眾所周知,大數(shù)據(jù)開(kāi)發(fā)和分析、機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘中,都離不開(kāi)各種開(kāi)源分布式系統(tǒng)。最常見(jiàn)的就是 Hadoop、Hive、Spark這三個(gè)框架了。最近不少朋友有問(wèn)到關(guān)于這些的問(wèn)題: 大廠里還有在用
2020-09-17 13:17:00 4018
4018 51單片機(jī)和arduino哪個(gè)好?arduino與51單片機(jī)比有哪些優(yōu)點(diǎn)?arduino與51單片機(jī)比有哪些區(qū)別?
2021-10-18 09:08:29
大數(shù)據(jù)基礎(chǔ)Hadoop311 的高可用HA安裝~踩坑記錄
2019-09-20 08:23:27
Hadoop教程:命令手冊(cè)
2020-03-18 11:28:02
`經(jīng)常會(huì)看到這樣的問(wèn)題:零基礎(chǔ)學(xué)習(xí)hadoop難不難?有的人回答說(shuō):零基礎(chǔ)學(xué)習(xí)hadoop,沒(méi)有想象的那么難,也沒(méi)有想象的那么容易。看到這樣的答案不免覺(jué)得有些尷尬,這個(gè)問(wèn)題算是白問(wèn)了,因?yàn)檫@個(gè)回答
2018-11-28 13:25:46
Hadoop是一個(gè)能夠?qū)Υ罅?b class="flag-6" style="color: red">數(shù)據(jù)進(jìn)行分布式處理的軟件框架,以一種可靠、高效、可伸縮的方式進(jìn)行數(shù)據(jù)處理,其有許多元素構(gòu)成,以下是其組成元素:1.Hadoop Common :Hadoop體系最底層的一
2018-05-16 16:04:57
`關(guān)于hadoop的分享此前一直都是零零散散的想到什么就寫(xiě)什么,整體寫(xiě)的比較亂吧。最近可能還算好的吧,畢竟花了兩周的時(shí)間詳細(xì)的寫(xiě)完的了hadoop從規(guī)劃到環(huán)境安裝配置等全部?jī)?nèi)容。寫(xiě)過(guò)程不是很難,最煩
2019-01-09 15:39:39
Hadoop中Join多種應(yīng)用
2020-03-31 11:32:58
Hadoop任務(wù)調(diào)度策略
2019-05-10 17:01:21
Hadoop是一個(gè)用Java編寫(xiě)的Apache開(kāi)源框架,允許使用簡(jiǎn)單的編程模型跨計(jì)算機(jī)集群分布式處理大型數(shù)據(jù)集。Hadoop框架工作的應(yīng)用程序在跨計(jì)算機(jī)集群提供分布式存儲(chǔ)和計(jì)算的環(huán)境中工作
2018-05-11 16:00:10
Hadoop集群環(huán)境搭建是很多學(xué)習(xí)hadoop學(xué)習(xí)者或者是使用者都必然要面對(duì)的一個(gè)問(wèn)題,網(wǎng)上關(guān)于hadoop集群環(huán)境搭建的博文教程也蠻多的。對(duì)于玩hadoop的高手來(lái)說(shuō)肯定沒(méi)有什么問(wèn)題,甚至可以說(shuō)
2018-10-12 15:51:49
Elasticsearch集成Hadoop最佳實(shí)踐 PDF 下載,Hadoop權(quán)威指南 大數(shù)據(jù)的存儲(chǔ)與分析PDF 下載
2019-05-08 17:01:00
Hadoop計(jì)數(shù)器的應(yīng)用以及數(shù)據(jù)清洗
2019-11-04 09:19:29
基金會(huì)所開(kāi)發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。換句話說(shuō)就是hadoop是一個(gè)能夠?qū)Υ罅?b class="flag-6" style="color: red">數(shù)據(jù)進(jìn)行分布式處理的軟件框架。Hadoopd之所謂會(huì)誕生,主要是由于進(jìn)入到大數(shù)據(jù)時(shí)代,計(jì)算機(jī)需要處理的數(shù)據(jù)量太過(guò)龐大。這時(shí)就需要
2018-09-18 11:58:18
hadoop發(fā)行版本之間的區(qū)別Hadoop是一個(gè)能夠?qū)Υ罅?b class="flag-6" style="color: red">數(shù)據(jù)進(jìn)行分布式處理的軟件框架。 Hadoop 以一種可靠、高效、可伸縮的方式進(jìn)行數(shù)據(jù)處理。Hadoop的發(fā)行版除了有Apache
2018-09-18 16:30:32
什么大的區(qū)別。我記得剛開(kāi)始接觸大數(shù)據(jù)這方面內(nèi)容的時(shí)候,也就這個(gè)問(wèn)題查閱了一些資料,在《FreeRCH大數(shù)據(jù)一體化開(kāi)發(fā)框架》的這篇說(shuō)明文檔中有就Hadoop和spark的區(qū)別進(jìn)行了簡(jiǎn)單的說(shuō)明,但我覺(jué)得解釋的也
2018-11-30 15:51:36
Hadoop主要是分布式計(jì)算和存儲(chǔ)的框架,其工作過(guò)程主要依賴(lài)于HDFS分布式存儲(chǔ)系統(tǒng)和Mapreduce分布式計(jì)算框架,以下是其工作過(guò)程:階段 1用戶(hù)/應(yīng)用程序可以通過(guò)指定以下項(xiàng)目來(lái)向Hadoop
2018-05-11 16:02:03
我們想象的要大,對(duì)新手而言選擇一個(gè)合適的hadoop版本就意味著上手更快!Hadoop是由Apache基金會(huì)所開(kāi)發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu),它最核心的設(shè)計(jì)就是HDFS和MapReduce。HDFS為海量的數(shù)據(jù)
2018-12-28 16:08:44
發(fā)行版,可單獨(dú)發(fā)布。獨(dú)立部署FreeRCH(大快大數(shù)據(jù)一體化開(kāi)發(fā)框架)時(shí),必需的組件。DK.HADOOP整合集成了NOSQL數(shù)據(jù)庫(kù),簡(jiǎn)化了文件系統(tǒng)與非關(guān)系數(shù)據(jù)庫(kù)之間的編程;DK.HADOOP改進(jìn)了集群
2018-10-15 15:59:43
數(shù)據(jù)挖掘:基于關(guān)聯(lián)挖掘的商品銷(xiāo)售分析
2020-06-09 08:32:36
當(dāng)前時(shí)代大數(shù)據(jù)炙手可熱,數(shù)據(jù)挖掘也是人人有所耳聞,但是關(guān)于數(shù)據(jù)挖掘更具體的算法,外行人了解的就少之甚少了。數(shù)據(jù)挖掘主要分為分類(lèi)算法,聚類(lèi)算法和關(guān)聯(lián)規(guī)則三大類(lèi),這三類(lèi)基本上涵蓋了目前商業(yè)市場(chǎng)對(duì)算法
2018-11-06 17:02:30
針對(duì)現(xiàn)有數(shù)據(jù)挖掘體系結(jié)構(gòu)松散揭合、算法運(yùn)行效率不高的問(wèn)題,提出了嵌入式數(shù)據(jù)挖掘模型。該模型實(shí)現(xiàn)了算法的組件化管理,并將整個(gè)數(shù)據(jù)挖掘流程控制在數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)中,在簡(jiǎn)化數(shù)據(jù)挖掘過(guò)程的同時(shí),大大提高了數(shù)據(jù)挖掘的效率。通過(guò)對(duì)幾種典型數(shù)據(jù)挖掘算法在銀行卡業(yè)務(wù)數(shù)據(jù)中的試驗(yàn),證實(shí)了該模型的有效性和實(shí)用性。
2020-03-11 06:36:59
ARM/DSP/FPGA的區(qū)別是什么?對(duì)比分析哪個(gè)好?
2021-11-05 06:08:20
CCD和CMOS的技術(shù)有什么區(qū)別?對(duì)比分析哪個(gè)好?
2021-06-04 06:19:53
`很多人都在問(wèn)學(xué)Java和學(xué)c語(yǔ)言哪個(gè)好?這個(gè)怎么說(shuō)呢?Java和c是兩個(gè)不同開(kāi)發(fā)平臺(tái)的基礎(chǔ)語(yǔ)言,應(yīng)用的領(lǐng)域也不同。先說(shuō)Java吧。Java是安卓開(kāi)發(fā)平臺(tái)的基礎(chǔ)語(yǔ)言,大家都知道安卓因其開(kāi)源特性備廣大
2016-01-04 14:11:27
,使得決策結(jié)果也會(huì)受到影響。所以,數(shù)據(jù)處理能力的高低對(duì)于高層領(lǐng)導(dǎo)決策者來(lái)說(shuō),是需要數(shù)據(jù)分析能力、數(shù)據(jù)挖掘能力、數(shù)據(jù)整合能力的統(tǒng)一協(xié)調(diào),因?yàn)?b class="flag-6" style="color: red">數(shù)據(jù)處理的結(jié)果不僅關(guān)系到?jīng)Q策的方向,更關(guān)系到未來(lái)的發(fā)展趨勢(shì)
2018-12-05 11:49:09
這幾年的大數(shù)據(jù)熱潮帶動(dòng)了一激活了一大批hadoop學(xué)習(xí)愛(ài)好者。有自學(xué)hadoop的,有報(bào)名培訓(xùn)班學(xué)習(xí)的。所有接觸過(guò)hadoop的人都知道,單獨(dú)搭建hadoop里每個(gè)組建都需要運(yùn)行環(huán)境、修改配置文件
2018-12-19 13:56:08
ide哪個(gè)版本好
2016-10-11 11:38:16
正態(tài)分布、chi-square分布、t分布、F分布等。三、機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘機(jī)器學(xué)習(xí)資料首推吳恩達(dá)的《斯坦福大學(xué)公開(kāi)課:機(jī)器學(xué)習(xí)課程》視頻。這20集視頻確實(shí)是好視頻,但對(duì)初學(xué)者來(lái)說(shuō)難度偏大。我有了一點(diǎn)機(jī)器
2017-09-01 11:05:58
想要自學(xué)云計(jì)算和數(shù)據(jù)挖掘想問(wèn)下這些方面有哪些內(nèi)容該從何開(kāi)始求大神們指教謝謝
2016-04-19 00:07:25
人工智能、數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)之間,主要有什么關(guān)系?
2020-03-16 11:35:54
人工智能、機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘的區(qū)別
2020-05-14 16:02:52
Hadoop是在分布式服務(wù)器集群上存儲(chǔ)海量數(shù)據(jù)并運(yùn)行分布式分析應(yīng)用的一個(gè)平臺(tái),其核心部件是HDFS與MapReduce。HDFS是一個(gè)分布式文件系統(tǒng),可對(duì)數(shù)據(jù)系統(tǒng)進(jìn)行分布式儲(chǔ)存讀取
2018-03-13 15:21:18
此類(lèi)大規(guī)模攻擊,阿里云平臺(tái)已可默認(rèn)攔截,降低漏洞對(duì)用戶(hù)的直接影響;如果企業(yè)希望徹底解決Hadoop安全漏洞,推薦企業(yè)使用阿里云MaxCompute (8年以上“零”安全漏洞)存儲(chǔ)、加工企業(yè)數(shù)據(jù);阿里云
2018-05-08 16:52:39
單片機(jī),PSoc和FPGA有什么區(qū)別和聯(lián)系?哪個(gè)前景好?求大蝦指教
2011-11-22 09:15:28
【作者】:賴(lài)興瑞;張東站;段江嬌;【來(lái)源】:《心智與計(jì)算》2010年01期【摘要】:股票價(jià)格行為數(shù)據(jù)挖掘激發(fā)了計(jì)算機(jī)科學(xué)、機(jī)器學(xué)習(xí)及其他領(lǐng)域研究的廣泛關(guān)注。然而,由于股票價(jià)格本身的不確定性和股市
2010-04-24 09:56:07
` 大數(shù)據(jù)這個(gè)詞也許幾年前你聽(tīng)著還會(huì)覺(jué)得陌生,但我相信你現(xiàn)在聽(tīng)到hadoop這個(gè)詞的時(shí)候你應(yīng)該都會(huì)覺(jué)得“熟悉”!越來(lái)越發(fā)現(xiàn)身邊從事hadoop開(kāi)發(fā)或者是正在學(xué)習(xí)hadoop的人變多了。作為一個(gè)
2018-12-26 15:02:33
,挖掘數(shù)據(jù)定義:基于前面的查詢(xún)數(shù)據(jù)進(jìn)行數(shù)據(jù)挖掘,來(lái)滿(mǎn)足高級(jí)別的數(shù)據(jù)分析需求。特點(diǎn)和挑戰(zhàn):算法復(fù)雜,并且計(jì)算涉及的數(shù)據(jù)量和計(jì)算量都大。使用的產(chǎn)品:R,HadoopMahout
2018-06-11 16:41:53
框架、Yarn集群資源管理和調(diào)度平臺(tái)、hdfs分布式文件系統(tǒng)、hive數(shù)據(jù)倉(cāng)庫(kù)、HBase實(shí)時(shí)分布式數(shù)據(jù)庫(kù)、Flume日志收集工具、sqoop數(shù)據(jù)庫(kù)ETL工具、zookeeper分布式協(xié)作服務(wù)、Mahout數(shù)據(jù)挖掘庫(kù)等。
2018-09-20 16:00:57
“學(xué)習(xí)hadoop需要什么基礎(chǔ)”這已經(jīng)不是一個(gè)新鮮的話題了,隨便上網(wǎng)搜索一下就能找出成百上千篇的文章在講學(xué)習(xí)hadoop需要掌握的基礎(chǔ)。再直接的一點(diǎn)的問(wèn)題就是——學(xué)Hadoop難嗎?用一句特別讓人
2018-09-13 13:37:51
Hadoop和Hive查詢(xún),基本就OK了。對(duì)于高級(jí)數(shù)據(jù)分析師,除了SQL以外,學(xué)習(xí)Python是很有必要的,用來(lái)獲取和處理數(shù)據(jù)都是事半功倍。當(dāng)然其他編程語(yǔ)言也是可以的。對(duì)于數(shù)據(jù)挖掘工程師,Hadoop得熟悉
2018-03-01 15:42:20
學(xué)習(xí)hadoop三節(jié)點(diǎn)完全夠用。DKhadoop三節(jié)點(diǎn)的發(fā)行版我記得是現(xiàn)在應(yīng)該也是免費(fèi)開(kāi)放下載的,之前專(zhuān)門(mén)就免費(fèi)版和付費(fèi)版有無(wú)區(qū)別的問(wèn)題問(wèn)過(guò)他們,免費(fèi)版本和付費(fèi)版本在后臺(tái)功能上沒(méi)有區(qū)別,所有權(quán)限都對(duì)
2019-01-25 14:50:28
上次我們分享了Spark與Hadoop計(jì)算模型的內(nèi)存問(wèn)題,今天山西思軟嵌入式學(xué)員為大家分享Spark與Hadoop計(jì)算模型的Spark比Hadoop更通用的問(wèn)題。 Spark提供的數(shù)據(jù)集操作類(lèi)型
2012-11-17 16:44:30
大數(shù)據(jù)初學(xué)者的福利——Hadoop快速入門(mén)教程
2020-04-15 11:38:59
機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘方法和應(yīng)用(經(jīng)典)
2023-09-26 07:56:49
;而深度學(xué)習(xí)使用獨(dú)立的層、連接,還有數(shù)據(jù)傳播方向,比如最近大火的卷積神經(jīng)網(wǎng)絡(luò)是第一個(gè)真正多層結(jié)構(gòu)學(xué)習(xí)算法,它利用空間相對(duì)關(guān)系減少參數(shù)數(shù)目以提高訓(xùn)練性能,讓機(jī)器認(rèn)知過(guò)程逐層進(jìn)行,逐步抽象,從而大幅度提升
2018-07-04 16:07:53
` 本帖最后由 eehome 于 2013-1-5 09:55 編輯
電容屏和電阻屏的區(qū)別_電容屏和電阻屏哪個(gè)好`
2012-08-20 12:40:17
非洲豬瘟檢測(cè)儀哪個(gè)品牌好?推薦山東風(fēng)途
一、儀器用途
非洲豬瘟病毒檢測(cè)是非洲豬瘟防控工作的重要舉措,意義重大。為進(jìn)一步提高非洲豬瘟病毒檢測(cè)結(jié)果準(zhǔn)確性,規(guī)范非洲豬瘟病毒診斷制品生產(chǎn)、經(jīng)營(yíng)
2021-03-18 14:44:34
農(nóng)藥殘留檢測(cè)儀哪個(gè)品牌好【云唐科器YT-NY18】近年來(lái),在許多食品安全事件中,果蔬農(nóng)業(yè)殘留超標(biāo)占據(jù)了相當(dāng)大的一部分。為更好地加強(qiáng)農(nóng)殘安全監(jiān)管,為提高農(nóng)殘安全檢測(cè)效率提供有力的技術(shù)支持,通常采用果蔬
2021-03-26 11:15:24
摘要:主要介紹了數(shù)據(jù)挖掘的產(chǎn)生、發(fā)展、定義和任務(wù),討論了常用的挖掘方法和工具,最后舉例介紹了數(shù)據(jù)挖掘的一些應(yīng)用.關(guān)鍵詞:數(shù)據(jù)挖掘;知識(shí)發(fā)現(xiàn);決策樹(shù)
Abstract:Th is
2009-01-08 21:23:12 12
12 負(fù)關(guān)聯(lián)規(guī)則反映了數(shù)據(jù)項(xiàng)之間的互斥關(guān)系,能提供很多有用的信息,在決策支持中起重要作用,但現(xiàn)行的挖掘算法主要是針對(duì)單一數(shù)據(jù)庫(kù)的挖掘,多數(shù)據(jù)庫(kù)中負(fù)關(guān)聯(lián)規(guī)則的挖掘還未
2009-03-20 14:27:127 中藥“效-效”關(guān)聯(lián)分析是中醫(yī)藥研究中最基本也是最重要的問(wèn)題,對(duì)藥效判斷具有重要意義。該文旨在利用數(shù)據(jù)挖掘技術(shù),從中藥方劑數(shù)據(jù)中自動(dòng)挖掘“效-效”相似關(guān)系,自動(dòng)歸納
2009-04-21 09:08:0931 本文以某汽車(chē)銷(xiāo)售服務(wù)有限公司為背景,設(shè)計(jì)了汽車(chē)銷(xiāo)售客戶(hù)關(guān)系管理系統(tǒng)。在該系統(tǒng)中,依據(jù)數(shù)據(jù)挖掘思想實(shí)現(xiàn)了對(duì)現(xiàn)有數(shù)據(jù)的分析、處理,并對(duì)客戶(hù)行為特征進(jìn)行分析,為管理
2009-06-18 10:20:2629 論數(shù)據(jù)挖掘中的個(gè)人數(shù)據(jù)隱私權(quán)問(wèn)題:【摘要】數(shù)據(jù)挖掘中的個(gè)人數(shù)據(jù)隱私權(quán)問(wèn)題是一個(gè)學(xué)科交叉的研究領(lǐng)域。主要探討數(shù)據(jù)挖掘對(duì)個(gè)人數(shù)據(jù)隱私權(quán)的影響,以及保護(hù)數(shù)據(jù)挖掘中
2009-10-10 15:15:367 本文提出了一種基于用戶(hù)指導(dǎo)的多關(guān)系關(guān)聯(lián)規(guī)則挖掘算法,借鑒有向圖的概念動(dòng)態(tài)的選擇最優(yōu)關(guān)鍵表,并利用元組ID 傳播的思想使多表間無(wú)需物理連接而能直接進(jìn)行關(guān)聯(lián)規(guī)則挖掘
2010-01-22 14:26:426 以決策樹(shù)數(shù)據(jù)挖掘分類(lèi)算法在金融客戶(hù)關(guān)系管理(CRM)中的應(yīng)用為例,進(jìn)行了數(shù)據(jù)挖掘的嘗試,從中發(fā)現(xiàn)企業(yè)產(chǎn)品的銷(xiāo)售規(guī)律和客戶(hù)群特征,從而提高CRM對(duì)市場(chǎng)活動(dòng)和銷(xiāo)售活動(dòng)的分
2010-08-02 12:18:080 用Linux和Apache Hadoop進(jìn)行云計(jì)算使用Linux 和 Hadoop 進(jìn)行分布式計(jì)算介紹Hadoop 框架.
2012-03-31 15:23:3412 hadoop大數(shù)據(jù)windows搭建環(huán)境
2017-09-08 08:52:444 數(shù)據(jù)挖掘就是從海量數(shù)據(jù)中找到隱藏的規(guī)則,數(shù)據(jù)分析一般要分析的目標(biāo)比較明確,數(shù)據(jù)統(tǒng)計(jì)則是單純的使用樣本來(lái)推斷總體。 主要區(qū)別: 數(shù)據(jù)分析的重點(diǎn)是觀察數(shù)據(jù),數(shù)據(jù)挖掘的重點(diǎn)是從數(shù)據(jù)中發(fā)現(xiàn)知識(shí)規(guī)則KDD
2017-09-28 19:20:0918 隨著智能設(shè)備的普及,全世界在2010 年的信息量已達(dá)ZB 級(jí)別,預(yù)計(jì)2020 年將,上升到35ZB,大數(shù)據(jù)時(shí)代已經(jīng)來(lái)臨,如何快速準(zhǔn)確地挖掘出潛在的價(jià)值信息變得越來(lái)越重要。數(shù)據(jù)挖掘技術(shù)已經(jīng)發(fā)展多年
2017-10-31 15:19:5015 隨著大數(shù)據(jù)的發(fā)展,Hadoop系統(tǒng)成為了大數(shù)據(jù)處理中的重要工具之一。在實(shí)際應(yīng)用中,Hadoop的I/O作制約系統(tǒng)性能的提升。通常Hadoop系統(tǒng)通過(guò)軟件壓縮數(shù)據(jù)來(lái)減少I(mǎi)/O操作,但是軟件壓縮速度較慢
2017-11-27 10:49:050 社交關(guān)系的數(shù)據(jù)挖掘一直是大圖數(shù)據(jù)研究領(lǐng)域中的熱門(mén)問(wèn)題。圖聚類(lèi)算法如SCAN( Structural clustering algorithm for networks)雖可迅速地從海量圖數(shù)據(jù)中獲得
2017-12-19 14:04:420 ,優(yōu)化存儲(chǔ)空間利用率。利用Hadoop大數(shù)據(jù)處理平臺(tái)下的分布式文件系統(tǒng)(HDFS)和非關(guān)系型數(shù)據(jù)庫(kù)HBase兩種數(shù)據(jù)管理模式,設(shè)計(jì)并實(shí)現(xiàn)一種可擴(kuò)展分布式重刪存儲(chǔ)系統(tǒng)。其中,MapReduce并行編程框架實(shí)現(xiàn)分布式并行重刪處理,HDFS負(fù)責(zé)重刪后的數(shù)據(jù)存儲(chǔ)
2017-12-22 14:19:500 Hadoop是一個(gè)能夠?qū)Υ罅?b class="flag-6" style="color: red">數(shù)據(jù)進(jìn)行分布式處理的軟件框架。 Hadoop 以一種可靠、高效、可伸縮的方式進(jìn)行數(shù)據(jù)處理。Hadoop 是可靠的,因?yàn)樗僭O(shè)計(jì)算元素和存儲(chǔ)會(huì)失敗,因此它維護(hù)多個(gè)工作數(shù)據(jù)副本,確保能夠針對(duì)失敗的節(jié)點(diǎn)重新分布處理。
2017-12-25 15:55:552664 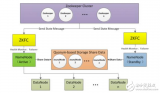
Hadoop得以在大數(shù)據(jù)處理應(yīng)用中廣泛應(yīng)用得益于其自身在數(shù)據(jù)提取、變形和加載(ETL)方面上的天然優(yōu)勢(shì)。Hadoop的分布式架構(gòu),將大數(shù)據(jù)處理引擎盡可能的靠近存儲(chǔ),對(duì)例如像ETL這樣的批處理操作相對(duì)合適,因?yàn)轭?lèi)似這樣操作的批處理結(jié)果可以直接走向存儲(chǔ)。
2017-12-25 16:46:1322756 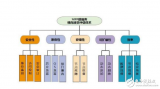
hbase和關(guān)系型數(shù)據(jù)庫(kù)的區(qū)別就是對(duì)于傳統(tǒng)數(shù)據(jù)庫(kù),增加列對(duì)于一個(gè)項(xiàng)目來(lái)講,改變是非常大的。但是對(duì)于nosql,插入列和刪除列,跟傳統(tǒng)數(shù)據(jù)庫(kù)里面的增加記錄和刪除記錄類(lèi)似
2017-12-27 15:51:3711095 
一、 hadoop是什么? (1)Hadoop是一個(gè)開(kāi)發(fā)和運(yùn)行處理大規(guī)模數(shù)據(jù)的軟件平臺(tái),可編寫(xiě)和運(yùn)行分布式應(yīng)用處理大規(guī)模數(shù)據(jù),是Appach的一個(gè)用java語(yǔ)言實(shí)現(xiàn)開(kāi)源軟件框架,實(shí)現(xiàn)在大量
2017-12-29 16:32:4039568 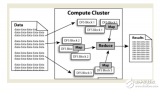
python 是一門(mén)動(dòng)態(tài)語(yǔ)言,hadoop是一個(gè)分布式計(jì)算的框架, 是用java寫(xiě)的。他們是兩個(gè)層次的東西。
2017-12-29 16:58:592609 數(shù)據(jù)挖掘與傳統(tǒng)意義上的統(tǒng)計(jì)學(xué)不同。統(tǒng)計(jì)學(xué)推斷是假設(shè)驅(qū)動(dòng)的,即形成假設(shè)并在數(shù)據(jù)基礎(chǔ)上驗(yàn)證他;數(shù)據(jù)挖掘是數(shù)據(jù)驅(qū)動(dòng)的,即自動(dòng)地從數(shù)據(jù)中提取模式和假設(shè)。數(shù)據(jù)挖掘的目標(biāo)是提取可以容易轉(zhuǎn)換成邏輯規(guī)則或可視化表示的定性模型,與傳統(tǒng)的統(tǒng)計(jì)學(xué)相比,更加以人為本。
2017-12-31 12:19:4318493 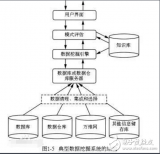
隨著數(shù)據(jù)量的爆炸式增長(zhǎng),我們需要借助一些有效的工具進(jìn)行數(shù)據(jù)挖掘工作,從而幫助我們更輕松地從巨大的數(shù)據(jù)集中找出關(guān)系、集群、模式、分類(lèi)信息等。借助這類(lèi)工具可以幫助我們做出最準(zhǔn)確的決策,為我們的業(yè)務(wù)獲取更多收益。
2017-12-31 12:26:5637049 
數(shù)據(jù)挖掘工程師多是通過(guò)對(duì)海量數(shù)據(jù)進(jìn)行挖掘,尋找數(shù)據(jù)的存在模式,從而通過(guò)數(shù)據(jù)挖掘來(lái)解決具體問(wèn)題。其更多是針對(duì)某一個(gè)具體的問(wèn)題,是以解決具體問(wèn)題為導(dǎo)向的。
2017-12-31 12:41:544565 本文比較全面的向大家介紹一下Hadoop命令,歡迎大家一起來(lái)學(xué)習(xí),希望通過(guò)本節(jié)的介紹大家能夠掌握一些常見(jiàn)Hadoop命令的使用方法。Hadoop命令以及常見(jiàn)Hadoop命令使用方法詳解如下
2018-01-02 10:17:278081 
.首先,基于概念分層理論給出了數(shù)據(jù)尺度劃分和數(shù)據(jù)尺度的定義以及多尺度數(shù)據(jù)集之間的上下層尺度數(shù)據(jù)集關(guān)系;其次,闡明了多尺度數(shù)據(jù)挖掘的定義、研究實(shí)質(zhì)和方法分類(lèi);最后,提出了多尺度數(shù)據(jù)挖掘算法框架,給出其理論基礎(chǔ),
2018-01-05 10:58:070 數(shù)據(jù)挖掘可以認(rèn)為是數(shù)據(jù)庫(kù)技術(shù)與機(jī)器學(xué)習(xí)的交叉,它利用數(shù)據(jù)庫(kù)技術(shù)來(lái)管理海量的數(shù)據(jù),并利用機(jī)器學(xué)習(xí)和統(tǒng)計(jì)分析來(lái)進(jìn)行數(shù)據(jù)分析。
2018-01-05 15:20:293883 機(jī)器學(xué)習(xí)是一門(mén)更加偏向理論性學(xué)科,其目的是為了讓計(jì)算機(jī)不斷學(xué)習(xí)找到接近目標(biāo)函數(shù)f的假設(shè)h。而數(shù)據(jù)挖掘則是使用了包括機(jī)器學(xué)習(xí)算法在內(nèi)的眾多知識(shí)的一門(mén)應(yīng)用學(xué)科,它主要是使用一系列處理方法挖掘數(shù)據(jù)背后的信息。
2018-01-05 19:02:3510381 關(guān)聯(lián)分析是一類(lèi)非常有用的數(shù)據(jù)挖掘方法,能從數(shù)據(jù)中挖掘出潛在的關(guān)聯(lián)關(guān)系。Apriori算法是一種最有影響的挖掘布爾關(guān)聯(lián)規(guī)則頻繁項(xiàng)集的算法。其核心是基于兩階段頻集思想的遞推算法。該關(guān)聯(lián)規(guī)則在分類(lèi)上屬
2018-02-04 09:37:563449 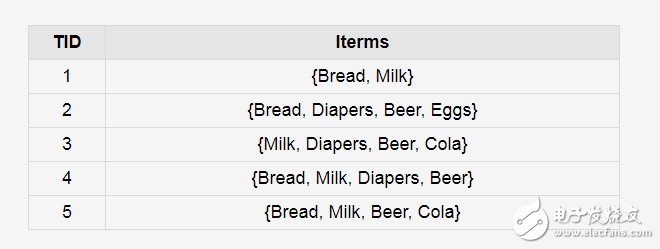
Apache Spark 是專(zhuān)為大規(guī)模數(shù)據(jù)處理而設(shè)計(jì)的快速通用的計(jì)算引擎。Hadoop是一個(gè)由Apache基金會(huì)所開(kāi)發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。用戶(hù)可以在不了解分布式底層細(xì)節(jié)的情況下,開(kāi)發(fā)分布式程序。
2018-02-12 14:41:3214450 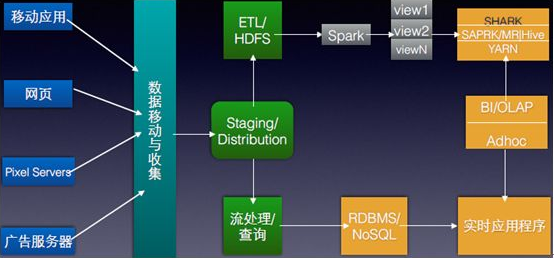
Hadoop在2006年開(kāi)始成為雅虎項(xiàng)目,隨后成為頂級(jí)的Apache開(kāi)源項(xiàng)目。它是一種通用的分布式處理形式,具有多個(gè)組件:
HDFS(分布式文件系統(tǒng)),它將文件以Hadoop本機(jī)格式存儲(chǔ),并在集群中并行化;
YARN,協(xié)調(diào)應(yīng)用程序運(yùn)行時(shí)的調(diào)度程序.
2018-06-04 12:48:006565 與Hadoop相關(guān)的幾個(gè)項(xiàng)目(包括 Parquet, Flume, Crunch, and Spark),你將可以通過(guò)本書(shū)挖掘Hadoop構(gòu)建分布式數(shù)據(jù)集的強(qiáng)大功能。
2019-03-01 14:44:579114 
和Hadoop的操作模型區(qū)別A:Hadoop:只提供了Map和Reduce兩種操作所有的作業(yè)都得轉(zhuǎn)換成Map和Reduce的操作。Spark:提供很多種的數(shù)據(jù)集操作類(lèi)型比如Transformations 包括
2019-07-18 09:42:391887 Hadoop的優(yōu)點(diǎn)
(1)Hadoop具有按位存儲(chǔ)和處理數(shù)據(jù)能力的高可靠性。
(2)Hadoop通過(guò)可用的計(jì)算機(jī)集群分配數(shù)據(jù),完成存儲(chǔ)和計(jì)算任務(wù),這些集群可以方便地?cái)U(kuò)展到數(shù)以千計(jì)的節(jié)點(diǎn)中,具有
2019-10-04 12:16:006476 傳值、傳址、傳引用的區(qū)別,哪個(gè)更高效?
2020-06-29 15:05:265370 )的算法。DTS采用啟發(fā)式思路挖掘能充分代表原序列中事件關(guān)系和時(shí)序規(guī)律的模式集合,并將最小描述長(zhǎng)度準(zhǔn)則應(yīng)用于模式挖掘,設(shè)計(jì)一種考慮事件關(guān)系和時(shí)序關(guān)系的編碼方案,以解決模式規(guī)模爆炸問(wèn)題。在真實(shí)日志數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表
2021-03-10 17:11:2812 數(shù)據(jù)湖的發(fā)展契機(jī),來(lái)源于近年來(lái)的AI熱潮和云計(jì)算、5G的發(fā)展,在日益發(fā)展的海量數(shù)據(jù)時(shí)代,數(shù)據(jù)已成為企業(yè)發(fā)展的核心資產(chǎn),通過(guò)構(gòu)建適用于大數(shù)據(jù)的底層架構(gòu),圍繞Hadoop提供語(yǔ)義一致性、數(shù)據(jù)治理和安全性
2021-08-24 16:22:32562 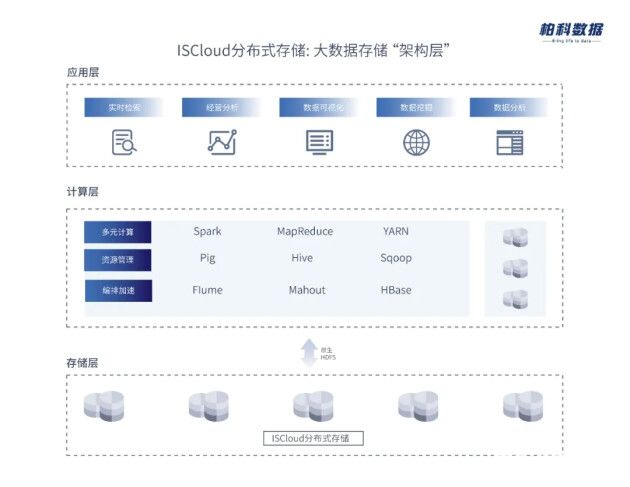
數(shù)據(jù)挖掘是指通過(guò)大量的程序,通過(guò)數(shù)據(jù)分析確定趨勢(shì)和模式,建立關(guān)系,從而解決業(yè)務(wù)問(wèn)題。換句話說(shuō),數(shù)據(jù)挖掘是從大量、不完整的、噪音的、模糊的、隨機(jī)的數(shù)據(jù)中提取出來(lái)的
2021-09-29 11:39:142911 這些天有很多涉及數(shù)據(jù)的術(shù)語(yǔ)。數(shù)據(jù)分析。數(shù)據(jù)挖掘。數(shù)據(jù)倉(cāng)庫(kù)。大數(shù)據(jù)。數(shù)據(jù)采集??。數(shù)據(jù)科學(xué)。數(shù)據(jù)抓取。數(shù)據(jù)提取。而這只是表面問(wèn)題。對(duì)于那些不熟悉過(guò)去十年左右數(shù)據(jù)的重大變化的人來(lái)說(shuō),它可能會(huì)變得一團(tuán)糟
2022-07-27 15:05:072044 摘要:本文首先介紹了微電子領(lǐng)域及該領(lǐng)域中半導(dǎo)體制造的發(fā)展現(xiàn)狀,然后分析了數(shù)據(jù)挖掘在半導(dǎo)體制造中應(yīng)用的必要性和可行性。最后重點(diǎn)討論數(shù)據(jù)挖掘技術(shù)在研究晶圓制造質(zhì)量異常問(wèn)題中的應(yīng)用,文章中給出了半導(dǎo)體
2023-07-18 15:43:200 機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘的對(duì)比與區(qū)別? 機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘是當(dāng)前互聯(lián)網(wǎng)行業(yè)中最熱門(mén)的領(lǐng)域之一。雖然它們之間存在一些對(duì)比和區(qū)別,但它們的共同點(diǎn)是研究如何有效地從海量數(shù)據(jù)中提取信息和洞察,并用于支持業(yè)務(wù)決策
2023-08-17 16:11:331013 用的數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)工具。 一、數(shù)據(jù)挖掘 數(shù)據(jù)挖掘是指從大量數(shù)據(jù)中自動(dòng)或半自動(dòng)地發(fā)現(xiàn)潛在的關(guān)系、規(guī)律或模式的過(guò)程。Python中有許多數(shù)據(jù)挖掘工具可供使用,以下是其中一些常用的工具: 1. NumPy和Pandas NumPy是一個(gè)Python庫(kù),用于處理數(shù)組和矩陣運(yùn)算。它可以用于執(zhí)
2023-08-17 16:29:38818 數(shù)據(jù)挖掘十大算法 數(shù)據(jù)挖掘是目前最熱門(mén)的技術(shù)和概念之一。數(shù)據(jù)挖掘是一種利用現(xiàn)代數(shù)據(jù)分析技術(shù)發(fā)現(xiàn)、提取和分析數(shù)據(jù)中有價(jià)值信息的過(guò)程。數(shù)據(jù)挖掘可以幫助人們發(fā)現(xiàn)數(shù)據(jù)背后的規(guī)律和趨勢(shì),從而為業(yè)務(wù)決策和優(yōu)化
2023-08-17 16:29:481592 數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)有什么關(guān)系 數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)是兩個(gè)不同的概念,但它們有一些重要的相似之處。這篇文章將詳細(xì)介紹數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)之間的關(guān)系以及它們?cè)诂F(xiàn)代數(shù)據(jù)科學(xué)中的作用。 一、數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)
2023-08-17 16:29:501822 數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)之間的關(guān)系 數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)是兩個(gè)非常相關(guān)的領(lǐng)域,但是在很多情況下它們被誤解為是同一種東西。事實(shí)上,數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)有很多的不同之處,但也有很多的相似之處。在本文中,我們將探討
2023-08-17 16:29:542004 機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘的區(qū)別 , 機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘的關(guān)系 機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘是如今熱門(mén)的領(lǐng)域。隨著數(shù)據(jù)規(guī)模的不斷擴(kuò)大,越來(lái)越多的人們認(rèn)識(shí)到數(shù)據(jù)分析的重要性。但是,機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘在實(shí)踐中常常被混淆
2023-08-17 16:30:001369
 電子發(fā)燒友App
電子發(fā)燒友App









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論