") 三種方法突破人工智能魯棒性極限
三種方法突破人工智能魯棒性極限
近期,DeepMind在其博客中向我們描述了三種可以嚴(yán)格識別和消除學(xué)習(xí)預(yù)測模型中的錯誤的方法:對抗性測試,魯棒學(xué)習(xí)和形式驗證。
自計算機(jī)編程開始以來,Bug與軟件就齊頭并進(jìn)。
隨著時間的推移,軟件開發(fā)人員在部署之前已經(jīng)建立了一套測試和調(diào)試的最佳實踐,但這些實踐并不適合現(xiàn)代深度學(xué)習(xí)系統(tǒng)。
今天,機(jī)器學(xué)習(xí)的主流實踐是在訓(xùn)練數(shù)據(jù)集上訓(xùn)練系統(tǒng),然后在另一組上進(jìn)行測試。雖然這揭示了模型在一般情況下的平均性能,但即使在最壞的情況下,確保模型的穩(wěn)健性或可接受的高性能也是至關(guān)重要的。
近期,DeepMind在其博客中向我們描述了三種可以嚴(yán)格識別和消除學(xué)習(xí)預(yù)測模型中的錯誤的方法:對抗性測試,魯棒學(xué)習(xí)和形式驗證。
以下是博文內(nèi)容:
機(jī)器學(xué)習(xí)系統(tǒng)一般是不穩(wěn)健的。即使在特定領(lǐng)域中表現(xiàn)優(yōu)于人類的系統(tǒng),如果引入細(xì)微差異,也可能無法解決簡單問題。例如圖像擾動的問題:如果在輸入圖像中添加少量精心計算的噪聲,那么對圖像進(jìn)行分類的神經(jīng)網(wǎng)絡(luò),就會容易將樹懶誤認(rèn)為是賽車。
覆蓋在典型圖像上的對抗性輸入可能導(dǎo)致分類器將樹懶錯誤地分類為賽車。兩個圖像在每個像素中相差至多0.0078。第一種被歸類為三趾樹懶,置信度> 99%。第二個被歸類為賽車,概率> 99%。
這不是一個新問題。計算機(jī)程序總是有bug。幾十年來,軟件工程師開發(fā)了許多令人印象深刻的技術(shù)工具包,從單元測試到形式驗證。這些方法在傳統(tǒng)軟件上運(yùn)行良好,但是由于這些模型的規(guī)模和缺乏結(jié)構(gòu)性(可能包含數(shù)億個參數(shù)),因此采用傳統(tǒng)方法來嚴(yán)格測試神經(jīng)網(wǎng)絡(luò)等機(jī)器學(xué)習(xí)模型非常困難。所以需要開發(fā)用于確保機(jī)器學(xué)習(xí)系統(tǒng)在部署時穩(wěn)健的新方法。
從程序員的角度來看,Bug是指與系統(tǒng)規(guī)范(即預(yù)期功能)不一致的任何行為。DeepMInd對用于評估機(jī)器學(xué)習(xí)系統(tǒng)是否與訓(xùn)練集和測試集一致的技術(shù),以及描述系統(tǒng)的期望屬性的規(guī)范列表的技術(shù)進(jìn)行了研究。這些屬性包括:對輸入中足夠小的擾動的魯棒性,避免災(zāi)難性故障的安全約束,或產(chǎn)生符合物理定律的預(yù)測能力等。
在本文中,我們將討論機(jī)器學(xué)習(xí)社區(qū)面臨的三個重要技術(shù)挑戰(zhàn),因為我們共同致力于嚴(yán)格開發(fā)和部署與所需規(guī)格可靠一致的機(jī)器學(xué)習(xí)系統(tǒng):
測試一致性與規(guī)范有效性。我們探索有效的方法來測試機(jī)器學(xué)習(xí)系統(tǒng)是否與設(shè)計者和系統(tǒng)用戶所期望的屬性(例如不變性或魯棒性)一致。揭示模型可能與期望行為不一致的情況的一種方法是在評估期間系統(tǒng)地搜索最壞情況的結(jié)果。
訓(xùn)練機(jī)器學(xué)習(xí)模型,使其產(chǎn)生規(guī)范一致的預(yù)測。即使有大量的訓(xùn)練數(shù)據(jù),標(biāo)準(zhǔn)的機(jī)器學(xué)習(xí)算法也可以產(chǎn)生與魯棒或公平等理想規(guī)范不一致的模型,這要求我們重新考慮訓(xùn)練算法,這些算法不僅要能夠很好地擬合訓(xùn)練數(shù)據(jù),而且能夠與規(guī)范清單保持一致。
正式證明機(jī)器學(xué)習(xí)模型是規(guī)范一致的。需要能夠驗證模型預(yù)測可證明與所有可能輸入的感興趣的規(guī)范一致的算法。雖然形式驗證領(lǐng)域幾十年來一直在研究這種算法,但這些方法雖然取得了令人矚目的進(jìn)展,但卻不能輕易地擴(kuò)展到現(xiàn)代深度學(xué)習(xí)系統(tǒng)。
測試與規(guī)范性一致性
對抗性實例的穩(wěn)健性是深度學(xué)習(xí)中相對研究充分的問題。這項工作的一個主要主題是評估強(qiáng)攻擊的重要性,以及設(shè)計可以有效分析的透明模型。與社區(qū)的其他研究人員一起,我們發(fā)現(xiàn)許多模型在與弱對手進(jìn)行評估時看起來很穩(wěn)健。然而,當(dāng)針對更強(qiáng)的對手進(jìn)行評估時,精度幾乎為0。
雖然大多數(shù)工作都在監(jiān)督學(xué)習(xí)(主要是圖像分類)的情景下的很少失敗,但是需要將這些想法擴(kuò)展到其他情景。
在最近關(guān)于發(fā)現(xiàn)災(zāi)難性故障的對抗方法的工作中,我們將這些想法應(yīng)用于測試旨在用于安全關(guān)鍵設(shè)置的強(qiáng)化學(xué)習(xí)agent。開發(fā)自治系統(tǒng)的一個挑戰(zhàn)是,由于單個錯誤可能會產(chǎn)生很大的后果,因此非常小的失敗概率都是不可接受的。
我們的目標(biāo)是設(shè)計一個“對手”,以便我們提前檢測這些故障(例如,在受控環(huán)境中)。如果攻擊者可以有效地識別給定模型的最壞情況輸入,則允許我們在部署模型之前捕獲罕見的故障情況。與圖像分類器一樣,針對弱攻擊進(jìn)行評估,很容易會在部署期間提供虛假的安全感。
我們?yōu)閺?qiáng)化學(xué)習(xí)agent的對抗性測試開發(fā)了兩種互補(bǔ)的方法。首先,使用無衍生優(yōu)化來直接最小化agent的預(yù)期回報。然后學(xué)習(xí)一種對抗價值函數(shù),該函數(shù)根據(jù)經(jīng)驗預(yù)測哪種情況最有可能導(dǎo)致agent失敗。再接著,使用此學(xué)習(xí)函數(shù)進(jìn)行優(yōu)化,將評估重點(diǎn)放在最有問題的輸入上。這些方法構(gòu)成了豐富且不斷增長的潛在算法空間的一小部分,我們對嚴(yán)格評估代理的未來發(fā)展感到興奮。
這兩種方法相比隨機(jī)測試已經(jīng)有了很大改進(jìn)。使用我們的方法,可以在幾分鐘內(nèi)檢測到需要花費(fèi)數(shù)天才能發(fā)現(xiàn)甚至完全未被發(fā)現(xiàn)的故障。我們還發(fā)現(xiàn),對抗性測試可能會發(fā)現(xiàn)agent中與隨機(jī)測試集的評估結(jié)果不同的行為。
特別是,使用對抗性環(huán)境構(gòu)造,我們發(fā)現(xiàn)執(zhí)行3D導(dǎo)航任務(wù)的agent一般會與人類級別的性能相匹配,但仍然無法在令人驚訝的簡單迷宮上完全找到目標(biāo)。我們的工作還強(qiáng)調(diào),我們需要設(shè)計能夠抵御自然故障的系統(tǒng),而不僅僅是針對對手。
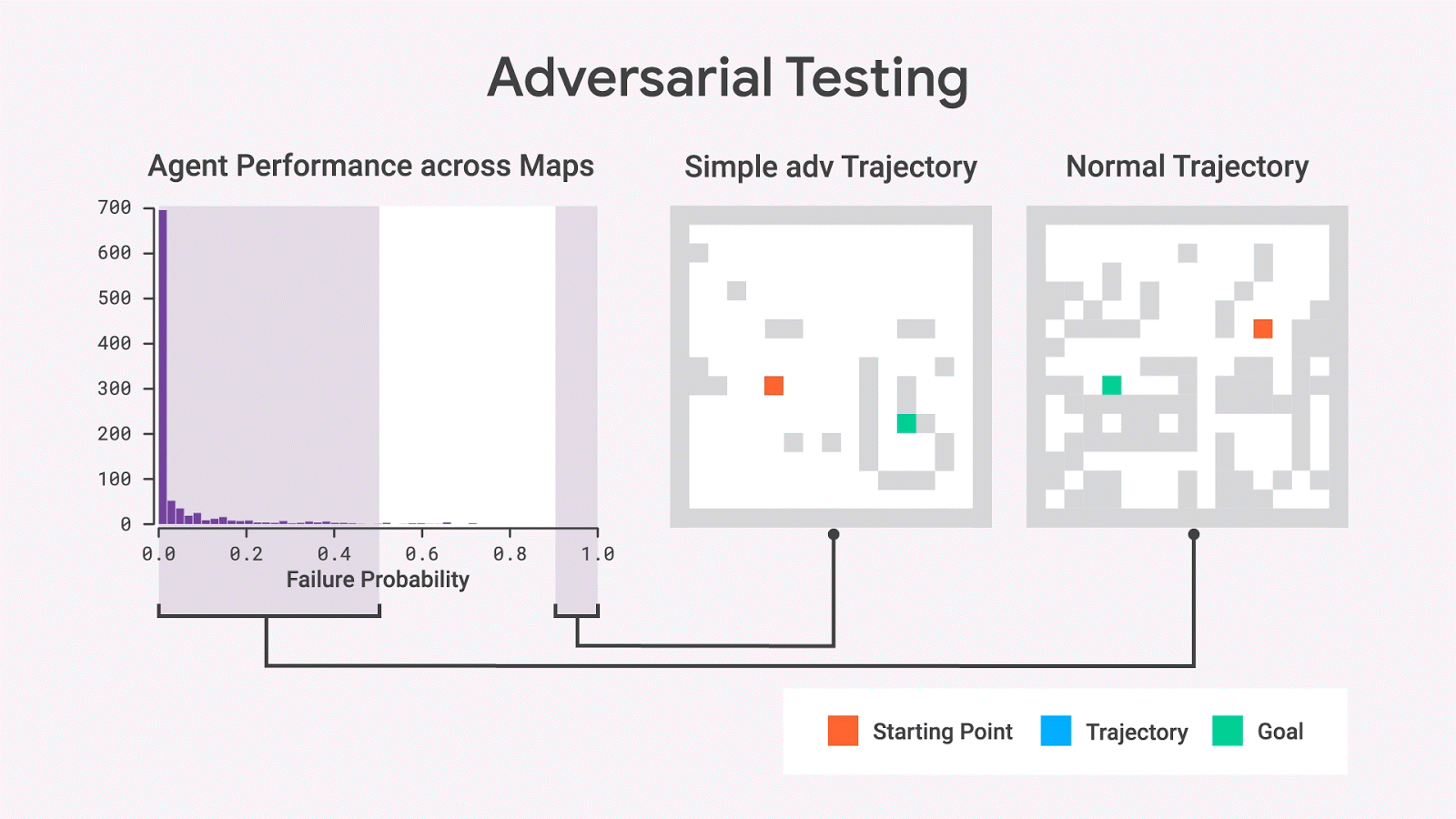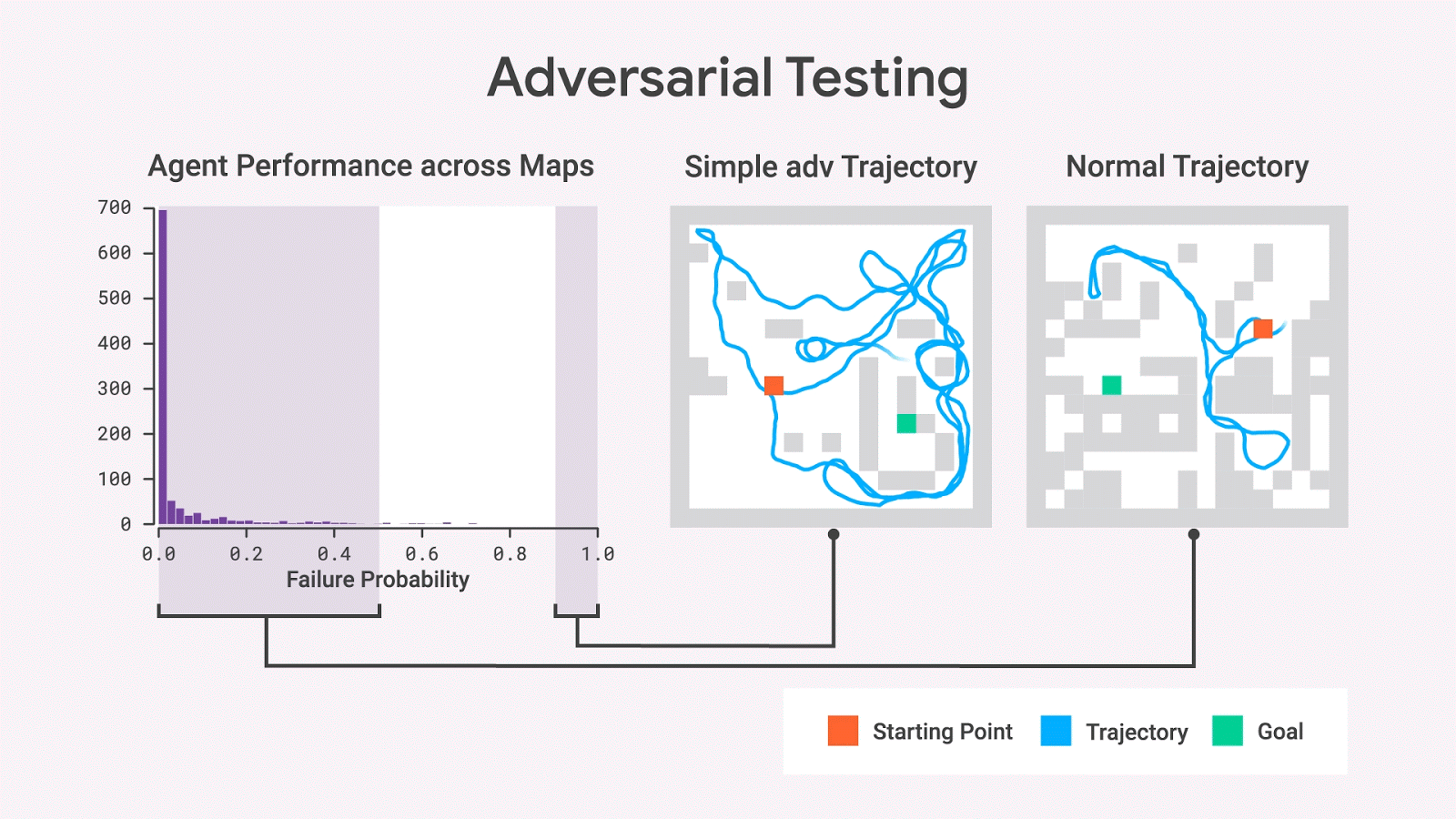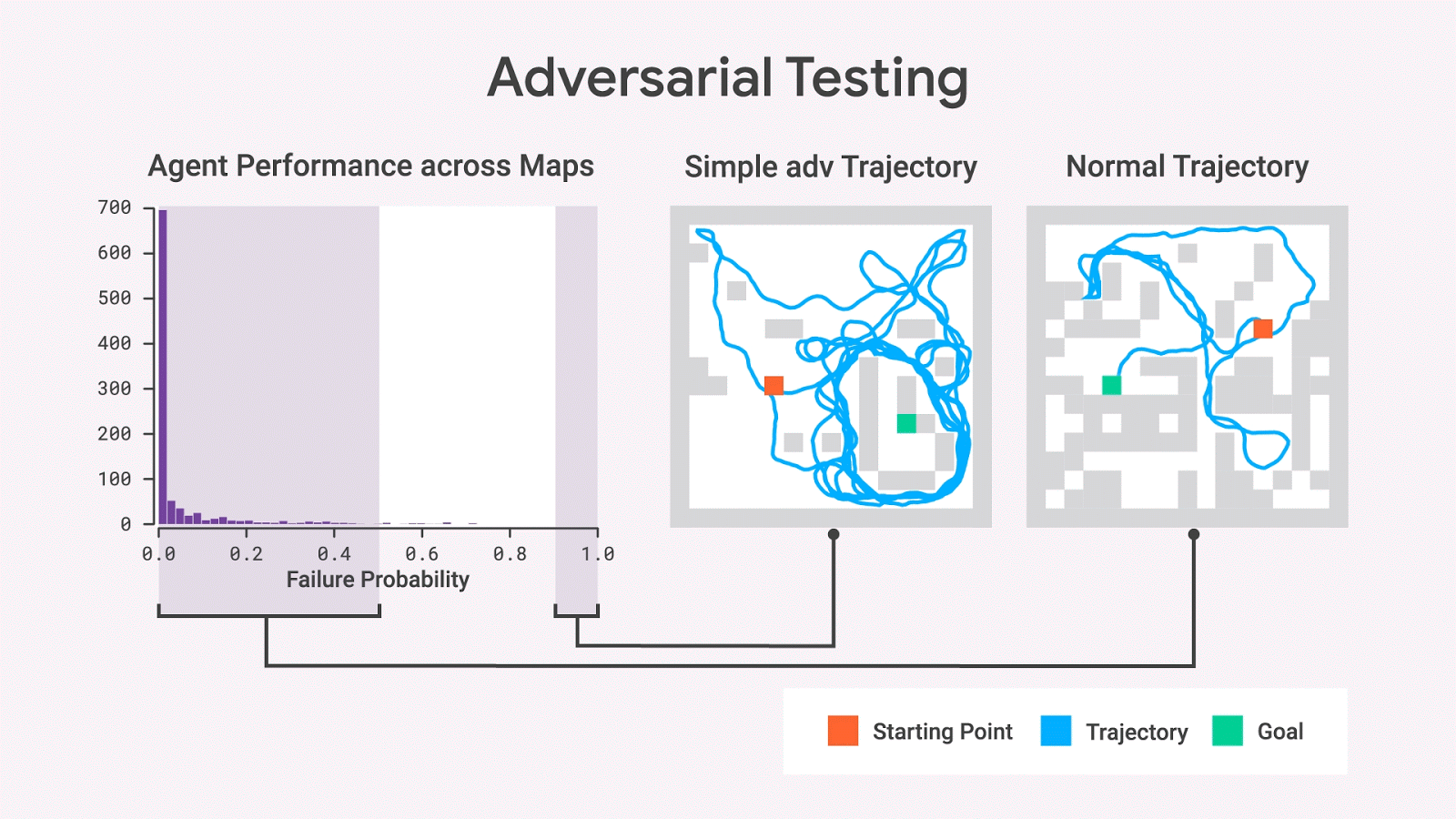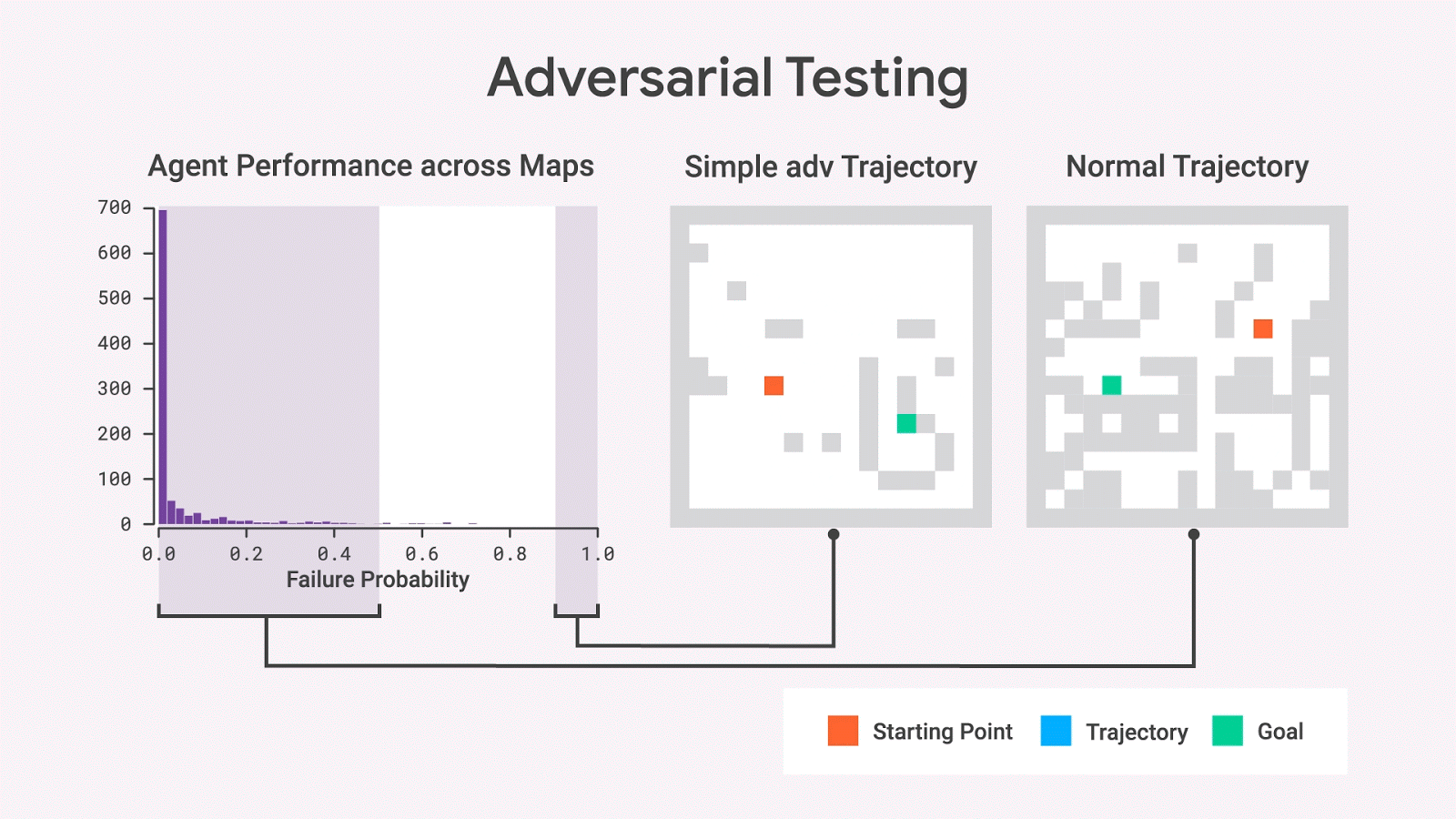
使用隨機(jī)抽樣,我們幾乎從不觀察具有高失敗概率的地圖,但是對抗性測試表明這樣的地圖確實存在。即使在移除了許多wall之后,這些地圖仍然保留了高失敗概率,從而產(chǎn)生比原始地圖更簡單的地圖。
訓(xùn)練規(guī)范一致的模型
對抗性測試旨在找到違反規(guī)范的反例。因此,它往往會導(dǎo)致高估模型與這些規(guī)范的一致性。在數(shù)學(xué)上,規(guī)范是必須在神經(jīng)網(wǎng)絡(luò)的輸入和輸出之間保持的某種關(guān)系。這可以采用某些鍵輸入和輸出參數(shù)的上限和下限的形式體現(xiàn)。
受此觀察的啟發(fā),一些研究人員,包括我們在DeepMind的團(tuán)隊,研究了與對抗性測試程序無關(guān)的算法(用于評估與規(guī)范的一致性)。這可以從幾何學(xué)上理解 - 我們可以約束在給定一組輸入的情況下,通過限制輸出空間來最嚴(yán)重地違反規(guī)范。如果此界限相對于網(wǎng)絡(luò)參數(shù)是可微分的并且可以快速計算,則可以在訓(xùn)練期間使用它。然后可以通過網(wǎng)絡(luò)的每個層傳播原始邊界框。
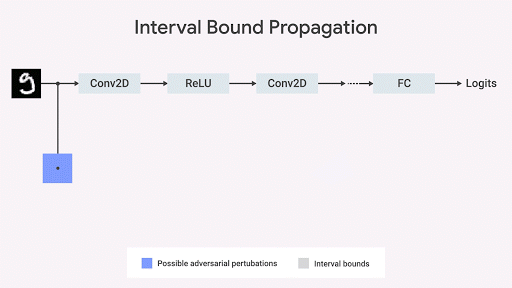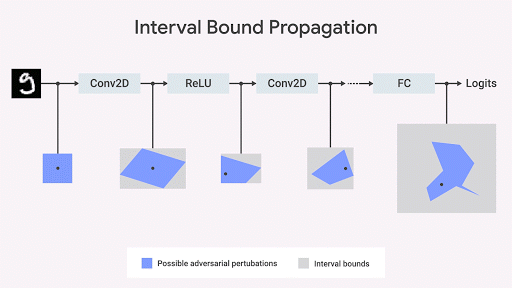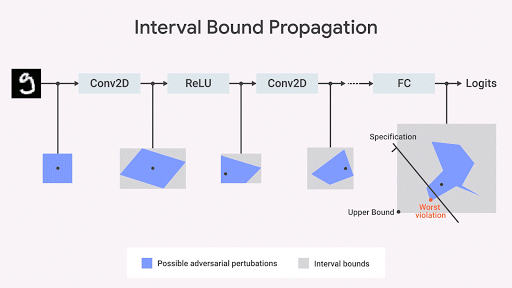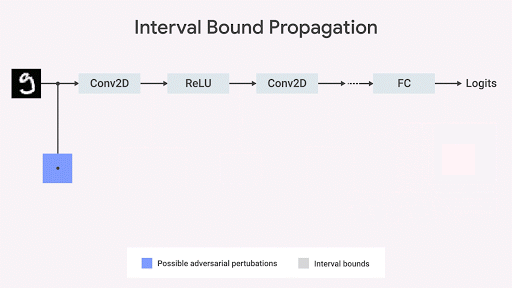
結(jié)果證明了區(qū)間界限傳播是快速、有效的,并且與先前的信念相反,可以獲得強(qiáng)有力的結(jié)果。特別是,我們證明它可以降低MNIST和CIFAR-10數(shù)據(jù)集上圖像分類中現(xiàn)有技術(shù)的錯誤率。
展望未來,下一個前沿將是學(xué)習(xí)正確的幾何抽象,以計算更嚴(yán)格的輸出空間過度近似值。我們還希望訓(xùn)練網(wǎng)絡(luò)與更復(fù)雜的規(guī)范一致,捕獲理想的行為,例如上面提到的不變性和與物理定律的一致性。
形式驗證
嚴(yán)格的測試和訓(xùn)練可以大大有助于構(gòu)建強(qiáng)大的機(jī)器學(xué)習(xí)系統(tǒng)。但是,沒有多少測試可以完全保證系統(tǒng)的行為符合我們的要求。在大規(guī)模模型中,由于輸入擾動的選擇特別多(天文數(shù)級別),因此列舉給定輸入集的所有可能輸出(例如,對圖像的無窮小擾動)根本難以處理。但是,與訓(xùn)練的情況一樣,我們可以通過在輸出集上設(shè)置幾何邊界來找到更有效的方法。形式驗證是DeepMind正在進(jìn)行的研究的主題。
機(jī)器學(xué)習(xí)社區(qū)已經(jīng)開發(fā)了幾個關(guān)于如何計算網(wǎng)絡(luò)輸出空間上的精確幾何邊界的有趣想法。我們的方法基于優(yōu)化和二元性,包括將驗證問題轉(zhuǎn)化為優(yōu)化問題。通過在優(yōu)化中使用二元性的思想,該問題變得易于計算。這導(dǎo)致額外的約束,其使用所謂的切割平面來細(xì)化由間隔界限傳播計算的邊界框。這種方法雖然合理但不完整:可能存在感興趣的屬性為真的情況,但此算法計算的界限不足以證明該屬性。但是,一旦我們獲得了約束邊界,這將正式保證不會侵犯屬性。下圖以圖形方式說明了該方法。
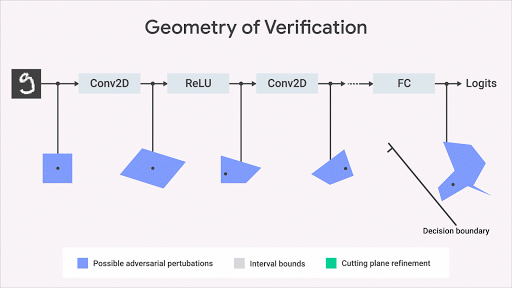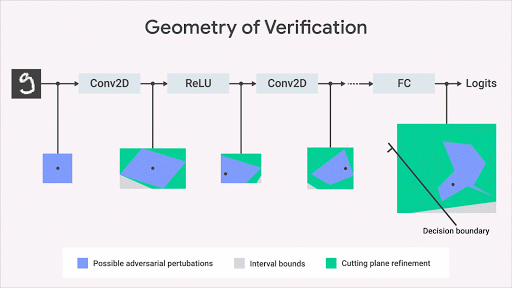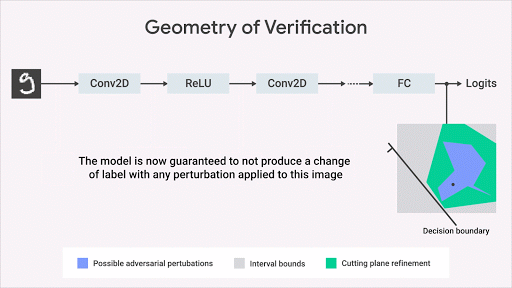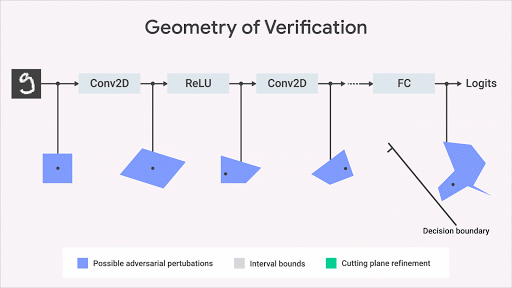
這種方法使我們能夠?qū)Ⅱ炞C算法的適用性擴(kuò)展到更一般的網(wǎng)絡(luò)(激活函數(shù),體系結(jié)構(gòu)),更一般性的規(guī)范和更復(fù)雜的深度學(xué)習(xí)模型(生成模型,神經(jīng)過程等)、超越對抗性魯棒性的規(guī)范 。
展望
在高風(fēng)險情況下部署機(jī)器學(xué)習(xí)帶來了獨(dú)特的挑戰(zhàn),需要做更多的工作來構(gòu)建自動化工具,以確保現(xiàn)實世界中的AI系統(tǒng)能夠做出“正確的事情”。特別是,我們對以下方向的進(jìn)展感到興奮:
學(xué)習(xí)對抗性評估和驗證:隨著AI系統(tǒng)的擴(kuò)展和復(fù)雜性提高,設(shè)計適合AI模型的對抗性評估和驗證算法將變得越來越困難。如果我們可以利用AI的強(qiáng)大功能來促進(jìn)評估和驗證,那么這個過程將大大加快,可實現(xiàn)自拓展。
開發(fā)用于對抗性評估和驗證的公開工具:為AI工程師和從業(yè)者提供易于使用的工具非常重要,這些工具可以在AI系統(tǒng)導(dǎo)致廣泛的負(fù)面影響之前闡明其可能的故障模式。這需要一定程度的對抗性評估和驗證算法的標(biāo)準(zhǔn)化。
擴(kuò)大對抗性示例的范圍:到目前為止,大多數(shù)關(guān)于對抗性示例的工作都集中在對小擾動(通常是圖像)的模型不變性上。這為開發(fā)對抗性評估,強(qiáng)大學(xué)習(xí)和驗證方法提供了極好的測試平臺。我們已經(jīng)開始探索與現(xiàn)實世界直接相關(guān)的屬性的替代規(guī)范,并對未來在這方面的研究感到興奮。
學(xué)習(xí)規(guī)范:在AI系統(tǒng)中捕獲“正確”行為的規(guī)范通常難以精確陳述。當(dāng)我們構(gòu)建能夠展示復(fù)雜行為并在非結(jié)構(gòu)化環(huán)境中行動的越來越智能的agent時,將需要構(gòu)建可以使用部分人類規(guī)范并從評估反饋中學(xué)習(xí)進(jìn)一步規(guī)范的系統(tǒng)。
-
編程
+關(guān)注
關(guān)注
88文章
3637瀏覽量
93981 -
人工智能
+關(guān)注
關(guān)注
1796文章
47666瀏覽量
240278
原文標(biāo)題:DeepMind:三種方法突破AI魯棒性極限
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
自動駕駛中常提的魯棒性是個啥?
嵌入式和人工智能究竟是什么關(guān)系?
魯棒性原理在控制系統(tǒng)中的應(yīng)用
深度學(xué)習(xí)模型的魯棒性優(yōu)化
魯棒性分析方法及其應(yīng)用
魯棒性在機(jī)器學(xué)習(xí)中的重要性
如何提高系統(tǒng)的魯棒性
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
帶阻濾波器在人工智能領(lǐng)域的應(yīng)用
MCUXpresso IDE下在線聯(lián)合調(diào)試雙核MCU工程的三種方法
FPGA在人工智能中的應(yīng)用有哪些?
智能駕駛大模型:有望顯著提升自動駕駛系統(tǒng)的性能和魯棒性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論