 深度學習模型壓縮與加速綜述
深度學習模型壓縮與加速綜述
目前在深度學習領域分類兩個派別,一派為學院派,研究強大、復雜的模型網絡和實驗方法,為了追求更高的性能;另一派為工程派,旨在將算法更穩定、高效的落地在硬件平臺上,效率是其追求的目標。復雜的模型固然具有更好的性能,但是高額的存儲空間、計算資源消耗是使其難以有效的應用在各硬件平臺上的重要原因。所以,卷積神經網絡日益增長的深度和尺寸為深度學習在移動端的部署帶來了巨大的挑戰,深度學習模型壓縮與加速成為了學術界和工業界都重點關注的研究領域之一。本文主要介紹深度學習模型壓縮和加速算法的三個方向,分別為加速網絡結構設計、模型裁剪與稀疏化、量化加速。
I. 加速網絡設計
分組卷積
分組卷積即將輸入的feature maps分成不同的組(沿channel維度進行分組),然后對不同的組分別進行卷積操作,即每一個卷積核至于輸入的feature maps的其中一組進行連接,而普通的卷積操作是與所有的feature maps進行連接計算。分組數k越多,卷積操作的總參數量和總計算量就越少(減少k倍)。然而分組卷積有一個致命的缺點就是不同分組的通道間減少了信息流通,即輸出的feature maps只考慮了輸入特征的部分信息,因此在實際應用的時候會在分組卷積之后進行信息融合操作,接下來主要講兩個比較經典的結構,ShuffleNet[1]和MobileNet[2]結構。
1) ShuffleNet結構:
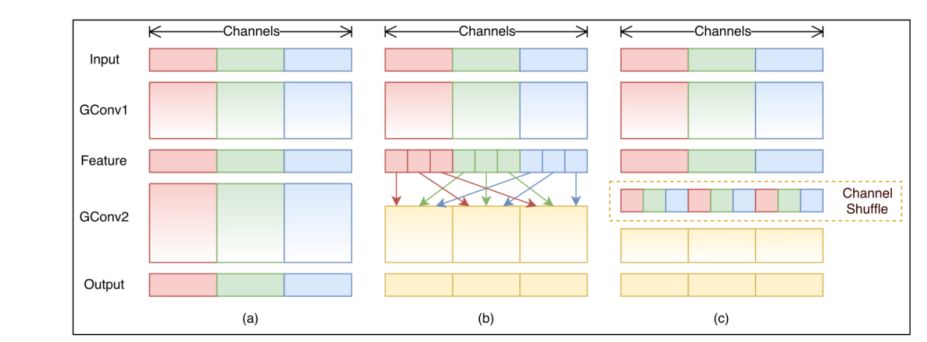
如上圖所示,圖a是一般的group convolution的實現效果,其造成的問題是,輸出通道只和輸入的某些通道有關,導致全局信息 流通不暢,網絡表達能力不足。圖b就是shufflenet結構,即通過均勻排列,把group convolution后的feature map按通道進行均勻混合,這樣就可以更好的獲取全局信息了。圖c是操作后的等價效果圖。在分組卷積的時候,每一個卷積核操作的通道數減少,所以可以大量減少計算量。
2)MobileNet結構:
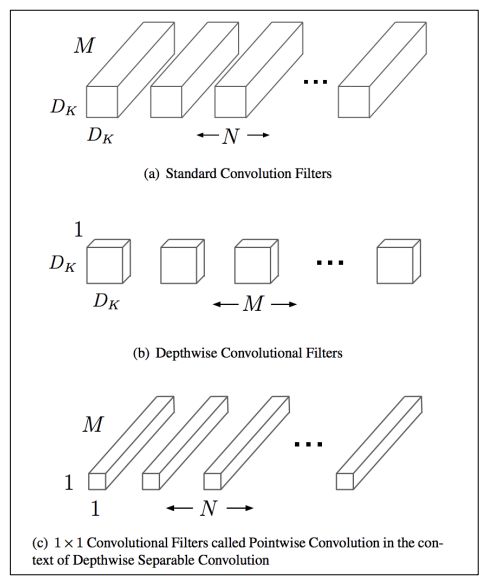
如上圖所示,mobilenet采用了depthwise separable convolutions的思想,采用depthwise (或叫channelwise)和1x1 pointwise的方法進行分解卷積。其中depthwise separable convolutions即對每一個通道進行卷積操作,可以看成是每組只有一個通道的分組卷積,最后使用開銷較小的1x1卷積進行通道融合,可以大大減少計算量。
分解卷積
分解卷積,即將普通的kxk卷積分解為kx1和1xk卷積,通過這種方式可以在感受野相同的時候大量減少計算量,同時也減少了參數量,在某種程度上可以看成是使用2k個參數模擬k*k個參數的卷積效果,從而造成網絡的容量減小,但是可以在較少損失精度的前提下,達到網絡加速的效果。

右圖是在圖像語義分割任務上取得非常好的效果的ERFNet[3]的主要模塊,稱為NonBottleNeck結構借鑒自ResNet[4]中的Non-Bottleneck結構,相應改進為使用分解卷積替換標準卷積,這樣可以減少一定的參數和計算量,使網絡更趨近于efficiency。
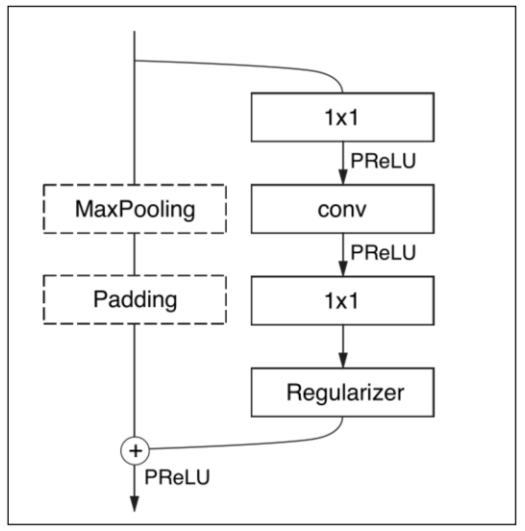
Bottleneck結構
右圖為ENet[5]中的Bottleneck結構,借鑒自ResNet中的Bottleneck結構,主要是通過1x1卷積進行降維和升維,能在一定程度上能夠減少計算量和參數量。其中1x1卷積操作的參數量和計算量少,使用其進行網絡的降維和升維操作(減少或者增加通道數)的開銷比較小,從而能夠達到網絡加速的目的。
C.ReLU[7]結構

C.ReLU來源于CNNs中間激活模式引發的。輸出節點傾向于是"配對的",一個節點激活是另一個節點的相反面,即其中一半通道的特征是可以通過另外一半通道的特征生成的。根據這個觀察,C.ReLU減少一半輸出通道(output channels)的數量,然后通過其中一半通道的特征生成另一半特征,這里使用 negation使其變成雙倍,最后通過scale操作使得每個channel(通道)的斜率和激活閾值與其相反的channel不同。
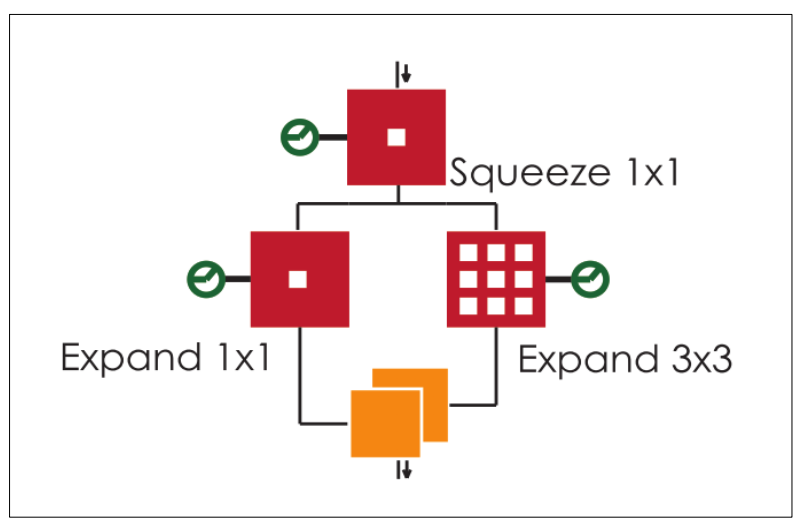
SqueezeNet[8]結構
SqueezeNet思想非常簡單,就是將原來簡單的一層conv層變成兩層:squeeze層+expand層,各自帶上Relu激活層。在squeeze層里面全是1x1的卷積kernel,數量記為S11;在expand層里面有1x1和3x3的卷積kernel,數量分別記為E11和E33,要求S11 < input map number。expand層之后將 1x1和3x3的卷積output feature maps在channel維度拼接起來。
神經網絡搜索[18]
神經結構搜索(Neural Architecture Search,簡稱NAS)是一種自動設計神經網絡的技術,可以通過算法根據樣本集自動設計出高性能的網絡結構,在某些任務上甚至可以媲美人類專家的水準,甚至發現某些人類之前未曾提出的網絡結構,這可以有效的降低神經網絡的使用和實現成本。
NAS的原理是給定一個稱為搜索空間的候選神經網絡結構集合,用某種策略從中搜索出最優網絡結構。神經網絡結構的優劣即性能用某些指標如精度、速度來度量,稱為性能評估,可以通過NAS自動搜索出高效率的網絡結構。
本節主要介紹了模型模型設計的思路,同時對模型的加速設計以及相關缺陷進行分析。總的來說,加速網絡模型設計主要是探索最優的網絡結構,使得較少的參數量和計算量就能達到類似的效果。
-
模型
+關注
關注
1文章
3305瀏覽量
49220 -
深度學習
+關注
關注
73文章
5513瀏覽量
121546
原文標題:深度學習模型壓縮與加速綜述
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論