 谷歌新研究使用連續拍攝的一對非模糊圖像,能夠合成運動模糊圖像
谷歌新研究使用連續拍攝的一對非模糊圖像,能夠合成運動模糊圖像
要想拍攝運動模糊效果的照片,需要高超的攝影技術。最近,谷歌兩名研究員開發了一種新算法,能夠使用兩張清晰圖像合成運動模糊效果。該技術也可用來合成訓練去模糊算法所需的訓練數據。
谷歌的研究人員最近開發了一種新技術,使用連續拍攝的一對非模糊圖像,能夠合成運動模糊圖像。在發表在arXiv上的預印版論文中,研究人員概述了他們的方法,并與幾種基線方法對比,對其進行了評估。
當場景中的物體或相機本身在拍攝時發生移動,運動模糊就會自然產生。這導致移動的物體或整個圖像看起來是模糊的。在某些情況下,運動模糊可以用來表示被攝對象的速度或將其與背景分離。
“在圖像理解方面,運動模糊是一個有價值的線索,”進行這項研究的谷歌研究員Tim Brooks和Jonathan Barron在論文中寫道:“給定一個包含運動模糊的圖像,我們可以估計導致觀察到的模糊的場景運動的相對方向和幅度。這種運動估計在語義上可能是有意義的,或者可以用去模糊算法來合成一個清晰的圖像。”
最近的研究已經探討了使用深度學習算法從圖像中去除不想要的運動模糊或推斷給定場景的運動動力學。然而,為了訓練這些算法,研究人員需要大量的數據,這些數據通常是通過合成模糊圖像生成的。最終,深度學習算法在多大程度上能夠有效去除真實圖像中的運動模糊,很大程度上取決于用于訓練運動模糊的合成數據的真實性。
“在這篇論文中,我們將這個已經有充分研究的模糊估計/模糊去除任務的逆向問題視為一個頭等問題。”Brooks和Barron在他們的論文中寫道:“我們提出了一種快速有效的方法來合成訓練運動去模糊算法所需的訓練數據,并且我們定量地證明了我們的技術能夠從合成的訓練數據推廣到真實的運動模糊圖像。”
圖1:(a)中展示了一個物體在圖像平面上移動的兩幅圖像。我們的系統利用這些圖像合成(b)中的運動模糊圖像,它傳達了一種運動的感覺,并將主體與背景分離。
他們設計的神經網絡架構包括一個新的“線性預測”(line prediction)層,它會教一個系統從連續拍攝的兩張圖像退回到跨越這兩張輸入圖像捕獲時間的運動模糊圖像。他們的模型需要大量的訓練數據,因此研究人員設計并執行了一種新策略,該策略使用幀插值技術(frame interpolation)生成運動模糊圖像及其各自輸入的大型合成數據集。
架構的圖示:以兩個輸入圖像的連接作為輸入,并使用U-Net卷積神經網絡來預測線性預測層的參數
Brooks和Barron還拍攝了一組由慢動作視頻合成的高質量的真實運動模糊圖像,然后用這些圖像來評估他們的模型與基線技術。他們的模型取得了非常好的結果,在準確性和速度上都優于現有的方法。
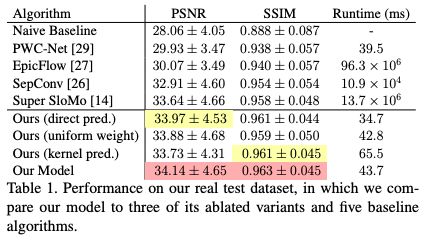
表1:在真實測試數據集上的性能,其中我們的模型與3個簡化變體和5個基線算法進行比較
研究人員在論文中寫道:“我們的方法快速、準確,并且使用來自視頻或’突發’的現成圖像作為輸入,因此能夠為攝影應用程序提供運動模糊處理,或為去模糊算法或運動估計算法所需的真實訓練數據的合成提供一種途徑。”
從合成訓練數據集中隨機抽取的5組輸入/輸出圖像對
雖然經驗豐富的攝影師經常將動態模糊視為一種藝術效果,但拍攝有效的動態模糊照片是非常具有挑戰性的。在大多數情況下,這些圖像是長期試錯過程的產物,而且需要先進的技術和設備。
在有經驗的攝影師手中,利用運動模糊可以產生引人注目的照片,像(a)那樣。但是對于大多數業余攝影師來說,運動模糊更有可能像(b)那樣。
由于難以獲得高質量的運動模糊效果,大多數消費者相機都被設計成盡可能少地拍攝運動模糊的圖像。這意味著業余攝影師幾乎沒有空間能在他們的圖像中嘗試運動模糊。
“通過將普通消費者相機拍攝到的傳統非模糊圖像合成為運動模糊圖像,我們的技術允許非專業人士在拍攝后創建運動模糊圖像。”研究人員在論文中解釋道。
最終, Brooks和Barron設計的方法可能會有許多有趣的應用。例如,它可以幫助業余攝影師實現藝術運動模糊效果,同時也能為訓練深度學習算法合成更逼真的運動模糊圖像。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101165 -
數據集
+關注
關注
4文章
1209瀏覽量
24830 -
深度學習
+關注
關注
73文章
5513瀏覽量
121544
原文標題:谷歌新研究用深度學習合成運動模糊效果,手抖也能拍出攝影師級照片
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
工業相機在高速抓拍圖像中的應用
【NanoPi M2試用體驗】圖像的模糊
模糊目標輪廓圖像分割研究


基于直覺模糊推理的醫學圖像融合方法研究







 工商網監
工商網監
評論