 ICLR 2019論文解讀:深度學習應用于復雜系統控制
ICLR 2019論文解讀:深度學習應用于復雜系統控制
引言
20世紀,控制論、系統論、信息論,對工業產生了顛覆性的影響。繼2011年深度學習在物體檢測上超越傳統方法以來,深度學習在識別傳感(包含語音識別、物體識別),自然語言處理領域里產生了顛覆性的影響。最近在信息論里,深度學習也產生了重要影響。使用深度學習可以對不同形式編碼的信息進行自動解碼。如今,深度學習再次影響控制論,傳統控制論往往是模型驅動算法,需要設計復雜的模型和控制方案,而以數據驅動為核心的深度學習用作控制領域的春天即將到來,這將推動數十萬億的工業、服務業的進一步升級。通過深度學習控制,可以讓機器人,能源,交通等行業效率顯著提升。例如,使用深度學習進行智能樓宇控制,可以節約大樓20%的能耗,傳統的控制需要多名專家2年的時間建立一個樓宇模型,深度學習可以利用樓宇歷史數據在一天內得到超越傳統方法的模型;在機器人控制和強化學習領域里,相比傳統控制方法,本文提出的方法可以節約80%以上的運算時間并且提升10%以上的控制準確度。
深度學習控制行業剛剛興起,還有很多的問題沒有解決,還需要很多的理論突破。近期,華盛頓大學研究組在ICLR2019發表了一篇深度學習控制的最新成果[1],這是第一次將深度學習與凸優化理論結合應用到最優控制理論中,在從理論層面保證模型達到全局最優解的同時,大幅提升了復雜系統控制的效率和準確度。該論文在公開評審中獲得了6/7/8的評分,在所有1449submissions中得分位列前90位(top6%)。在這里,論文的兩位作者將親自為我們解讀其中的核心思想。

論文地址:https://openreview.net/forum?id=H1MW72AcK7?eId=HylsgDCzeV
機器學習/強化學習與控制
自動控制與機器學習作為兩個擁有深厚歷史的學科,已經發展了數十年,并建立了各自較為完善的學科體系。在自動控制中的重要一環,是首先根據歷史數據對控制系統進行輸入-輸出的端到端建模。目前廣泛使用的系統辨識(systemidentification)方法主要有兩種:一是使用線性/或分段線性模型來預測系統的(狀態,控制變量)->(狀態)關系。這樣做的好處是后續的優化問題是線性優化問題(linearprogramming)并可結合控制論中的線性二次型調節器LQR(LinearQuadraticRegulator)等控制模型,易于求解并實現閉環最優控制。同時控制論較為注重系統的理論性質研究,如系統的李雅普諾夫穩定性,以及基于卡爾曼濾波等的最優狀態估計等。但是線性模型很難準確地描述復雜系統的動態,且建模過程需要大量專家知識和調試。因為存在對物理對象的建模,這類方法也被稱為基于模型的控制和強化學習model-basedcontrol/reinforcementlearning。第二種方法是使用一些較為復雜的機器學習模型,比如深度神經網絡,支持向量機(SVM)等對物理系統進行建模。相比線性模型,這些模型能夠更為準確地捕捉系統輸入-輸出的動態關系。而在一般的(深度)強化學習算法中,通常研究者也會訓練一個端到端的算法,由狀態直接輸出控制。由于不存在物理建模過程,這類方法也一般被稱為model-freecontrol/reinforcementlearning。但是這些復雜模型給后續的優化控制問題求解帶來了困難。我們都知道深度神經網絡,一般來說輸出對于輸入都是非凸的,包含很多局部最優點,所以在優化過程中很容易陷入局部最優情況。在對穩定性要求很高的系統控制情境下(比如電力系統控制,航天系統以及工業控制),這種多個局部最優解并且沒有全局最優收斂性保證的情況是我們非常不愿看到的,也一定程度限制了目前深度模型在這些行業中的應用。同時,在當前的深度強化學習研究中,盡管在多個應用和領域中已經取得行業領先的控制和優化效果,但對模型的理論性質尚缺乏研究,同時需要大量標注的狀態和決策數據以泛化模型的表征能力和應用場景[2](ICML2018tutorialandAnnualReviewofControl,RoboticsandAutonomousSystems,Recht,Berkeley)。
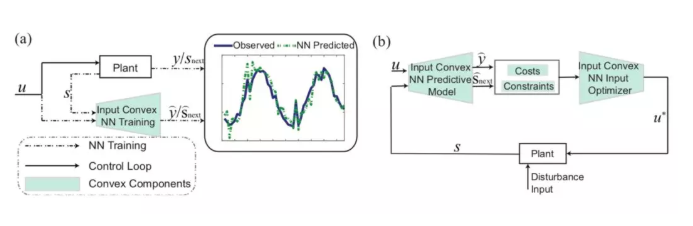
圖一:本文提出的輸入凸的神經網絡的(a)動態系統學習與(b)閉環控制過程。
在「Optimalcontrolvianeuralnetwork:aconvexapproach」一文中,作者提出了一種新的數據驅動的控制方法。該篇文章作出了結合model-freecontrol與model-basedcontrol的一步重要嘗試。在訓練過程中,我們用一個輸入凸(inputconvex)的神經網絡來表達系統表達復雜的動態特性;在控制與優化過程中,我們就可以將訓練好的神經網絡作為動態系統的模型,求解凸優化問題從而得到有最優保證的控制輸入。算法思路詳見圖一
基于輸入凸神經網絡的最優控制框架
為了解決現有模型的不足,本文作者提出了一種新的系統辨識方法:基于輸入凸的神經網絡的系統辨識。建立在之前InputConvexNeuralNetwork(ICNN)[3](ICML2017,Amosetal.,2017,CMU)的基礎上,本文作者提出一種新型的InputConvexRecurrentNeuralNetwork(ICRNN)用于具有時間關聯的動態系統建模。不同于通用的神經網絡結構,輸入凸的神經網絡要求所有隱藏層之間的權重矩陣非負,同時加入了對輸入向量的負映射以及輸入到隱藏層的直連層增加ICNN和ICRNN的表達能力。
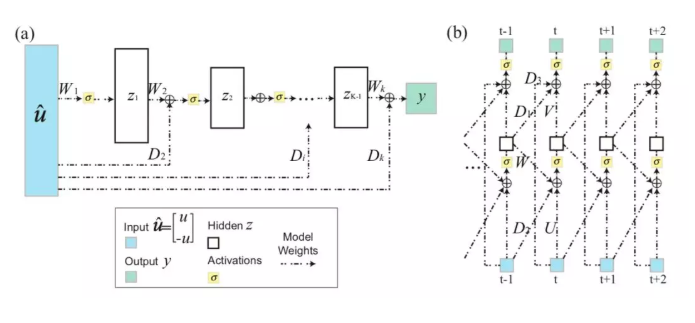
作者在文章中理論證明了,輸入凸神經網絡ICNN和ICRNN可以表示所有凸函數(Theorem1),并且其表達的效率比分段線性函數高指數級(Theorem2)。兩條性質保證所提出的網絡架構能夠很好地應用于優化與控制問題中用于對象建模與求解。
在使用輸入凸神經網絡進行系統建模后,作者將系統模型嵌入到模型預測控制(ModelPredictiveControl)框架中,用于求解最優的系統控制值。因為使用了輸入凸神經網絡,這里的MPC問題是一個凸優化問題,使用經典的梯度下降方法就可以保證我們找到最優的控制策略。如果系統的狀態或者控制輸入包含約束條件(constraints),我們也可以使用投影梯度下降(ProjectedGradientMethod)或者內點法進行求解。這樣,使用ICNN對瞬態特性建模或使用ICRNN對時序過程建模并用于控制對輸入優化求解,我們不僅能夠滿足控制論中對于最優解的性質的保證,同時也可以充分發揮深度模型的表征能力,即可作為一種適用于各領域的建模與控制方法。
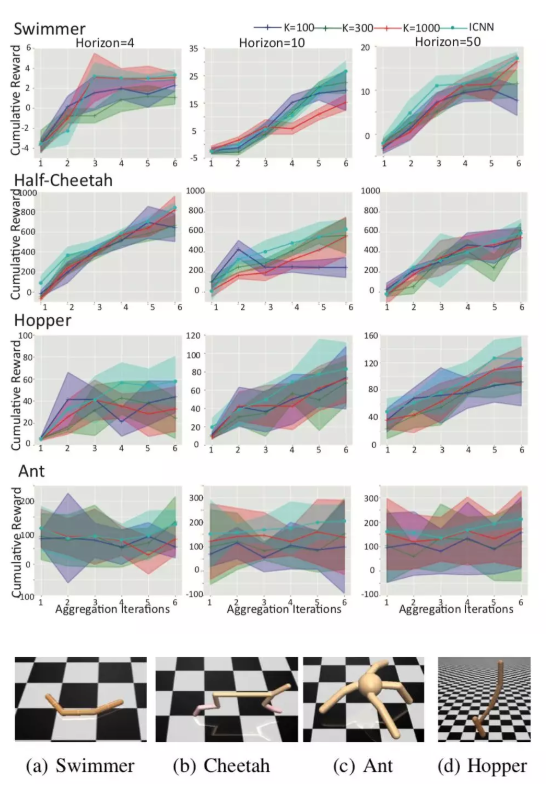
圖3.基于ICNN的MuJoColocomotiontasks的控制結果。K=100,300,1000對應[4]中基于模型的強化學習的算法設定,我們測試了在模型預測控制中,不同未來預測區間長度下各任務的回報。
應用一:機器人運動控制
作者首先將提出的深度學習控制框架應用于機器人的控制,使用的是OpenAI中的MuJuCo機器人仿真平臺的四個前向運動任務。我們首先使用隨機采樣的機器人動作和狀態的數據作為初始樣本訓練一個ICNN網絡,并結合DAGGER(AISTATS,Rossetal,2011,CMU)以在訓練和控制過程中更好地探索和泛化。本文提出的方法相比目前的強化學習方法更加高效、準確。同目前最好的基于模型的強化學習算法(model-basedRL)[4](2018ICRA,Nagabandietal.,2018,Berkeley)相比,本文提出的方法僅僅使用20%的運算時間就可以達到比之前方法高10%的控制效果(圖3)。與無模型的深度強化學習算法如TRPO,DDPG往往超過10^6的樣本數量相比,我們的控制方法可以從10^4量級的樣本中學習到極為準確的動態模型并用于控制。同時我們還可以將該方法得到控制結果作為初始控制策略,然后隨著機器人在環境中收集更多的樣本,與無模型的強化學習方法(model-freeRL)結合,在動態系統環境下實現更好的控制效果。
應用二:大樓的能源管理
同時,本文作者也將提出的深度學習控制框架應用于智能樓宇的供熱通風與空氣調節系統(HVAC)控制。我們通過建筑能耗仿真軟件EnergyPlus得到一棟大樓的分時能耗數據及各個分區的傳感器數據,并使用ICRNN建立樓宇輸入特征(如室內溫度,人流量,空調設定溫度等)到輸出特征(如能耗)的動態模型。在控制過程中,文章提出的模型可以非常方便地加入一系列約束,如溫度可調節范圍等。我們通過設計大樓在一定時間段內的溫度設置值,并滿足相應約束的前提下,來最優化樓宇的能耗。相比于傳統的線性模型以及控制方法,使用ICRNN的控制方法在保證房間溫度維持在[19,24]攝氏度區間內的情況下,幫助大樓節約多于20%的能耗。在更大的溫度波動區間內([16,27]攝氏度),可以幫助建筑節約近40%能耗(圖4左)。同時相比于傳統神經網絡模型直接用于系統建模,基于ICRNN的控制方法由于有控制求解的最優性保證,得到的溫度設定值更加的穩定(圖4右中紅線為ICRNN控制溫度設置,綠線為普通神經網絡控制溫度設置)。

目前,華盛頓大學的PaulAllenCenter電子工程與計算機大樓正在安裝相應的傳感器,并計劃將該控制方案用于該建筑HAVC系統的實時控制。
隨著5G時代的到來與物聯網技術的進一步發展,越來越多的物理系統中(電力,交通,航天,工業控制等)將會有更多的智能傳感器與數據流,本文提出的基于深度學習的控制方法也將會有更廣闊的應用空間。
參考資料:
[1]ChenYize*,YuanyuanShi*,andBaosenZhang."OptimalControlViaNeuralNetworks:AConvexApproach."ToAppearinInternationalConferenceonLearningRepresentations(ICLR),2019
[2]Recht,Benjamin."Atourofreinforcementlearning:Theviewfromcontinuouscontrol."AnnualReviewofControl,Robotics,andAutonomousSystems(2018).
[3]Amos,Brandon,LeiXu,andJ.ZicoKolter."Inputconvexneuralnetworks."InternationalConferenceonMachineLearning(ICML),2017
[4]Nagabandi,Anusha,etal."Neuralnetworkdynamicsformodel-baseddeepreinforcementlearningwithmodel-freefine-tuning."2018IEEEInternationalConferenceonRoboticsandAutomation(ICRA).IEEE,2018.
[5]Ross,Stéphane,GeoffreyGordon,andDrewBagnell."Areductionofimitationlearningandstructuredpredictiontono-regretonlinelearning."Proceedingsofthefourteenthinternationalconferenceonartificialintelligenceandstatistics.2011.
本文來源:機器之心
-
深度學習
+關注
關注
73文章
5513瀏覽量
121541
發布評論請先 登錄
相關推薦
如何實現多點位、復雜功能的PLC系統控制目標?
基于深度學習和3D圖像處理的精密加工件外觀缺陷檢測系統
ICLR 2019在官網公布了最佳論文獎!

ICLR 2019最佳論文日前揭曉 微軟與麻省等獲最佳論文獎項
Chip Huyen總結ICLR 2019年的8大趨勢 RNN正在失去研究的光芒
深度強化學習給推薦系統以及CTR預估工業界帶來的最新進展

機器人控制研究獲進展 能應用于真實的復雜移動機械臂控制
自監督學習與Transformer相關論文





 工商網監
工商網監
評論