") OpenAl提出了一種適用于文本、圖像和語音的稀疏Transformer
OpenAl提出了一種適用于文本、圖像和語音的稀疏Transformer
OpenAl提出了一種適用于文本、圖像和語音的稀疏Transformer,將先前基于注意力機(jī)制的算法處理序列的長度提高了三十倍。
對復(fù)雜高維度的數(shù)據(jù)分布進(jìn)行估計(jì)一直是非監(jiān)督學(xué)習(xí)領(lǐng)域的核心問題,特別是針對像文本、語音、圖像等長程、相關(guān)性數(shù)據(jù)更使得這一領(lǐng)域充滿了挑戰(zhàn)。同時,對于復(fù)雜數(shù)據(jù)的建模也是非監(jiān)督表示學(xué)習(xí)的關(guān)鍵所在。近年來,神經(jīng)自回歸模型在這一領(lǐng)域取得了一系列十分優(yōu)秀進(jìn)展,針對自然語言、原始音頻和圖像成功建模。這些方法將聯(lián)合概率分布分解成了條件概率分布的乘積來解決。但由于數(shù)據(jù)中包含許多復(fù)雜、長程的依賴性并需要合適的表達(dá)模型架構(gòu)來進(jìn)行學(xué)習(xí),使得對數(shù)據(jù)的條件概率分布建模依舊十分復(fù)雜。基于卷積神經(jīng)網(wǎng)絡(luò)的架構(gòu)在這個方向取得了一系列進(jìn)展,但需要一定的深度來保證足夠的感受野。
為了解決這一問題,WaveNet引入了膨脹卷積(dilated conv)幫助網(wǎng)絡(luò)在的對數(shù)數(shù)量層數(shù)下學(xué)習(xí)長程依賴性。于此同時Transformer由于可以利用一定的層數(shù)為任意的依賴性建模,在自然語言任務(wù)上顯示出了強(qiáng)大的優(yōu)勢。由于每個自注意力層用于全局感受野使得網(wǎng)絡(luò)可以將表示能力用于最有用的輸入?yún)^(qū)域,對于生成多樣性的數(shù)據(jù)具有更加靈活的特征。但這種方法在處理序列時需要面臨隨著序列長度平方增長的內(nèi)存與算力。對于過長的序列,現(xiàn)有的計(jì)算機(jī)將無法處理和實(shí)現(xiàn)。為了解決這一問題,OpenAI的研究人員在最新的論文中為注意力矩陣引入了多種稀疏的分解方式,通過將完全注意力計(jì)算分解為多個更快的注意力操作,通過稀疏組合來進(jìn)行稠密注意力操作,在不犧牲性能的情況下大幅降低了對于內(nèi)存和算力的需求。
新提出了稀疏Transformer將先前Transforme的平方復(fù)雜度O(N^2)降低為O(NN^1/2),通過一些額外的改進(jìn)使得自注意力機(jī)制可以直接用于長程的語音、文本和圖像數(shù)據(jù)。原先的方法大多集中于一個特定的領(lǐng)域、并且很難為超過幾千個元素長度的序列建模,而稀疏Transformer則可利用幾百層的模型為上萬個數(shù)據(jù)長度的序列建模,并在不同領(lǐng)域中實(shí)現(xiàn)了最優(yōu)異的結(jié)果。
在Transformer中,輸入和輸出的每一個元素都通過權(quán)重相連,利用注意力機(jī)制算法可以根據(jù)實(shí)際情況動態(tài)更新權(quán)重,使得Transformer具有更加靈活的特性。但在工程實(shí)踐中,針對N維輸出我們需要N*N的注意力矩陣來為每一層存儲權(quán)重,這將消耗大量的內(nèi)存,特別是針對音頻和圖像這種長序列的數(shù)據(jù)來說,內(nèi)存分分鐘就將被算法吃完。下表給出了針對不同數(shù)據(jù)所需要的內(nèi)存大小和計(jì)算量。
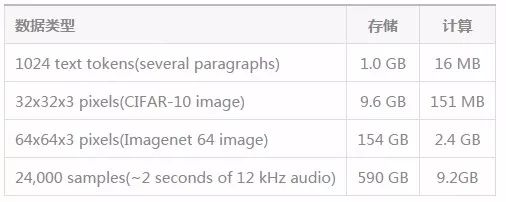
這一表格針對64層4heads的深度Transformer對于內(nèi)存和計(jì)算的需求,而一般的顯卡只有12-32G顯存,顯然對于長程的圖像、語言數(shù)據(jù)是無能為力的。受到深度學(xué)習(xí)中減小內(nèi)存的啟發(fā),研究人員們在注意力矩陣反向傳播時引入了checkpoint的概念,這使得內(nèi)存的消耗與網(wǎng)絡(luò)層的數(shù)量解耦,讓更深的網(wǎng)絡(luò)訓(xùn)練成為可能。
稀疏注意力機(jī)制
解決了內(nèi)存的問題并不意味著我們可以水到渠成地訓(xùn)練長程數(shù)據(jù)了。即使對于單個注意力矩陣來說對于長程數(shù)據(jù)的計(jì)算在實(shí)際中依然很難實(shí)現(xiàn)。為了處理這一問題,研究人員利用了稀疏注意力模式從輸入數(shù)據(jù)中選出一小部分來計(jì)算輸出,這一個輸入子集相對于輸入整體來說很小,使得最終對于每一個長程序列的計(jì)算結(jié)果變得可控。為了驗(yàn)證這種方法的有效性,研究人員對學(xué)習(xí)到的注意力模式進(jìn)行了可視化,并在其中發(fā)現(xiàn)了很多具有可解釋性的稀疏模式。下圖中可以看到白色發(fā)光的像素被被注意力頭所接受并用于預(yù)測下一個位置的輸出。當(dāng)輸入集中于很小一個子集并加入較高的正則化時,這一層將會變得系數(shù)化。下圖中可以看到不同的層學(xué)會了不同的稀疏注意力機(jī)制,左圖是19層基于每一行來進(jìn)行預(yù)測,而右圖為20層基于每一列來進(jìn)行預(yù)測,將完全注意力機(jī)制進(jìn)行了有效的分解。
不同層的注意力具有不同的側(cè)重。有的層只對特定的空間位置產(chǎn)生注意力只注重特定的位置,而有的層注意力則高度依賴于輸入的數(shù)據(jù),具有全局的動態(tài)注意力。
為了保留模型對于這些模式的學(xué)習(xí)能力,研究人員將注意力矩陣進(jìn)行了二維分解,以便網(wǎng)絡(luò)可以通過兩步稀疏注意力實(shí)現(xiàn)對于所有位置的審視。
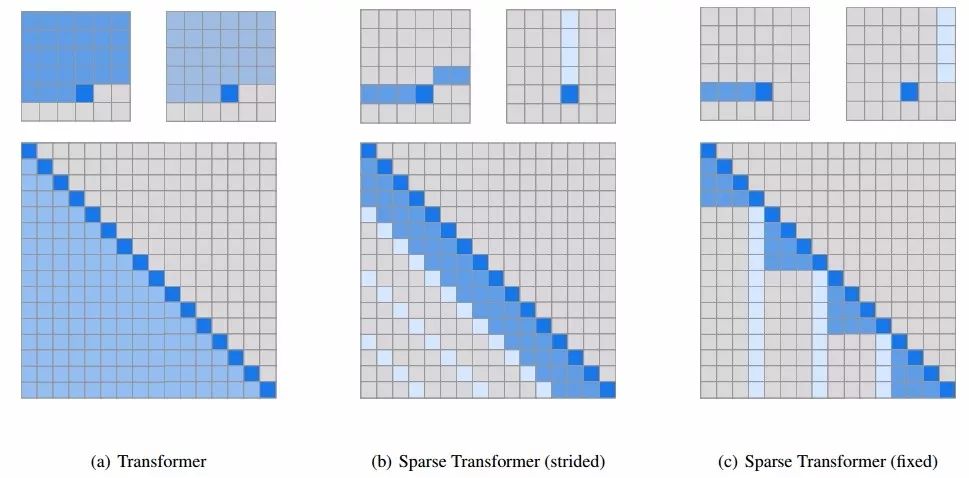
上圖中間是第一種步進(jìn)注意力的版本,可以粗略的理解為每一個位置需要注意它所在的行和列;另一種固定注意力的方式則嘗試著從固定的列和元素中進(jìn)行處理,這種方式對于非二維結(jié)構(gòu)的數(shù)據(jù)有著很好的效果。
實(shí)驗(yàn)結(jié)果
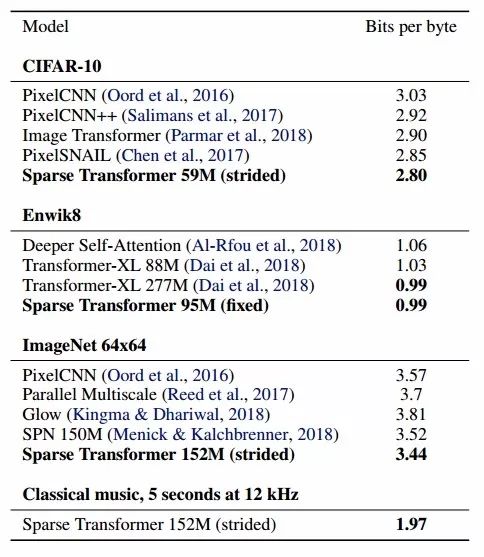
在CIFAR-10,Enwik8和Imagenet64上研究人員比較了新提出方法的密度建模性能,可以看到這種方法對于各個數(shù)據(jù)集建模都有著優(yōu)秀的能力。
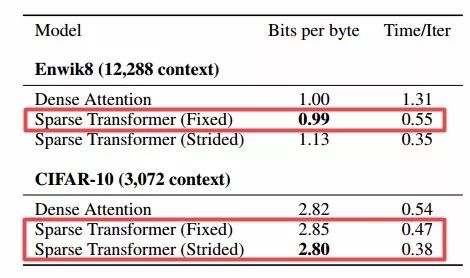
同時研究人員還發(fā)現(xiàn)稀疏注意力比完全注意力的損失更小、更快。
由于transformer對全局結(jié)構(gòu)具有一定的理解,可以對缺失的圖像進(jìn)行補(bǔ)全。
同時利用極大似然估計(jì)從模型中進(jìn)行采樣生成了一系列圖像:
稀疏Transformer對于原始的音頻輸入依然能進(jìn)行有效的處理,實(shí)驗(yàn)中可以生成65000個元素的聲音序列(近5s鐘的音頻)。只需要稍微改變模型的位置嵌入就可以適應(yīng)不同形式的輸入。
在未來研究人員還將繼續(xù)針對長程序列研究高效的建模方式,并探索不同類型的稀疏性結(jié)合。雖然這種方法取得了很好的效果,但是對于高分辨的圖像甚至視頻依然無法有效處理。研究人員計(jì)劃在未來引入高維數(shù)據(jù)建模方式和稀疏注意力共同解決這一挑戰(zhàn)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101166 -
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40572 -
數(shù)據(jù)建模
+關(guān)注
關(guān)注
0文章
11瀏覽量
7012
原文標(biāo)題:OpenAI提出新方法Sparse Transformer,大幅度提高長程序列數(shù)據(jù)建模能力
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種適用于鋰電池的電流監(jiān)測電路設(shè)計(jì)
一種能同時適用于ISM兩頻段的功率分配器設(shè)計(jì)
一種適用于模擬/數(shù)字混合信號環(huán)境的接地技術(shù)
分享一種不錯的無線語音傳輸系統(tǒng)設(shè)計(jì)方案
一種適用于嵌入式系統(tǒng)的模塊動態(tài)加載技術(shù)
一種適用于空間觀測任務(wù)的實(shí)時多目標(biāo)識別算法分享
一種有效的文本圖像二值化方法
一種適用于可視電話的快速運(yùn)動估計(jì)算法
一種適用于醫(yī)學(xué)領(lǐng)域的頻率可調(diào)濾波器
一種適用于任意余數(shù)基的高性能后向轉(zhuǎn)換結(jié)構(gòu)_楊鵬
一種適用于SoC的瞬態(tài)增強(qiáng)型線性穩(wěn)壓器_張琪
基于嶺回歸的稀疏編碼文本圖像復(fù)原方法
適用于稀疏多徑信道的稀疏自適應(yīng)常模盲均衡算法

一種適用于動態(tài)場景的多層次地圖構(gòu)建算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論