") 如何選擇適合的聚類算法?聚類分析時(shí)需要使用什么變量?
如何選擇適合的聚類算法?聚類分析時(shí)需要使用什么變量?
聚類分析(cluster analysis)是常見(jiàn)的數(shù)據(jù)挖掘手段,其主要假設(shè)是數(shù)據(jù)間存在相似性。而相似性是有價(jià)值的,因此可以被用于探索數(shù)據(jù)中的特性以產(chǎn)生價(jià)值。常見(jiàn)應(yīng)用包括:
用戶分割:將用戶劃分到不同的組別中,并根據(jù)簇的特性而推送不同的廣告欺詐檢測(cè):發(fā)現(xiàn)正常與異常的用戶數(shù)據(jù),識(shí)別其中的欺詐行為
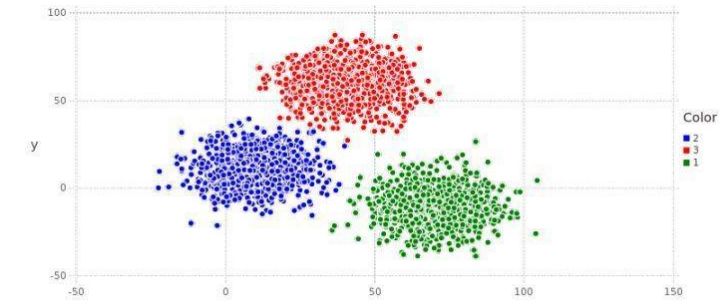
如上圖,數(shù)據(jù)可以被分到紅藍(lán)綠三個(gè)不同的簇(cluster)中,每個(gè)簇應(yīng)有其特有的性質(zhì)。顯然,聚類分析是一種無(wú)監(jiān)督學(xué)習(xí),是在缺乏標(biāo)簽的前提下的一種分類模型。當(dāng)我們對(duì)數(shù)據(jù)進(jìn)行聚類后并得到簇后,一般會(huì)單獨(dú)對(duì)每個(gè)簇進(jìn)行深入分析,從而得到更加細(xì)致的結(jié)果。
常見(jiàn)的聚類方法有不少,比如K均值(K-Means),譜聚類(Spectral Clustering),層次聚類(Hierarchical Clustering),大部分機(jī)器學(xué)習(xí)參考書(shū)上都有介紹,此處不再贅述。今天主要探討實(shí)際聚類分析時(shí)的一些技巧。
01 如何選擇適合的聚類算法
聚類算法的運(yùn)算開(kāi)銷(xiāo)往往很高,所以最重要的選擇標(biāo)準(zhǔn)往往是數(shù)據(jù)量。
但數(shù)據(jù)量上升到一定程度時(shí),如大于10萬(wàn)條數(shù)據(jù),那么大部分聚類算法都不能使用。最近讀到的一篇對(duì)比不同算法性能隨數(shù)據(jù)量的變化[1]很有意思。在作者的數(shù)據(jù)集上,當(dāng)數(shù)據(jù)量超過(guò)一定程度時(shí)僅K均值和HDBSCAN可用。
我的經(jīng)驗(yàn)也是,當(dāng)數(shù)據(jù)量超過(guò)5萬(wàn)條數(shù)據(jù)以后,K均值可能是比較實(shí)際的算法。但值得注意的是,K均值的效果往往不是非常好,我曾在如何正確使用「K均值聚類」?中對(duì)K均值進(jìn)行過(guò)總結(jié):
因此不難看出,K均值算法最大的優(yōu)點(diǎn)就是運(yùn)行速度快,能夠處理的數(shù)據(jù)量大,且易于理解。但缺點(diǎn)也很明顯,就是算法性能有限,在高維上可能不是最佳選項(xiàng)。
一個(gè)比較粗淺的結(jié)論是,在數(shù)據(jù)量不大時(shí),可以優(yōu)先嘗試其他算法。當(dāng)數(shù)據(jù)量過(guò)大時(shí),可以試試HDBSCAN。僅當(dāng)數(shù)據(jù)量巨大,且無(wú)法降維或者降低數(shù)量時(shí),再嘗試使用K均值。
一個(gè)顯著的問(wèn)題信號(hào)是,如果多次運(yùn)行K均值的結(jié)果都有很大差異,那么有很高的概率K均值不適合當(dāng)前數(shù)據(jù),要對(duì)結(jié)果謹(jǐn)慎的分析。
另一種替代方法是對(duì)原始數(shù)據(jù)進(jìn)行多次隨機(jī)采樣得到多個(gè)小樣本,并在小樣本上聚類,并融合結(jié)果。比如原始數(shù)據(jù)是100萬(wàn),那么從中隨機(jī)采樣出100個(gè)數(shù)據(jù)量等于1萬(wàn)的樣本,并在100個(gè)小數(shù)據(jù)集上用更為復(fù)雜的算法進(jìn)行聚類,并最終融合結(jié)果。
此處需要注意幾點(diǎn)問(wèn)題:
隨機(jī)采樣的樣本大小很重要,也不能過(guò)小。需要足夠有代表性,即小樣本依然可以代表總體的數(shù)據(jù)分布。如果最終需要?jiǎng)澐趾芏鄠€(gè)簇,那么要非常小心,因?yàn)樾颖究赡軣o(wú)法體現(xiàn)體量很小的簇。
在融合過(guò)程中要關(guān)注樣本上的聚類結(jié)果是否穩(wěn)定,隨機(jī)性是否過(guò)大。要特別注意不同樣本上的簇標(biāo)號(hào)是否統(tǒng)一,如何證明不同樣本上的簇結(jié)果是一致的。
因此我的經(jīng)驗(yàn)是,當(dāng)數(shù)據(jù)量非常大時(shí),可以優(yōu)先試試K均值聚類,得到初步的結(jié)果。如果效果不好,再通過(guò)隨機(jī)采樣的方法構(gòu)建更多小樣本,手動(dòng)融合模型提升聚類結(jié)果,進(jìn)一步優(yōu)化模型。
02 聚類分析時(shí)需要使用什么變量?
這個(gè)是一個(gè)非常難回答的問(wèn)題,而且充滿了迷惑性,不少人都做錯(cuò)了。舉個(gè)簡(jiǎn)單的例子,我們現(xiàn)在有很多客戶的商品購(gòu)買(mǎi)信息,以及他們的個(gè)人信息,是否該用購(gòu)買(mǎi)信息+個(gè)人信息來(lái)進(jìn)行聚類呢?
未必,我們需要首先回答最重要的一個(gè)問(wèn)題:我們要解決什么問(wèn)題?
如果我們用個(gè)人信息,如性別、年齡進(jìn)行聚類,那么結(jié)果會(huì)被這些變量所影響,而變成了對(duì)性別和年齡的聚類。所以我們應(yīng)該先問(wèn)自己,“客戶購(gòu)物習(xí)慣”更重要還是“客戶的個(gè)人信息”更重要?
如果我們最在意的是客戶怎么花錢(qián),以及購(gòu)物特征,那就應(yīng)該完全排除客戶的個(gè)人信息(如年齡性別家庭住址),僅使用購(gòu)買(mǎi)相關(guān)的數(shù)據(jù)進(jìn)行聚類。這樣的聚類結(jié)果才是完全由購(gòu)買(mǎi)情況所驅(qū)動(dòng)的,而不會(huì)受到用戶個(gè)人信息的影響。
那該如何更好的利用客戶的個(gè)人信息呢?這個(gè)應(yīng)該被用在聚類之后。當(dāng)我們得到聚類結(jié)果后,可以對(duì)每個(gè)簇進(jìn)行分析,分析簇中用戶的個(gè)人情況,比如高凈值客戶的平均年齡、居住區(qū)域、開(kāi)什么車(chē)。無(wú)關(guān)變量不應(yīng)該作為輸入,而應(yīng)該得到聚類結(jié)果后作為分析變量。
一般情況下,我們先要問(wèn)自己,這個(gè)項(xiàng)目在意的是什么?很多時(shí)候個(gè)人信息被錯(cuò)誤的使用在了聚類當(dāng)中,聚類結(jié)果完全由個(gè)人信息所決定(比如男性和女性被分到了兩個(gè)簇中),對(duì)于商業(yè)決策的意義就不大了。一般來(lái)說(shuō),應(yīng)該由商業(yè)數(shù)據(jù)驅(qū)動(dòng),得到聚類結(jié)果后再對(duì)每個(gè)簇中的用戶個(gè)人信息進(jìn)行整合分析。
但值得注意的是,這個(gè)方法不是絕對(duì)的。在聚類中有時(shí)候也會(huì)適當(dāng)引入個(gè)人信息,也可以通過(guò)調(diào)整不同變量的權(quán)重來(lái)調(diào)整每個(gè)變量的影響。
03 如何分析變量的重要性?
首先變量選擇是主觀的,完全依賴于建模者對(duì)于問(wèn)題的理解,而且往往都是想到什么用什么。因?yàn)榫垲愂菬o(wú)監(jiān)督學(xué)習(xí),因此很難評(píng)估變量的重要性。介紹兩種思考方法:
考慮變量的內(nèi)在變化度與變量間的關(guān)聯(lián)性:一個(gè)變量本身方差很小,那么不易對(duì)聚類起到很大的影響。如果變量間的相關(guān)性很高,那么高相關(guān)性間的變量應(yīng)該被合并處理。直接采用算法來(lái)對(duì)變量重要性進(jìn)行排序:比如 Principal Feature Analysis [2],網(wǎng)上有現(xiàn)成的代碼 [3]。
另一個(gè)雞生蛋蛋生雞的問(wèn)題是,如果我用算法找到了重要特征,那么僅用重要特征建模可以嗎?這個(gè)依然不好說(shuō),我覺(jué)得最需要去除的是高相關(guān)性的變量,因?yàn)楹芏嗑垲愃惴o(wú)法識(shí)別高相關(guān)性,會(huì)重復(fù)計(jì)算高相關(guān)性特征,并夸大了其影響,比如K均值。
04 如何證明聚類的結(jié)果有意義?如何決定簇的數(shù)量?
聚類分析是無(wú)監(jiān)督學(xué)習(xí),因此沒(méi)有具體的標(biāo)準(zhǔn)來(lái)證明結(jié)果是對(duì)的或者錯(cuò)的。一般的判斷方法無(wú)外乎三種:
人為驗(yàn)證聚類結(jié)果符合商業(yè)邏輯。比如我們對(duì)彩票客戶進(jìn)行聚類,最終得到4個(gè)簇,其中分為:
“高購(gòu)買(mǎi)力忠實(shí)客戶”:花了很多錢(qián)的忠實(shí)客戶,他們可能常年購(gòu)買(mǎi)且花費(fèi)不菲
“普通忠實(shí)客戶”:常年購(gòu)買(mǎi),但每次的購(gòu)買(mǎi)額度都不大
“刺激性消費(fèi)單次購(gòu)買(mǎi)者”:只購(gòu)買(mǎi)了幾次,但是一擲千金
“謹(jǐn)慎的單次購(gòu)買(mǎi)者”:只購(gòu)買(mǎi)了幾次,每次買(mǎi)的都很謹(jǐn)慎
我們可以用通過(guò)商業(yè)邏輯來(lái)解釋聚類結(jié)果,結(jié)果應(yīng)該大致符合行業(yè)專家的看法。最終你的聚類結(jié)果需要回歸到現(xiàn)實(shí)的商業(yè)邏輯上去,這樣才有意義。
預(yù)先設(shè)定一些評(píng)估標(biāo)準(zhǔn),比如簇內(nèi)的緊湊度和簇間的疏離度,或者定義好的函數(shù)如Silhouette Coefficient。一般來(lái)說(shuō)設(shè)定一個(gè)好的評(píng)估標(biāo)準(zhǔn)并不容易,所以不能死板的單純依賴評(píng)估函數(shù)。
通過(guò)可視化來(lái)證明不同簇之間的差異性。因?yàn)槲覀円话阌谐^(guò)兩個(gè)變量,所以會(huì)需要先對(duì)數(shù)據(jù)進(jìn)行壓縮,比如很多流形學(xué)習(xí)的方法多維縮放(multi-dimensional scaling)。
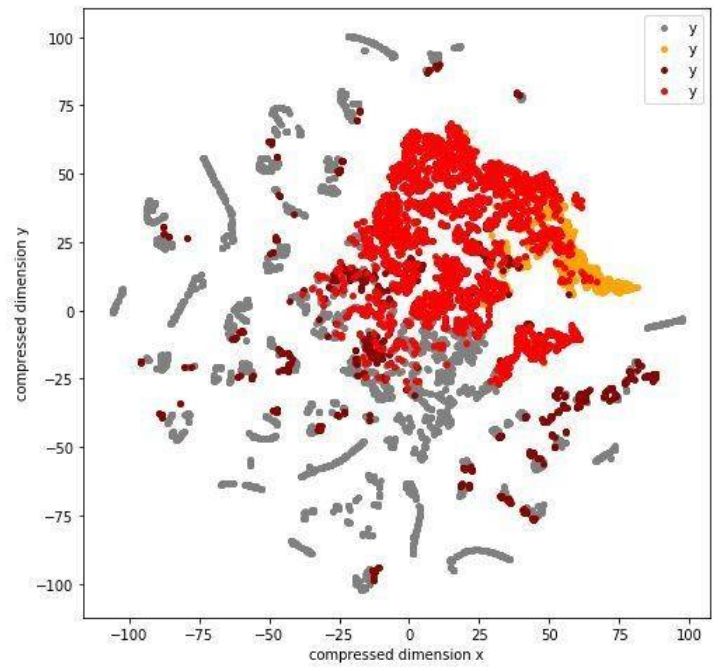
以下圖為例,我把數(shù)據(jù)分成了四個(gè)簇,并用T-SNE壓縮到二維并繪制出來(lái)。從直觀上看,不同簇間有了一定區(qū)別。類似的可視化也可以在變量間兩兩繪制,或者直接畫(huà)pairplot。
所以如何定義一個(gè)好的聚類結(jié)果?我認(rèn)為應(yīng)該符合幾個(gè)基本標(biāo)準(zhǔn):
符合商業(yè)常識(shí),大致方向上可以被領(lǐng)域?qū)<宜?yàn)證可視化后有一定的區(qū)別,而并非完全隨機(jī)且交織在一起如果有預(yù)先設(shè)定的評(píng)估函數(shù),評(píng)估結(jié)果較為優(yōu)秀
因此決定簇的數(shù)量也應(yīng)該遵循這個(gè)邏輯,適當(dāng)?shù)臄?shù)量應(yīng)該滿足以上三點(diǎn)條件。如果某個(gè)簇的數(shù)量過(guò)大或者過(guò)小,那可以考慮分裂或者合并簇。
當(dāng)然,聚類作為無(wú)監(jiān)督學(xué)習(xí),有很多模棱兩可的地方。但應(yīng)時(shí)時(shí)牢記的是,機(jī)器學(xué)習(xí)模型應(yīng)服務(wù)商業(yè)決策,脫離問(wèn)題空談模型是沒(méi)有意義的。
-
數(shù)據(jù)挖掘
+關(guān)注
關(guān)注
1文章
406瀏覽量
24322 -
聚類算法
+關(guān)注
關(guān)注
2文章
118瀏覽量
12158 -
聚類分析
+關(guān)注
關(guān)注
0文章
16瀏覽量
7427
原文標(biāo)題:【集客經(jīng)營(yíng)】干貨:如何對(duì)用戶進(jìn)行「聚類分析」?
文章出處:【微信號(hào):xiacoinfo,微信公眾號(hào):資治通信】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一種基于GiST的層次聚類算法
聚類算法研究
基于PLSA模型的用戶興趣聚類算法研究
基于C均值聚類的定位算法
聚類分析的簡(jiǎn)單案例
淺談Matlab中的聚類分析 Matlab聚類程序的設(shè)計(jì)
如何使用K-Means聚類算法改進(jìn)的特征加權(quán)算法詳細(xì)資料概述
如何在python中安裝和使用頂級(jí)聚類算法?
10種聚類算法和Python代碼1
10種聚類算法和Python代碼2
10種聚類算法和Python代碼3
10種聚類算法和Python代碼4





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論