 數據流是什么
數據流是什么
數據流最初是通信領域使用的概念,代表傳輸中所使用的信息的數字編碼信號序列。然而,我們所提到的數據流概念與此不同。這個概念最初在1998年由Henzinger在文獻87中提出,他將數據流定義為“只能以事先規定好的順序被讀取一次的數據的一個序列”。
數據流應用的產生的發展是以下兩個因素的結果:
細節數據:
已經能夠持續自動產生大量的細節數據。這類數據最早出現于傳統的銀行和股票交易領域,后來則也出現在地質測量、氣象、天文觀測等方面。尤其是互聯網(網絡流量監控,點擊流)和無線通信網(通話記錄)的出現,產生了大量的數據流類型的數據。我們注意到這類數據大都與地理信息有一定關聯,這主要是因為地理信息的維度較大,容易產生這類大量的細節數據。
復雜分析:
需要以近實時的方式對更新流進行復雜分析。對以上領域的數據進行復雜分析(如趨勢分析,預測)以前往往是(在數據倉庫中)脫機進行的,然而一些新的應用(尤其是在網絡安全和國家安全領域)對時間都非常敏感,如檢測互聯網上的極端事件、欺詐、入侵、異常,復雜人群監控,趨勢監控,探查性分析,和諧度分析等,都需要進行聯機的分析。
在此之后,學術界基本認可了這個定義,有的文章也在此基礎上對定義稍微進行了修改。例如,S. Guha等認為,數據流是“只能被讀取一次或少數幾次的點的有序序列”,這里放寬了前述定義中的“一遍”限制。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據流
+關注
關注
0文章
121瀏覽量
14437
發布評論請先 登錄
相關推薦
使用ADS1281做調制器,兩個調制器都是輸出1位的數據流,那合并之后數據流是幾位的呢?
]).
現在有以下兩個問題:
1.兩個調制器都是輸出1位的數據流,那合并之后數據流是幾位的呢?
2.如果取所有可能的情況,Y[n]的輸出范圍就是-24~+25,這個又要怎么理解呢?
發表于 02-05 09:10
適用于Oracle的SSIS數據流組件:提供快速導入及導出功能
使用SSIS 數據流組件,通過與關鍵數據庫和云服務的 Oracle 數據集成來改進您的 ETL 流程,這些組件提供快捷和可靠的數據導入和導出功能。 ? Oracle SSIS

Devart SSIS數據流組件
Devart SSIS 數據流組件是功能強大的工具,旨在簡化 SQL Server Integration Services (SSIS) 包內的 ETL 流程,使用戶無需編寫復雜的代碼即可

理解ECU數據流的分析方法
隨著汽車電子化程度的提高,ECU在車輛中扮演的角色越來越重要。它們不僅控制著發動機管理、變速箱、制動系統等關鍵功能,還涉及到車輛的舒適性和安全性。 ECU數據流分析的重要性 故障診斷 :通過
請問TLV320AIC3254EVM-K怎么讀取音頻數據流?
您好,我在學習TLV320AIC3254EVM-K開發板的過程中碰到一個這樣的問題,TI提供的軟件是否具備讀取I2S的音頻數據流的功能,或者是否有PC機軟件可以讀取音頻數據流,或者其它方法?請高手幫忙解決,萬分感謝!
發表于 10-31 06:14
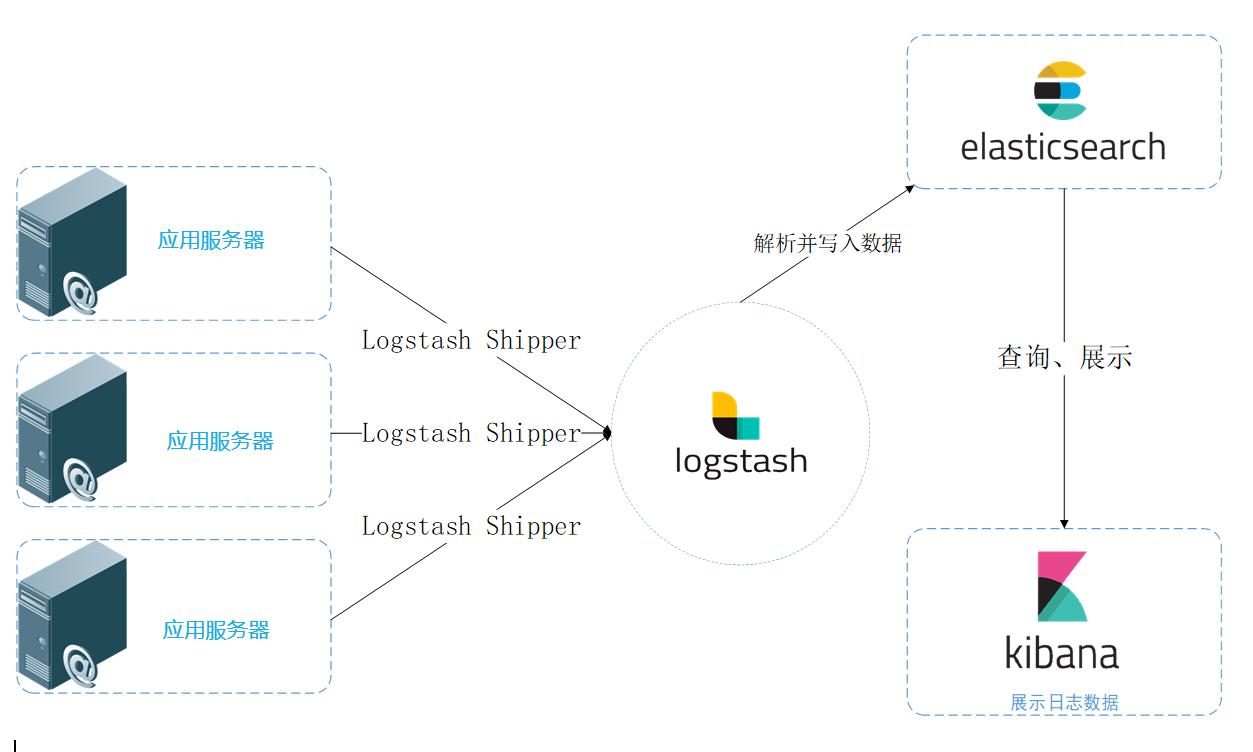
統一日志數據流圖
統一日志數據流圖 日志系統數據流圖 系統進行日志收集的過程可以分為三個環節: (1)日志收集和導入ElasticSearch (2)ElasticSearch進行索引等處理 (3)可視化操作,查詢等
使用CYUSB3014實現USB3VISION,不能成功發送DSI數據流是怎么回事?
/USB3-Vision-DMA-on-Leader-packet-on-FX3...。目前使用eBUS Player這個軟件能夠成功識別到U3V設備,并且連接成功,但是啟動發送數據流時,僅能夠發送leader數據,不能夠正常發送有效負載
發表于 07-05 07:58
ESP32的VOIP例程如何從WIFI移植到ETH有線網口?
您好,我現在有個項目,需要在ESP32 的有線網口上面,實現VOIP的語音通信,MQTT的通信;現在您的例程是通過WIFI 無線傳輸實現的。VOIP的例程中,怎么沒有看到wifi接收的數據流送給
發表于 06-28 07:59
ESP32如何在不漏數據的情況下采集數據流?
esp32作為spi從機連接一款AD,該AD芯片上電后就會持續不斷地向外發送數據,如果循環調用spi_slave_transmit(),那么兩次調用之間就會漏掉一些數據。
請問從機有沒有辦法在不漏數據的情況下采集這個
發表于 06-19 08:02
讓YUV2演示在FX3的內存上運行,啟動數據流時卻無法正常工作,應用程序會崩潰,為什么?
效(我看到了我的 4 幀樣本),但啟動數據流時卻無法正常工作,應用程序會崩潰。
在 linux 上運行時,v4L2 報告說它根本不起作用:
VIDIOC_STREAMON returned -1
發表于 05-28 08:18
FX3 UVC不穩定數據流是什么原因導致的?
我的 Zynq 7020 SoC 使用賽普拉斯 FX3。 我通過 USB3.0 傳輸 1920x1080 30FPS YUV 4:2:2 視頻流。 我遇到了一些問題,一段時間后(不是特定時間),我
發表于 05-21 06:51

stm32F429串口采用DMA方式發送,數據流使能失敗的原因?
DMA1 時鐘穩定
DMA_DeInit(DMA2_Stream7);// 復位初始化DMA數據流
while (DMA_GetCmdStatus(DMA2_Stream7) != DISABLE
發表于 04-17 07:05
FPGA實現雙調排序方法詳解
根據數據流的關系,我們可以采用單路徑延遲反饋(Single-pathDelay Feedback, SDF)運算單元流水結構,SDF單元如下圖所示。
發表于 03-28 10:45
?574次閱讀
fx3進行視頻數據流的傳輸的時候,請問如何修改可以達到同步傳輸的要求?
在fx3的固件中給出的slavefifo 是通過bulk傳輸的demo
我想進行視頻數據流的傳輸的時候,請問如何修改可以達到同步傳輸的要求
我目前在固件里面只看到了bulk的方式,如果有同步傳輸的demo或者修改教程請不吝賜教
FX3中的ISO數據傳輸,這一部分
發表于 02-28 07:50





 工商網監
工商網監
評論