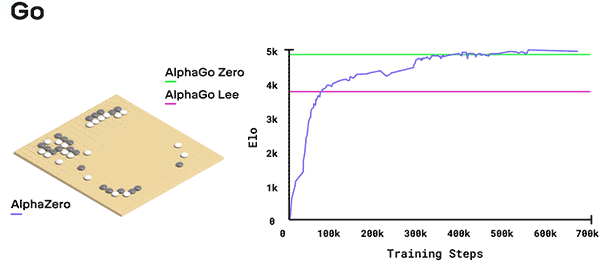
在國際象棋中,AlphaZero在4個小時后首次擊敗了第九季TCEC世界冠軍Stockfish。
在日本將棋中,AlphaZero在2小時后擊敗了將棋聯盟賽世界冠軍Elmo。
在圍棋上,AlphaZero經過30個小時的鏖戰,擊敗了李世石版AlphaGo。
AlphaZero:一個算法通吃三大棋類
AlphaGo的前幾代版本,一開始都是與人類棋手的棋譜進行上千盤的訓練,學習如何下圍棋。到了AlphaGo Zero則跳過了這個步驟,通過自我對弈學習下棋,從零學起。系統從一個對圍棋一無所知的神經網絡開始,將該神經網絡和一個強力搜索算法結合,自我對弈。在對弈過程中,神經網絡不斷調整、升級,預測每一步落子和最終的勝利者。
與AlphaGo Zero一樣,從隨機小游戲開始,AlphaZero依靠深度神經網絡、通用強化學習算法和蒙特卡洛樹搜索,在除了游戲規則外沒有任何知識背景的情況下,通過自我對弈進行強化學習。強化學習的方式是一種通過“試錯”的機器學習方式。
DeepMind在其博客中介紹,一開始AlphaZero完全是在瞎玩,但隨著時間的推移,系統從勝、負和平局中學習,調整神經網絡的參數,如此往復循環,每過一輪,系統的表現就提高了一點點,自我對弈的質量也提高了一點點,神經網絡也就越來越準確。神經網絡所需的訓練量取決于游戲的風格和復雜程度。經過試驗,AlphaZero花了9個小時掌握國際象棋,花了12個小時掌握日本將棋,花了13天掌握圍棋。
AlphaZero的訓練步驟
AlphaZero繼承了AlphaGo Zero的算法設置和網絡架構等,但兩者也有諸多不同之處。比如圍棋中很少會出現平局的情況,因此AlphaGo Zero是在假設結果為“非贏即輸”的情況下,對獲勝概率進行估計和優化。而AlphaZero會將平局或其他潛在結果也納入考慮,對結果進行估計和優化。
其次圍棋棋盤發生旋轉和反轉,結果都不會發生變化,因此AlphaGo Zero會通過生成8個對稱圖像來增強訓練數據。但國際象棋和日本將棋中,棋盤是不對稱的。因此,AlphaZero不會增強訓練數據,也不會在蒙特卡洛樹搜索期間轉換棋盤位置。
在AlphaGo Zero中,自我對弈是由以前所有迭代中最好的玩家生成的,而自我對弈也是與這個產生的新玩家對于。而AlphaZero只繼承了AlphaGo Zero的單一神經網絡,這個神經網絡不斷更新,而不是等待迭代完成。自我對弈是通過使用這個神經網絡的最新參數生成的,因此省略了評估步驟和選擇最佳玩家的過程。
此外,AlphaGo Zero使用的是通過貝葉斯優化調整搜索的超參數;AlphaZero中,所有對弈都重復使用相同的超參數,因此無需進行針對特定某種游戲的調整。唯一的例外是為保證探索噪聲和學習率。
研究團隊展示了在AlphaZero執白、Stockfish執黑的一局國際象棋里,經過1000次、10000次……直到100萬次模擬之后,AlphaZero蒙特卡洛樹的內部搜索狀態。每個樹狀圖解都展示了10個最常搜索的狀態。
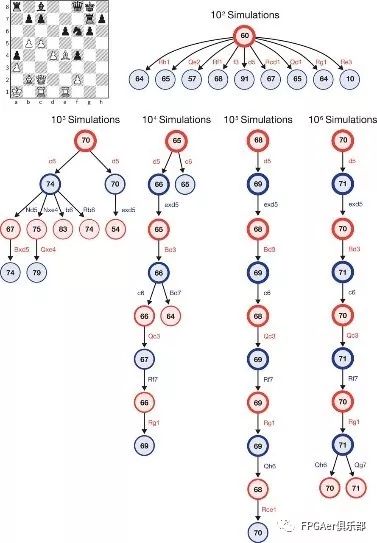
通過自我學習掌握國際象棋、日本將棋和圍棋的強化學習算法 《科學》雜志 圖
DeepMind研究團隊介紹,每個AI的硬件都是定制的。例如,在TCES世界錦標賽上,Stockfish和Elmo使用的是44核CPU。而AlphaZero和AlphaGo Zero則使用了一臺配備了4個第一代TPU和44核CPU的機器。雖然架構沒有可比性,但第一代TPU的處理速度與英偉達公司的Titan V型商用GPU相當。研究團隊在訓練環節里,投入了5000個一代TPU來生成自我對弈游戲,16個二代TPU來訓練神經網絡。
卡斯帕羅夫:聰明地工作比拼命地工作更重要
國際象棋是計算機科學家很早就開始研究的領域。1997年,深藍(Deep Blue)擊敗了人類國際象棋冠軍卡斯帕羅夫,這一事件成為了人工智能發展的里程碑。但彼時卡斯帕羅夫對深藍的印象并不深刻,認為深藍的智能水平和一個鬧鐘差不多。如今,他對棋類AI的看法也發生了轉變。他認為AlphaZero“像自己一樣”,下棋風格多變而開放。
在同一期《科學》雜志上,卡斯帕羅夫撰文稱,“傳統的機器是通過不斷枚舉來下棋,最終把棋局拖入無聊的平局。但在我的觀察中,AlphaZero會優先考慮棋子的活動而非盤面上的點數優勢,并且喜歡在相對風險更大的地方落子。”
盡管與傳統的冠軍級程序相比,研究人員用訓練好的神經網絡指導蒙特卡羅樹搜索,來選擇最有可能獲得勝利的一步,因此AlphaZero每秒計算的位置要少得多。據DeepMind介紹,在國際象棋中,AlphaZero每秒僅計算6萬個位置,相比之下,Stockfish則會計算6千萬個位置。但從比賽的結果來看,AlphaZero的思考顯然更有效率。
在國際象棋比賽中,AlphaZero擊敗了2016年TCEC(第九季)世界冠軍Stockfish,在1000場比賽中,贏得155場比賽,輸了6場(其余為平局)。為了驗證AlphaZero的穩健性,研究團隊還進行了一系列比賽,這些比賽都是從“人類開局方式”開始的,而AlphaZero都擊敗了Stockfish。
在將棋比賽中,AlphaZero擊敗了2017年CSA世界冠軍版Elmo,贏得了91.2%的比賽。
在圍棋比賽中,AlphaZero擊敗了AlphaGo Zero,贏得了61%的比賽。
對于AlphaZero取得的戰績,卡斯帕羅夫認為這正是印證了一句老話——聰明地工作比拼命地工作更重要。
在AlphaZero對陣各領域最強AI的戰績,綠色代表AlphaZero獲勝,灰色代表平局,粉色代表輸棋。 《科學》雜志圖
此外,卡斯帕羅夫表示,一個程序的特點通常反映了程序員思考的優先級和思維上的偏見,但由于AlphaZero是通過跟自己下棋來完善自己的思路的,所以它的風格反映的就是它自己。
在進行馬拉松式比賽的過程中,DeepMind研究團隊發現,AlphaZero自己發現并掌握了一些人類下棋時摸索出來的套路,比如在國際象棋中,AlphaZero掌握了幾種常見的開局模式、保王(King Safety)的思維以及各種兵陣的布局。但另一方面AlphaZero是自學成才的,不受到傳統觀念的影響,因此它還能為傳統策略的發展注入新鮮的血液。這一點得到了日本將棋史上第一個達成七冠王的羽生善治的贊同。
“AlphaZero會將王移到棋盤中央,從人類的角度來看,這是有違將棋理論的,它的一些路數走得也很危險。但令人難以置信的是,它始終控制著局面。AlphaZero獨特的風格打開了日本將棋新世界的大門。” 羽生善治表示。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101174 -
算法
+關注
關注
23文章
4630瀏覽量
93358 -
強化學習
+關注
關注
4文章
268瀏覽量
11301
原文標題:AlphaZero登上《科學》封面:一個算法通吃三大棋類
文章出處:【微信號:FPGAer_Club,微信公眾號:FPGAer俱樂部】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

史上最強棋類AI降臨!也是迄今最強的棋類AI——AlphaZero
AlphaZero一舉登上《科學》雜志封面
谷歌DeepMind圍棋吊打世界冠軍





 工商網監
工商網監
評論