") 嵌入式視覺應用于機器學習的設計方案
嵌入式視覺應用于機器學習的設計方案
目前嵌入式視覺領域最熱門的話題之一就是機器學習。機器學習涵蓋多個行業(yè)大趨勢,不僅在嵌入式視覺 (EV) ,而且在工業(yè)物聯(lián)網(wǎng) (IIoT) 和云計算中均發(fā)揮著極為顯赫的作用。對不熟悉機器學習的人來說,很多時候機器學習是通過神經(jīng)網(wǎng)絡創(chuàng)建和訓練來實現(xiàn)的。神經(jīng)網(wǎng)絡一語極為寬泛,包含相當數(shù)量的截然不同的子類別。這些子類別的名稱一般用于識別被實現(xiàn)的網(wǎng)絡的具體類型。這些網(wǎng)絡均在大腦皮層上建模,在大腦皮層中每個神經(jīng)元接收輸入、處理輸入并將其傳達給另一個神經(jīng)元。因此神經(jīng)元一般由輸入層、多個隱藏內(nèi)部層和一個輸出層組成。
圖1:簡單的神經(jīng)網(wǎng)絡
在最簡單的層面上,神經(jīng)元獲得輸入,施加權重給輸入,然后在加權輸入總和上執(zhí)行傳遞函數(shù)。結果隨后傳遞給隱藏層中的另一個層,或傳遞給輸出層。將一級的輸出傳遞給另一級且不構成循環(huán)的神經(jīng)網(wǎng)絡被稱為前饋神經(jīng)網(wǎng)絡 (FNN),而那些有反饋、內(nèi)含定向循環(huán)的神經(jīng)網(wǎng)絡則被稱為遞歸神經(jīng)網(wǎng)絡 (RNN)。在眾多機器學習應用中極為常用的神經(jīng)網(wǎng)絡是深度神經(jīng)網(wǎng)絡 (DNN)。這類神經(jīng)網(wǎng)絡擁有多個隱藏層,能實現(xiàn)更復雜的機器學習任務。為確定每層使用的權重和偏差值,需要對神經(jīng)網(wǎng)絡進行訓練。在訓練過程中,該神經(jīng)網(wǎng)絡施加有一定數(shù)量的正確輸入和錯誤輸入,并使用誤差函數(shù)教授網(wǎng)絡所需的性能。訓練深度神經(jīng)網(wǎng)絡可能需要龐大的數(shù)據(jù)集來正確訓練所需性能。
機器學習最重要的應用之一是嵌入式視覺領域,各類系統(tǒng)正在從視覺使能系統(tǒng)演進為視覺引導自動化系統(tǒng)。嵌入式視覺應用與其他更簡單的機器學習應用的區(qū)別在于它們采用二維輸入格式。因此,在機器學習實現(xiàn)方案中,通過使用稱為卷積神經(jīng)網(wǎng)絡 (CNN) 的網(wǎng)絡結構,因為它們能夠處理二維輸入。CNN 是一類前饋網(wǎng)絡,內(nèi)置多個卷積層和子采樣層以及一個單獨的全連通網(wǎng)絡,以執(zhí)行最終分類。鑒于 CNN 的復雜性,它們也歸屬深度學習類別。在卷積層中,輸入圖像被細分為一系列重疊的小模塊。在進行進一步的子采樣和其它階段之前,該卷積的結果先通過激活層創(chuàng)建激活圖,然后應用到最終的全連通網(wǎng)絡上。CNN 網(wǎng)絡的具體定義因?qū)崿F(xiàn)的網(wǎng)絡架構而異,但它一般會包含至少下列元:
●卷積 – 用于識別圖像中的特征
●修正線性單元(reLU)- 用于在卷積后創(chuàng)建激活圖的激活層
●最大池化 – 在層間進行子采樣
● 全連通 - 執(zhí)行最終分類
這些元中每一個元的權重通過訓練決定,同時 CNN 的優(yōu)勢之一在于訓練網(wǎng)絡相對容易。通過訓練生成權重需要龐大的圖像集,其中既有需要檢測的對象,也有偽圖像。這樣能讓我們?yōu)?CNN 創(chuàng)建所需的權重。由于訓練流程中所涉及的處理要求,訓練流程一般運行在提供高性能計算的云處理器上。
框 架
機器學習是一個復雜的課題,尤其是在每次不得不從頭開始,定義網(wǎng)絡、網(wǎng)絡架構和生成訓練算法的時候。為幫助工程師實現(xiàn)網(wǎng)絡和訓練網(wǎng)絡,有一些行業(yè)標準框架可供使用,例如 Caffe 和 Tensor Flow。Caffe 框架為機器學習開發(fā)人員提供各種庫、模型和 C++ 庫內(nèi)的預訓練權重,同時提供 Python 和 Matlab 綁定。該框架能讓用戶無需從頭開始即能創(chuàng)建網(wǎng)絡并訓練網(wǎng)絡,以開展所需的運算。為便于重復使用,Caffe 用戶能通過 model zoo 共享自己的模型。Model Zoo 提供多種能根據(jù)所需的專門任務實現(xiàn)和更新的模型。這些網(wǎng)絡和權重定義在 prototxt 文件中。在用于機器學習環(huán)境時,prototxt 文件是用于定義推斷引擎的文件。

圖2:定義網(wǎng)絡的 Prototxt 文件實例
實現(xiàn)嵌入式視覺和機器學習
基于可編程邏輯的解決方案,例如異構賽靈思 All Programmable Zynq -7000 SoC(片上系統(tǒng))和 Zynq UltraScale+ MPSoC 等多處理器片上系統(tǒng) (MPSoC) 越來越廣泛地用于嵌入式視覺應用。這些器件將可編程邏輯 (PL) 架構與處理系統(tǒng) (PS) 中的高性能ARM 內(nèi)核完美組合在一起。這種組合形成的系統(tǒng)擁有更快的響應速度,極為靈活便于未來修改,并且提供了高能效解決方案。對許多應用來說低時延決策與響應循環(huán)極為重要。例如視覺引導自主機器人,響應時間對避免給人員造成傷害、給環(huán)境造成破壞至關重要。縮短響應時間的具體方法是使用可編程邏輯實現(xiàn)視覺處理流水線和使用機器學習推斷引擎實現(xiàn)機器學習。在這方面使用可編程邏輯,與傳統(tǒng)解決方案相比可減少系統(tǒng)瓶頸問題。在使用基于 CPU/GPU 的方法時,運算每一階段都需要使用外部 DDR,因為圖像不能在有限內(nèi)部緩存內(nèi)的功能間傳遞。可編程邏輯方法使用內(nèi)部 ARM 按需提供緩存,允許采用流媒體方法。避免在 DDR 內(nèi)存儲中間元不僅可降低圖像處理的時延,而且還能降低功耗,甚至提高確定性,因為無需與其他系統(tǒng)資源共享訪問。
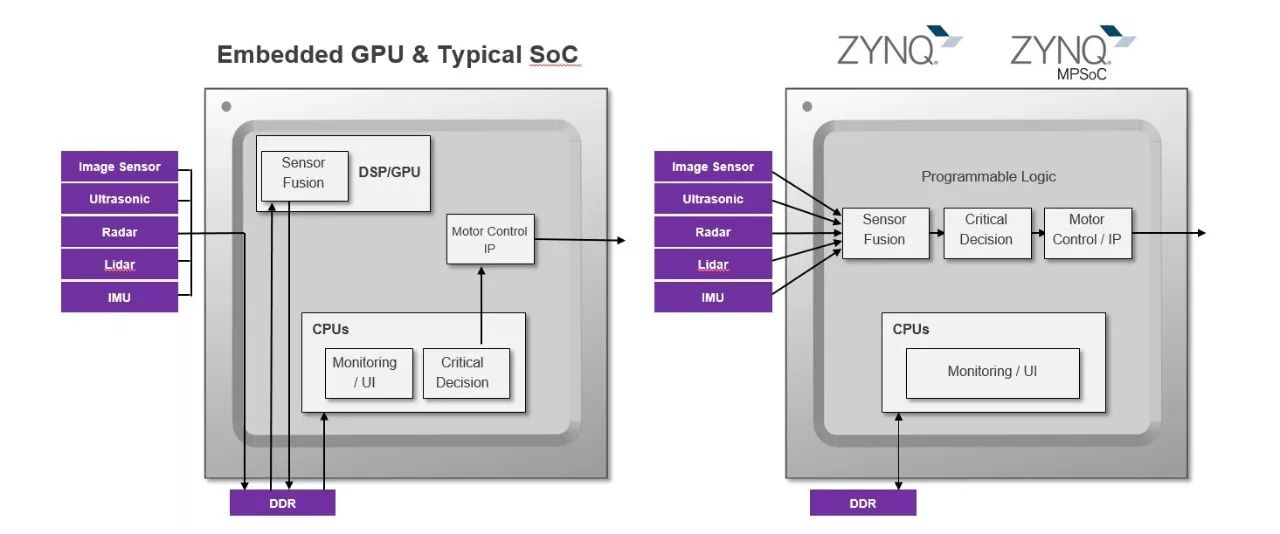
圖 3:可編程邏輯實現(xiàn)的好處
使用賽靈思提供的 reVISION 堆棧,在異構 SoC 中能輕松實現(xiàn)圖像處理算法和機器學習網(wǎng)絡。基于 SDSoC 工具,reVISION 能同時支持傳統(tǒng)圖像應用和機器學習應用。在 reVISION 內(nèi)部,同時支持 OpenVX 和 Caffe 框架。為支持 OpenVX 框架,內(nèi)核圖像處理功能可被加速到可編程邏輯中,以創(chuàng)建圖像處理流水線。同時機器學習推斷環(huán)境支持可編程邏輯中的硬件優(yōu)化庫,以實現(xiàn)執(zhí)行機器學習實現(xiàn)方案的推斷引擎。
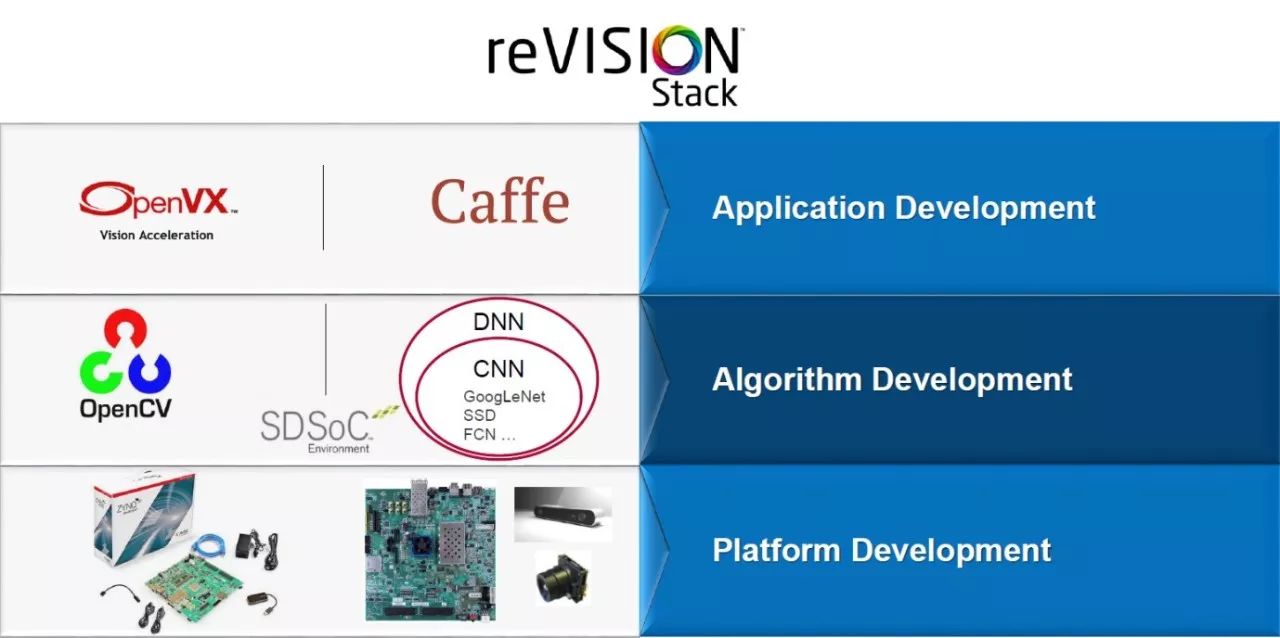
圖4:reVISION 堆棧
reVISION 提供與 Caffe 的集成,這樣實現(xiàn)機器學習推斷引擎就如同提供 prototxt 文件和經(jīng)訓練的權重一樣簡單,框架負責處理其余工作。然后使用 prototxt 文件對運行在處理系統(tǒng)上的 C/C++ 調(diào)度器進行配置,以加速可編程邏輯中硬件優(yōu)化庫上的神經(jīng)網(wǎng)絡推斷。可編程邏輯用于實現(xiàn)推斷引擎,內(nèi)含 Conv、ReLu 和 Pooling 等功能。
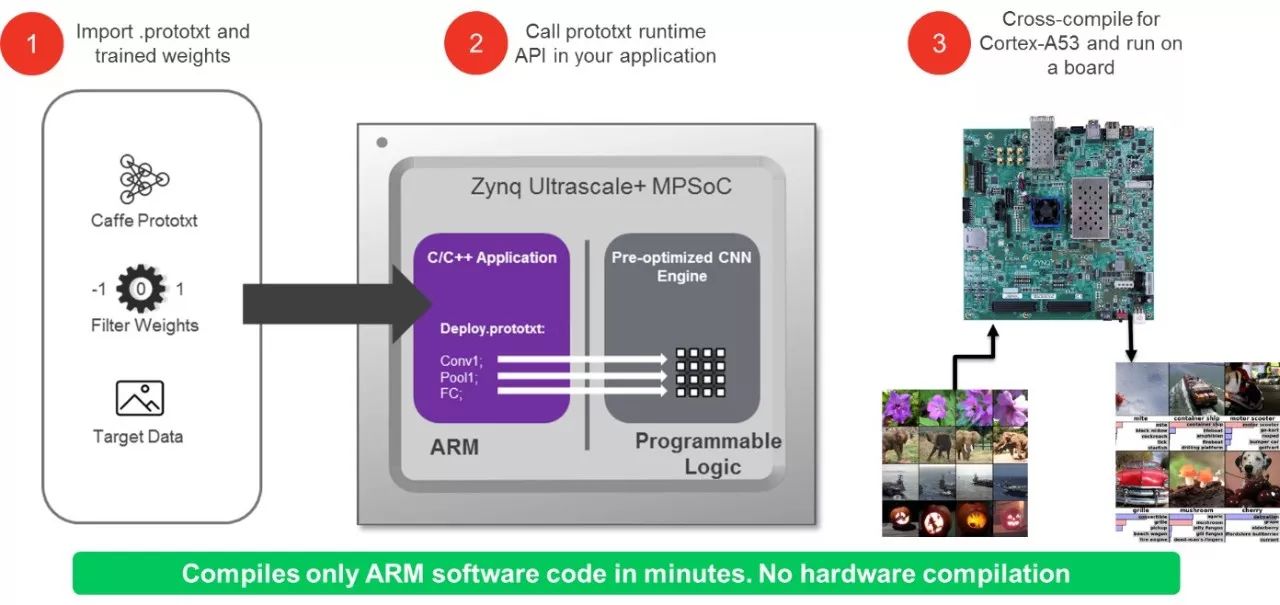
圖5:Caffe 流程集成
機器學習推斷引擎實現(xiàn)方案中使用的數(shù)值表示系統(tǒng)也對機器學習性能有重要作用。機器學習應用正越來越多地使用更高效的降精度定點數(shù)值系統(tǒng),例如 INT8 表達式。與傳統(tǒng)的浮點 32 (FP32) 方法相比,使用定點降精度數(shù)值系統(tǒng)不會造成顯著的精度下降。因為與浮點相比,定點數(shù)學在實現(xiàn)難度上也明顯更低,轉而采用 INT8 能在一些實現(xiàn)中提供更高效、更快速的解決方案。使用定點數(shù)值系統(tǒng)對在可編程邏輯解決方案中的實現(xiàn)方案而言相當理想,reVISION 在可編程邏輯中能與 INT8 表達式協(xié)同工作。這些 INT8 表達式方便在可編程邏輯中使用專門的 DSP 模塊。在使用相同的內(nèi)核權重時,這些 DSP 模塊架構能實現(xiàn)最多兩個并發(fā) INT8 乘法累加運算供執(zhí)行。這樣不僅能提供高性能實現(xiàn)方案,而且還能夠降低功耗。只要采用,可編程邏輯的靈活性也還便于實現(xiàn)進一步降精度定點數(shù)值表達系統(tǒng)。
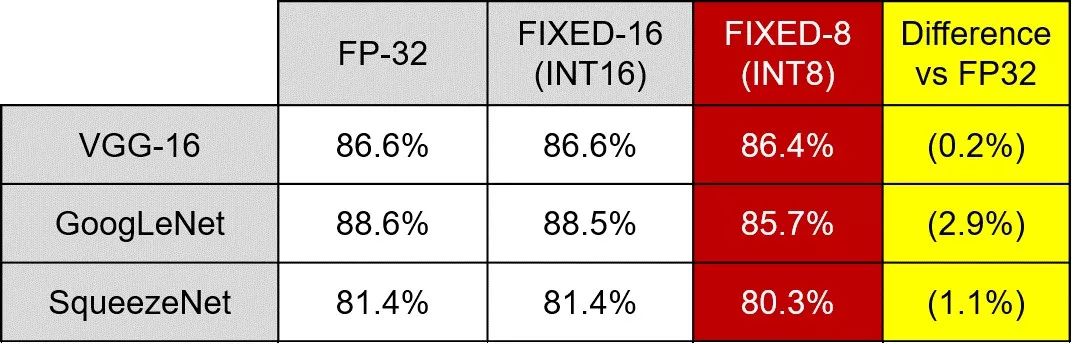
圖6:不同權重表達的網(wǎng)絡精度。
真 實 性 能
在真實環(huán)境中,reVISION 堆棧能帶來明顯優(yōu)勢。在嵌入式視覺應用中使用機器學習的應用實例之一,如車輛避碰系統(tǒng)。在 reVISION 中針對賽靈思 UltraScale+ MPSoC 并開發(fā)相關應用,使用 SDSoC 在可編程邏輯中按需為各項功能加速以達到優(yōu)化性能,能明顯改善響應性。在都用于實現(xiàn) GoogLeNet 解決方案的條件下,將 reVISION MPSoC 的響應時間與基于 GPU 的方法進行對比,差異相當明顯。reVISION 設計能在 2.7ms 內(nèi)發(fā)現(xiàn)潛在的碰撞事件并啟動車輛制動(使用的批量規(guī)模為 1),而基于 GPU 的方法則需要用時49ms-320ms(具體取決于其實現(xiàn)方案)(對大批量規(guī)模)。GPU 架構需要大批量規(guī)模才能實現(xiàn)合理的吞吐量,但會以犧牲響應時間為代價,而 Zynq 在批量規(guī)模為 1 的情況下也能以極低時延實現(xiàn)高性能。這種反應時間上的差異可以決定碰撞發(fā)生與否。
總 結
機器學習將繼續(xù)成為眾多應用的重要推動因素,尤其是在視覺導向機器人或所謂的“協(xié)作機器人”中。將處理器內(nèi)核與可編程邏輯結合的異構 SoC, 能創(chuàng)建非常高效、極具響應性且可重配置的解決方案。像reVISION 這樣的堆棧的推出,首次將可編程邏輯的好處帶給了更廣闊的開發(fā)者社群,同時還縮短了解決方案的開發(fā)時間。
-
神經(jīng)元
+關注
關注
1文章
363瀏覽量
18511 -
機器學習
+關注
關注
66文章
8441瀏覽量
133087 -
嵌入式視覺
+關注
關注
8文章
117瀏覽量
59173
發(fā)布評論請先 登錄
相關推薦
從神經(jīng)網(wǎng)絡入門嵌入式視覺應用的機器學習
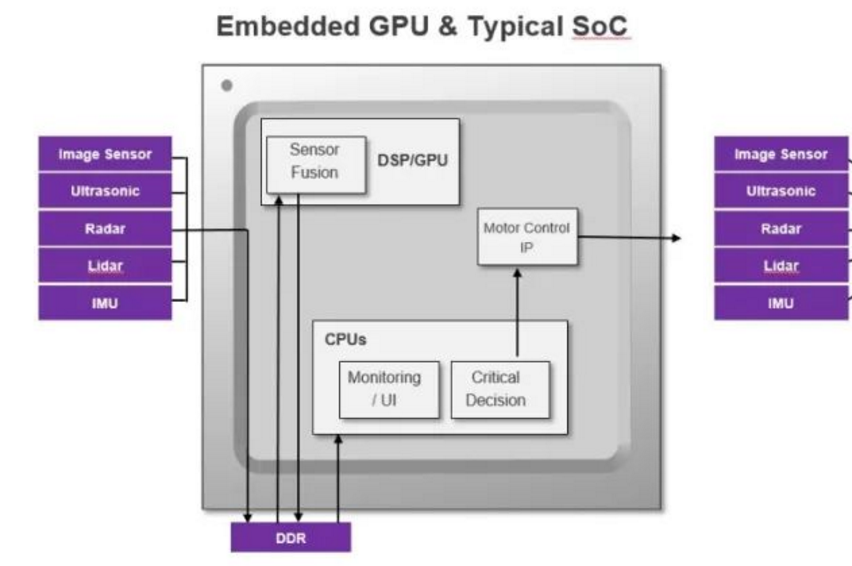
嵌入式視覺和網(wǎng)絡邊緣智能應用市場發(fā)展迅速
一種基于CPCI的嵌入式單板計算機電源的設計方案
一種基于CPCI的嵌入式單板計算機電源的設計方案
如何推動嵌入式視覺技術發(fā)展?
嵌入式機器視覺系統(tǒng)有什么特性?怎么優(yōu)化?
嵌入式系統(tǒng)電源設計方案
嵌入式機器視覺系統(tǒng)優(yōu)化研究
隨著嵌入式系統(tǒng)的高速發(fā)展 嵌入式機器視覺系統(tǒng)的應用也越來越廣泛






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論