 電子發(fā)燒友App
電子發(fā)燒友App


基于深度學(xué)習(xí)的場(chǎng)景分割算法研究綜述
來(lái)自《計(jì)算機(jī)研究與發(fā)展》 ,作者張 蕊等
場(chǎng)景分割的目標(biāo)是判斷場(chǎng)景圖像中每個(gè)像素的類別.場(chǎng)景分割是計(jì)算機(jī)視覺領(lǐng)域重要的基本問(wèn)題之一,對(duì)場(chǎng)景圖像的分析和理解具有重要意義,同時(shí)在自動(dòng)駕駛、視頻監(jiān)控、增強(qiáng)現(xiàn)實(shí)等諸多領(lǐng)域具有廣泛的應(yīng)用價(jià)值.近年來(lái),基于深度學(xué)習(xí)的場(chǎng)景分割技術(shù)取得了突破性進(jìn)展,與傳統(tǒng)場(chǎng)景分割算法相比獲得分割精度的大幅度提升.首先分析和描述場(chǎng)景分割問(wèn)題面臨的3個(gè)主要難點(diǎn):分割粒度細(xì)、尺度變化多樣、空間相關(guān)性強(qiáng);其次著重介紹了目前大部分基于深度學(xué)習(xí)的場(chǎng)景分割算法采用的“卷積-反卷積”結(jié)構(gòu);在此基礎(chǔ)上,對(duì)近年來(lái)出現(xiàn)的基于深度學(xué)習(xí)的場(chǎng)景分割算法進(jìn)行梳理,介紹針對(duì)場(chǎng)景分割問(wèn)題的3個(gè)主要難點(diǎn),分別提出基于高分辨率語(yǔ)義特征圖、基于多尺度信息和基于空間上下文等場(chǎng)景分割算法;簡(jiǎn)要介紹常用的場(chǎng)景分割公開數(shù)據(jù)集;最后對(duì)基于深度學(xué)習(xí)的場(chǎng)景分割算法的研究前景進(jìn)行總結(jié)和展望.
場(chǎng)景分割[1]是計(jì)算機(jī)視覺領(lǐng)域一個(gè)基本而重要的問(wèn)題.相比一般的圖像分割,場(chǎng)景分割針對(duì)場(chǎng)景圖像.場(chǎng)景圖像[2]是指面向某個(gè)空間的圖像,通常具有一定的透視形變,且其中包含的視覺要素?cái)?shù)量較多.場(chǎng)景分割算法的目標(biāo)是對(duì)于場(chǎng)景圖像中的每個(gè)像素判斷其所屬類別。
場(chǎng)景分割算法對(duì)于圖像分析和場(chǎng)景理解具有極大的幫助.場(chǎng)景分割算法可以綜合完成場(chǎng)景圖像中視覺要素的識(shí)別、檢測(cè)和分割,提高圖像理解的效率和準(zhǔn)確率.同時(shí)由于場(chǎng)景分割結(jié)果精確到像素級(jí),相比圖像分類和目標(biāo)檢測(cè)[3],場(chǎng)景分割結(jié)果可以提供更加豐富的關(guān)于圖像局部和細(xì)節(jié)的信息.此外,場(chǎng)景分割算法具有廣泛的應(yīng)用價(jià)值和長(zhǎng)遠(yuǎn)的發(fā)展前景.例如在自動(dòng)駕駛技術(shù)中,場(chǎng)景分割算法可以通過(guò)對(duì)道路、車輛和行人的分割輔助自動(dòng)駕駛系統(tǒng)判斷道路情況;在視頻監(jiān)控技術(shù)中,場(chǎng)景分割算法可以通過(guò)對(duì)監(jiān)控目標(biāo)的分割協(xié)助進(jìn)行目標(biāo)的分析和跟蹤;在增強(qiáng)現(xiàn)實(shí)技術(shù)中,場(chǎng)景分割算法可以通過(guò)分割場(chǎng)景中的前景和背景輔助實(shí)現(xiàn)多種增強(qiáng)現(xiàn)實(shí)效果.
作為計(jì)算機(jī)視覺領(lǐng)域的一個(gè)經(jīng)典任務(wù),場(chǎng)景分割極具挑戰(zhàn)性.如圖2所示,場(chǎng)景分割的難點(diǎn)可概括為3個(gè)方面:1)分割粒度細(xì).場(chǎng)景分割結(jié)果需要精確到像素級(jí)別,且需要預(yù)測(cè)精確的分割邊界.2)尺度變化多樣.由于場(chǎng)景圖像中通常包含多種類別的視覺要素,不同類別的視覺要素往往存在尺度差異,同時(shí)由于場(chǎng)景圖像存在透視形變,相同類別的視覺要素也會(huì)呈現(xiàn)出不同尺度.3)空間相關(guān)性強(qiáng).場(chǎng)景圖像中的視覺要素存在復(fù)雜而緊密的空間相關(guān)關(guān)系,這些空間相關(guān)關(guān)系對(duì)視覺要素的識(shí)別和分割具有極大幫助.
場(chǎng)景分割問(wèn)題是傳統(tǒng)圖像分割問(wèn)題的子問(wèn)題,近年來(lái)受到越來(lái)越多國(guó)內(nèi)外研究人員的關(guān)注.在研究初期,研究人員使用傳統(tǒng)的圖像分割算法解決場(chǎng)景分割問(wèn)題,包括基于閾值[4]、基于區(qū)域提取[5-6]、基于邊緣檢測(cè)[7]、基于概率圖模型[8-10]和基于像素或超像素分類[11]的分割算法.這些傳統(tǒng)分割算法通常使用人工設(shè)計(jì)的圖像特征[12],與語(yǔ)義概念之間存在著語(yǔ)義鴻溝,因此制約了傳統(tǒng)圖像分割算法的性能.
近年來(lái),深度學(xué)習(xí)的快速發(fā)展為場(chǎng)景分割帶來(lái)了新的解決思路.深度學(xué)習(xí)算法通過(guò)構(gòu)建多層神經(jīng)網(wǎng)絡(luò),利用多層變換模仿人腦的機(jī)制來(lái)分析和理解圖像.深度學(xué)習(xí)算法可以從大規(guī)模數(shù)據(jù)中學(xué)習(xí)逐漸抽象的層次化特征,從而建立場(chǎng)景圖像到語(yǔ)義類別的映射.深度學(xué)習(xí)是近年來(lái)機(jī)器學(xué)習(xí)領(lǐng)域最令人矚目的方向之一,在語(yǔ)音識(shí)別、計(jì)算機(jī)視覺、自然語(yǔ)言處理等多個(gè)領(lǐng)域均獲得了突破性進(jìn)展[13].基于深度學(xué)習(xí)的場(chǎng)景分割算法同樣取得了巨大突破.這些算法主要基于“卷積-反卷積”結(jié)構(gòu),包括全卷積網(wǎng)絡(luò)[14]和反卷積網(wǎng)絡(luò)[15-16]兩大類.“卷積-反卷積”結(jié)構(gòu)可以建立從原始圖像到分割結(jié)果的映射,并且可以進(jìn)行端到端的訓(xùn)練.相比傳統(tǒng)圖像分割算法,基于深度學(xué)習(xí)的場(chǎng)景分割算法實(shí)現(xiàn)了分割精度的大幅度提升.在此基礎(chǔ)上,研究人員針對(duì)場(chǎng)景分割問(wèn)題的難點(diǎn)和挑戰(zhàn),提出了多種基于深度學(xué)習(xí)的場(chǎng)景分割算法并不斷提高算法性能.其中,針對(duì)分割粒度細(xì)的問(wèn)題,研究人員提出了基于高分辨率語(yǔ)義特征圖的場(chǎng)景分割算法,通過(guò)提高特征圖的分辨率獲得更高精度的分割結(jié)果;針對(duì)尺度變化多樣的問(wèn)題,研究人員提出了基于多尺度信息的場(chǎng)景分割算法,通過(guò)捕捉場(chǎng)景圖像中的多尺度信息提升算法的分割精度;針對(duì)空間相關(guān)性強(qiáng)的問(wèn)題,研究人員提出了基于空間上下文信息的場(chǎng)景分割算法,通過(guò)捕捉場(chǎng)景圖像中的空間上下文和相關(guān)關(guān)系提升算法的分割精度.
在國(guó)內(nèi)外的研究成果中有許多對(duì)圖像分割進(jìn)行綜述的文獻(xiàn),可以分為兩大類:1)概述傳統(tǒng)圖像分割算法的綜述[17-23],介紹了基于閾值、區(qū)域提取、邊緣檢測(cè)等利用圖像特征的傳統(tǒng)圖像分割算法.2)側(cè)重介紹基于深度學(xué)習(xí)的圖像分割算法的綜述[24-27].例如文獻(xiàn)[24]側(cè)重介紹不同圖像分割算法使用的深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu);文獻(xiàn)[25]將上百種基于深度學(xué)習(xí)的圖像分割算法分為10個(gè)大類進(jìn)行概述;文獻(xiàn)[26-27]以圖像標(biāo)注的粒度作為分類標(biāo)準(zhǔn),分別介紹了全監(jiān)督和弱監(jiān)督的圖像分割算法.但這些文獻(xiàn)都是對(duì)通用的圖像分割算法進(jìn)行綜述,目前并沒有針對(duì)場(chǎng)景分割的算法綜述.與這些綜述不同,本文介紹的算法針對(duì)圖像分割中的場(chǎng)景分割子問(wèn)題,且主要介紹基于深度學(xué)習(xí)的算法.本文以算法針對(duì)的場(chǎng)景分割問(wèn)題的3個(gè)難點(diǎn)作為分類依據(jù),梳理近年來(lái)出現(xiàn)的基于深度學(xué)習(xí)的場(chǎng)景分割算法.
1 深度學(xué)習(xí)發(fā)展概述
深度學(xué)習(xí)算法近年來(lái)在機(jī)器學(xué)習(xí)領(lǐng)域取得了巨大的進(jìn)展,其中,基于深度卷積神經(jīng)網(wǎng)絡(luò)的算法在計(jì)算機(jī)視覺領(lǐng)域取得了令人矚目的成就.深度卷積神經(jīng)網(wǎng)絡(luò)是以傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)為基礎(chǔ),不斷發(fā)展演變而來(lái).早在1998年“LeNet”網(wǎng)絡(luò)[28]就已具備現(xiàn)在深度卷積神經(jīng)網(wǎng)絡(luò)的完整結(jié)構(gòu),包括卷積層、非線性變換層、池化層、全連接層等深度卷積神經(jīng)網(wǎng)絡(luò)的基本單元.因此,“LeNet”網(wǎng)絡(luò)可以被視為當(dāng)前深度卷積神經(jīng)網(wǎng)絡(luò)的雛形.然而,計(jì)算能力和數(shù)據(jù)集規(guī)模的限制阻礙了深度卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展.
近年來(lái),隨著硬件設(shè)備的不斷發(fā)展和計(jì)算能力的不斷提高,計(jì)算機(jī)的運(yùn)算速度和效率得到了極大提升.尤其是圖像并行處理單元(graphics processing unit, GPU)的廣泛使用提高了大規(guī)模并行計(jì)算的能力.此外,隨著互聯(lián)網(wǎng)的興起和大數(shù)據(jù)技術(shù)的發(fā)展,多種大規(guī)模圖像數(shù)據(jù)集相繼出現(xiàn),為訓(xùn)練深度卷積神經(jīng)網(wǎng)絡(luò)提供數(shù)據(jù)支持.得益于并行計(jì)算能力和大規(guī)模數(shù)據(jù)集,深度卷積神經(jīng)網(wǎng)絡(luò)在以圖像識(shí)別為代表的計(jì)算機(jī)視覺領(lǐng)域相關(guān)任務(wù)中取得了驚人的突破.在2012年的“ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)賽”[29]中,卷積神經(jīng)網(wǎng)絡(luò)模型AlexNet[30]將ImageNet分類數(shù)據(jù)集[31]的Top-5識(shí)別錯(cuò)誤率從傳統(tǒng)算法的26%降低到16.4%,取得了令人振奮的進(jìn)步.這一工作也掀起了深度卷積神經(jīng)網(wǎng)絡(luò)的研究熱潮.
此后,越來(lái)越多的研究人員投身到對(duì)深度卷積神經(jīng)網(wǎng)絡(luò)的研究中.以圖像識(shí)別任務(wù)為切入點(diǎn),研究人員不斷提出更深更精巧的網(wǎng)絡(luò)結(jié)構(gòu)和非線性激活函數(shù)提高神經(jīng)網(wǎng)絡(luò)的特征表達(dá)能力,先后提出了VGG[32],GoogLeNet[33],ResNet[34],ResNeXt[35],DenseNet[36]等網(wǎng)絡(luò)和Maxout[37],PReLU[38],ELU[39]等非線性激活函數(shù).同時(shí),研究人員還通過(guò)設(shè)計(jì)合理的網(wǎng)絡(luò)初始化方法[38,40]和特征歸一化方法[41-44]促進(jìn)神經(jīng)網(wǎng)絡(luò)的優(yōu)化過(guò)程.深度卷積神經(jīng)網(wǎng)絡(luò)可以從大規(guī)模數(shù)據(jù)中自動(dòng)學(xué)習(xí)到逐漸抽象的層次化特征,從底層圖像特征到高層語(yǔ)義概念的映射.因此,利用在大規(guī)模圖像識(shí)別數(shù)據(jù)集上預(yù)訓(xùn)練的深度卷積神經(jīng)網(wǎng)絡(luò)可以學(xué)習(xí)到合適的圖像特征表達(dá),并通過(guò)遷移學(xué)習(xí)的方法被應(yīng)用于計(jì)算機(jī)視覺領(lǐng)域的諸多任務(wù)中,均取得了極大的成功.例如目標(biāo)檢測(cè)算法[45-47]利用深度卷積神經(jīng)網(wǎng)絡(luò)同時(shí)預(yù)測(cè)圖像中目標(biāo)的類別和位置;圖像語(yǔ)義分割算法[14,48]利用深度卷積神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)圖像中每個(gè)像素的類別;實(shí)例分割算法[49]利用深度卷積神經(jīng)網(wǎng)絡(luò)同時(shí)預(yù)測(cè)圖像中每個(gè)目標(biāo)的類別、位置和包含像素;圖像描述算法[50]利用深度卷積神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)圖像特征,并輸入到循環(huán)神經(jīng)網(wǎng)絡(luò)中生成圖像的描述.
2 場(chǎng)景分割算法的“卷積
反卷積”框架
目前基于深度學(xué)習(xí)的場(chǎng)景分割算法主要利用了一種“卷積-反卷積”框架,包含卷積模塊和反卷積模塊.首先卷積模塊使用若干卷積層和池化層,逐漸從場(chǎng)景圖像中學(xué)習(xí)到抽象的語(yǔ)義特征表達(dá),獲得語(yǔ)義特征圖.由于使用了若干次池化層,生成的語(yǔ)義特征圖分辨率小于原始圖像.為獲得原始圖像的像素級(jí)類別預(yù)測(cè)結(jié)果,語(yǔ)義特征圖將輸入到由多個(gè)反卷積層組成的反卷積模塊,不斷擴(kuò)大特征圖的分辨率,直至與原始場(chǎng)景圖像分辨率相同.最終獲得的特征圖中每個(gè)位置對(duì)應(yīng)場(chǎng)景圖像中每個(gè)像素的類別置信度,從而得到場(chǎng)景圖像的分割結(jié)果.“卷積-反卷積”框架可以高效地對(duì)整幅場(chǎng)景圖像進(jìn)行處理,從原始圖像直接獲得分割結(jié)果.同時(shí),在訓(xùn)練過(guò)程中,“卷積-反卷積”框架可以進(jìn)行端對(duì)端的訓(xùn)練,更有益于從場(chǎng)景數(shù)據(jù)集中學(xué)習(xí)合適的特征表達(dá),因此其性能優(yōu)于傳統(tǒng)圖像分割算法.
常用的“卷積-反卷積”框架主要可分為全卷積網(wǎng)絡(luò)和反卷積網(wǎng)絡(luò)兩大類.全卷積網(wǎng)絡(luò)[14](fully convolutional network, FCN)通常以深度圖像識(shí)別網(wǎng)絡(luò)作為基礎(chǔ),將其結(jié)構(gòu)全卷積化后作為卷積模塊,獲得語(yǔ)義特征圖,再添加若干反卷積層作為反卷積模塊,如圖3所示.全卷積化是指將圖像識(shí)別網(wǎng)絡(luò)中的全連接層轉(zhuǎn)化為卷積核為1的卷積層,使網(wǎng)絡(luò)僅由卷積層、非線性激活層和池化層組成.經(jīng)過(guò)全卷積化之后,全卷積網(wǎng)絡(luò)可以接受任意大小的場(chǎng)景圖像作為輸入,并通過(guò)多個(gè)反卷積層獲得與原始輸入圖像相同大小的類別置信度圖.利用深度圖像識(shí)別網(wǎng)絡(luò)的結(jié)構(gòu)作為卷積模塊后,可以利用深度圖像識(shí)別網(wǎng)絡(luò)在大規(guī)模的圖像分類數(shù)據(jù)集(如ImageNet)上預(yù)訓(xùn)練得到的網(wǎng)絡(luò)參數(shù)作為全卷積網(wǎng)絡(luò)的初始化參數(shù).這種參數(shù)遷移的方法有利于全卷積網(wǎng)絡(luò)參數(shù)的優(yōu)化.由于場(chǎng)景分割需要精確到像素級(jí),構(gòu)建場(chǎng)景分割的人工標(biāo)注需要花費(fèi)大量的人力物力,導(dǎo)致現(xiàn)有的場(chǎng)景分割數(shù)據(jù)集的樣本數(shù)量通常較少.而訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)通常需要大量有標(biāo)注的數(shù)據(jù),因此如果直接使用樣本數(shù)量較少的場(chǎng)景分割數(shù)據(jù)集訓(xùn)練,可能因?yàn)闃颖静粔驅(qū)е履P拖萑刖容^低的局部極小點(diǎn),損害模型的精度.而使用大規(guī)模圖像識(shí)別數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練后,模型參數(shù)可以學(xué)習(xí)到較為合適的圖像特征表達(dá),為后續(xù)訓(xùn)練場(chǎng)景分割模型提供較好的初始值,幫助模型收斂到精度較高的局部極小點(diǎn),從而提升場(chǎng)景分割模型的性能.利用數(shù)據(jù)集SIFT Flow[51]進(jìn)行評(píng)測(cè),全卷積網(wǎng)絡(luò)的像素級(jí)正確率(pixel accuracy)達(dá)到85.2%,相比傳統(tǒng)方法[52]的78.6%,取得6.6%的性能提升.在目前常用的場(chǎng)景分割數(shù)據(jù)集Cityscapes[53]上全卷積網(wǎng)絡(luò)可以取得平均交并比(mean Intersection-over-Union, mIoU)為65.3%,達(dá)到當(dāng)時(shí)的最佳性能.
相比之下,反卷積網(wǎng)絡(luò)[15-16]的卷積模塊與全卷積網(wǎng)絡(luò)類似,也是由多個(gè)卷積層和池化層堆疊而成.通常其反卷積模塊完全采用其卷積模塊的鏡像結(jié)構(gòu),同時(shí)設(shè)計(jì)了反池化層作為池化層的鏡像操作.反卷積網(wǎng)絡(luò)不使用預(yù)訓(xùn)練參數(shù),而是直接從隨機(jī)參數(shù)開始訓(xùn)練網(wǎng)絡(luò),因此時(shí)常難以優(yōu)化,算法性能也會(huì)低于全卷積網(wǎng)絡(luò),如SegNet[16]在Cityscapes數(shù)據(jù)集上的mIoU為57.0%.目前,大部分基于深度學(xué)習(xí)的場(chǎng)景分割算法都采用了全卷積網(wǎng)絡(luò)的結(jié)構(gòu),同時(shí)利用深度圖像識(shí)別網(wǎng)絡(luò)的預(yù)訓(xùn)練參數(shù)作為初始化.
全卷積網(wǎng)絡(luò)雖然在場(chǎng)景分割問(wèn)題上取得了極大的突破,但其本身依賴于大規(guī)模圖像識(shí)別網(wǎng)絡(luò)結(jié)構(gòu),存在著一定的局限性.首先,全卷積網(wǎng)絡(luò)所使用的圖像識(shí)別網(wǎng)絡(luò)模型通常包含多次池化等下采樣操作,因此丟失了許多細(xì)節(jié)信息.而場(chǎng)景分割問(wèn)題具有分割粒度細(xì)的特點(diǎn),因此直接使用圖像識(shí)別網(wǎng)絡(luò)會(huì)極大損害最終的分割精度.針對(duì)這一問(wèn)題,研究人員提出了基于高分辨率語(yǔ)義特征圖的場(chǎng)景分割算法提高分割精度.其次,場(chǎng)景分割問(wèn)題存在視覺要素尺度變化多樣的問(wèn)題,但全卷積網(wǎng)絡(luò)對(duì)整幅圖像使用相同的卷積操作,未考慮視覺要素的多尺度問(wèn)題,損害了場(chǎng)景圖像中較大尺度和較小尺度的視覺要素的分割精度.因此,研究人員提出了基于多尺度的場(chǎng)景分割算法.最后,全卷積網(wǎng)絡(luò)所使用的圖像識(shí)別網(wǎng)絡(luò)未考慮空間上下文信息,而場(chǎng)景分割問(wèn)題存在空間相關(guān)性強(qiáng)的特點(diǎn),場(chǎng)景圖像中的空間相關(guān)關(guān)系對(duì)提升分割精度有極大幫助.為了有效捕捉場(chǎng)景圖像中的空間上下文和相關(guān)關(guān)系,研究人員提出了基于空間上下文的場(chǎng)景分割算法.接下來(lái)我們將對(duì)這些方法進(jìn)行梳理和詳細(xì)介紹.其中一些代表性方法在City-scapes數(shù)據(jù)集測(cè)試集上的性能對(duì)比如圖4所示:
3 基于高分辨率語(yǔ)義特征圖的場(chǎng)景分割算法
全卷積網(wǎng)絡(luò)中使用圖像識(shí)別網(wǎng)絡(luò)的結(jié)構(gòu)學(xué)習(xí)場(chǎng)景圖像的特征表達(dá).而在圖像識(shí)別網(wǎng)絡(luò)中,為了能有效捕捉圖像的全局語(yǔ)義特征,排除圖像中視覺要素的空間變換對(duì)特征學(xué)習(xí)的干擾,圖像識(shí)別網(wǎng)絡(luò)通常包含若干個(gè)步長(zhǎng)大于1的池化層.池化層可以融合池化區(qū)域的特征,擴(kuò)大感受野,同時(shí)保持感受野中視覺要素的平移不變形.但同時(shí),池化操作會(huì)縮小特征圖的分辨率,從而丟失空間位置信息和許多細(xì)節(jié)信息.例如在目前常用的圖像識(shí)別網(wǎng)絡(luò)中,通常使用5個(gè)步長(zhǎng)為2的池化層,使最后的語(yǔ)義特征圖分辨率下降為原始輸入圖像的1/32.因此,當(dāng)圖像識(shí)別網(wǎng)絡(luò)被遷移到全卷積網(wǎng)絡(luò)中后,語(yǔ)義特征圖的分辨率過(guò)小和丟失過(guò)多細(xì)節(jié)信息導(dǎo)致分割邊界不準(zhǔn)確,從而影響了全卷積網(wǎng)絡(luò)的分割精度.針對(duì)該問(wèn)題,研究人員提出了諸多基于高分辨率語(yǔ)義特征圖的算法,包括利用跨層結(jié)構(gòu)、膨脹卷積和基于全分辨率的算法.
3.1 跨層結(jié)構(gòu)算法
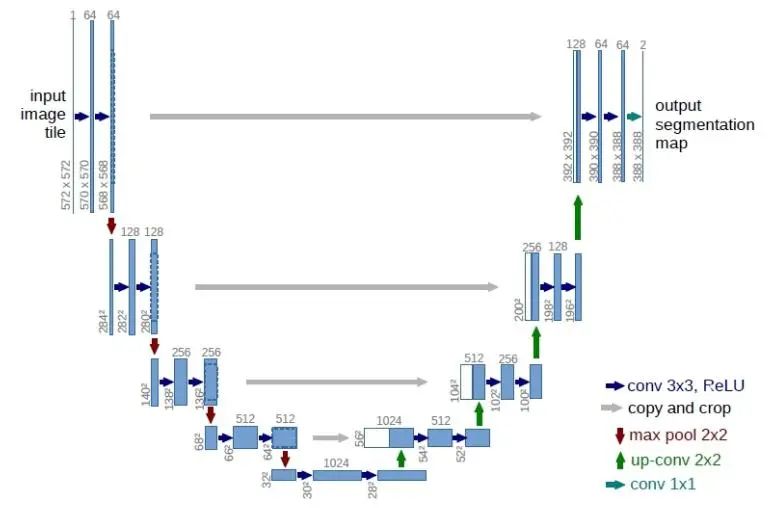
基于跨層結(jié)構(gòu)的算法[14,54-56]通過(guò)融合較淺層的特征圖提高語(yǔ)義特征圖的分辨率.在前向傳播過(guò)程中,卷積神經(jīng)網(wǎng)絡(luò)的特征圖分辨率逐漸變小,每經(jīng)過(guò)一個(gè)池化層,特征圖的邊長(zhǎng)會(huì)減小為原來(lái)的1/2.因此較淺層的特征圖分辨率較大,保留了更多的細(xì)節(jié).基于跨層結(jié)構(gòu)的算法其基本思路為通過(guò)融合較淺層的分辨率較大的特征圖,提高語(yǔ)義特征圖的分辨率,捕捉更多的細(xì)節(jié)信息,從而提高分割精度.這些基于跨層結(jié)構(gòu)的算法通常在反卷積模塊中融合較淺層的特征圖,通過(guò)使用反卷積層將語(yǔ)義特征圖的分辨率擴(kuò)大后,與網(wǎng)絡(luò)淺層特征圖的分辨率恰好相等,然后進(jìn)行融合,之后進(jìn)行后續(xù)的反卷積操作.例如FCN-8s[14]通過(guò)融合分辨率為原始圖像大小的1/16和1/8的淺層特征圖,將Cityscapes數(shù)據(jù)集的mIoU性能從61.3%提高到65.3%;U-Net[54]將從1/16到原始圖像大小的特征圖均進(jìn)行了融合;LRR[55]借鑒了拉普拉斯金字塔結(jié)構(gòu),通過(guò)利用多個(gè)淺層的不同分辨率特征圖對(duì)細(xì)節(jié)進(jìn)行重建獲取高分辨率的語(yǔ)義特征圖,在Cityscapes數(shù)據(jù)集上取得69.7%的mIoU;RefineNet[56]設(shè)計(jì)了一種遞歸的多路修正網(wǎng)絡(luò)結(jié)構(gòu),利用淺層高分辨特征圖中的信息對(duì)深層低分辨率的特征圖進(jìn)行修正,從而生成高分辨的語(yǔ)義特征圖,在Cityscapes數(shù)據(jù)集上將mIoU提高到73.6%.基于跨層結(jié)構(gòu)的算法通過(guò)在反卷積模塊中利用淺層特征圖恢復(fù)卷積模塊中丟失的細(xì)節(jié)信息,但是由于這些細(xì)節(jié)信息難以被完美恢復(fù),這限制了跨層結(jié)構(gòu)算法的分割性能.
3.2 膨脹卷積算法
基于跨層結(jié)構(gòu)的算法主要在“卷積-反卷積”結(jié)構(gòu)的反卷積模塊提升語(yǔ)義特征圖的分辨率,但在卷積模塊中語(yǔ)義特征圖的分辨率依然會(huì)下降到非常低,如原始輸入大小的1/32.而基于膨脹卷積的算法[48,57-59]著眼于在卷積模塊中保持語(yǔ)義特征圖的分辨率,如保持在原始輸入大小的1/8,這樣就可以在卷積模塊中保留更多的細(xì)節(jié)信息.
圖像識(shí)別網(wǎng)絡(luò)中,特征圖分辨率的下降是由步長(zhǎng)為2的池化操作引起的,即每2步的計(jì)算中丟棄1個(gè)結(jié)果.如果將池化操作的步長(zhǎng)從2改為1,則可以保持特征圖的分辨率,即保留了上述被丟棄的結(jié)果.但在后續(xù)的卷積操作中,特征圖中原來(lái)相鄰的特征向量間插入了本應(yīng)被丟棄的特征向量,與卷積核直接相乘時(shí)會(huì)造成錯(cuò)位,導(dǎo)致錯(cuò)誤的卷積結(jié)果.為解決該問(wèn)題,DeepLab系列算法[48,57-59]使用了膨脹卷積操作代替標(biāo)準(zhǔn)卷積.如圖5所示,膨脹卷積會(huì)在卷積核向量中插入一個(gè)0,將卷積核邊長(zhǎng)“膨脹”為原來(lái)的2倍.膨脹后的卷積核與修改池化操作步長(zhǎng)后得到的特征圖進(jìn)行卷積,可以有效解決相乘錯(cuò)位的問(wèn)題.原來(lái)被丟棄的特征向量會(huì)恰好與插入的0相乘,并不影響最終的卷積結(jié)果.因此,膨脹卷積可以保證將池化操作的步長(zhǎng)從2改為1后,后面的卷積層依然可以得到正確的卷積結(jié)果.值得注意的是,若某一個(gè)池化層的步長(zhǎng)從2改為1,其后的所有卷積層均需使用膨脹系數(shù)為2的膨脹卷積.如果后面又出現(xiàn)了將池化層的步長(zhǎng)從2改為1的修改,則在之后的所有卷積層的膨脹系數(shù)需要再乘2,即使用膨脹系數(shù)為4的膨脹卷積,以此類推.例如,將圖像識(shí)別網(wǎng)絡(luò)的第4和第5階段的池化層步長(zhǎng)從2改為1,并對(duì)其后的卷積層分別使用膨脹系數(shù)為2和4的膨脹卷積,將卷積模塊的語(yǔ)義特征圖分辨率從原始圖像大小的1/32提高到1/8.使用膨脹卷積可以在“卷積-反卷積”結(jié)構(gòu)的卷積模塊中保持較高分辨率的語(yǔ)義特征圖,從而保留更多的細(xì)節(jié)信息,提高分割的精度,例如DeepLabv2[48]在Cityscapes數(shù)據(jù)集上取得mIoU為70.4%.膨脹卷積算法由于其方便有效的特點(diǎn),被廣泛應(yīng)用于場(chǎng)景分割算法的卷積模塊中.
3.3 全分辨率算法
基于膨脹卷積的算法只對(duì)語(yǔ)義特征圖進(jìn)行一定程度的擴(kuò)大,從原始圖像的1/32擴(kuò)大為1/8,依然丟失了部分細(xì)節(jié)信息,對(duì)分割邊界的確定造成一定影響.相比之下,全分辨率殘差網(wǎng)絡(luò)(FRRN)[60]則提出了一種基于全分辨率特征圖的算法,將特征圖分辨率始終保持在原始圖像大小.該算法借鑒了殘差學(xué)習(xí)的思想,包含2個(gè)信息流:殘差流和池化流.其中殘差流不包含任何池化和下采樣操作,將該流的特征圖始終保持在與原始圖像相同的分辨率大小;而池化流則包含若干步長(zhǎng)為2的池化操作,特征圖的分辨率先減小后增大.殘差流側(cè)重于捕捉細(xì)節(jié)信息,主要用于確定精確的分割邊界;而池化流則側(cè)重于學(xué)習(xí)語(yǔ)義特征,主要用于識(shí)別視覺要素的類別.殘差流和池化流在網(wǎng)絡(luò)的前向傳播過(guò)程中不斷進(jìn)行交互,從而使全分辨率殘差網(wǎng)絡(luò)可以同時(shí)學(xué)習(xí)語(yǔ)義特征和捕捉細(xì)節(jié)信息,因此可以獲得更加精確的分割結(jié)果.FRRN在Cityscapes數(shù)據(jù)集取得的mIoU為71.8%.但全分辨率殘差網(wǎng)絡(luò)也有其局限性.由于殘差流始終保持在原始圖像的分辨率,因此其維度較高,會(huì)占用大量的顯存空間.同時(shí),殘差流和池化流的交互操作也會(huì)產(chǎn)生大量的空間消耗.這都制約了全分辨率殘差網(wǎng)絡(luò)在高分辨率場(chǎng)景圖像中的使用.
4 基于多尺度的場(chǎng)景分割算法
由于場(chǎng)景圖像中存在一定的透視畸變,且包含多種類別的視覺要素,因此場(chǎng)景圖像中視覺要素的尺度是多樣的.而卷積神經(jīng)網(wǎng)絡(luò)的感受野大小是固定的.對(duì)于圖像中尺度較大的視覺要素,感受野只能覆蓋其局部區(qū)域,容易造成錯(cuò)誤的識(shí)別結(jié)果;而對(duì)于圖像中尺度較小的視覺要素,感受野會(huì)覆蓋過(guò)多的背景區(qū)域,導(dǎo)致誤判為背景類別.針對(duì)上述問(wèn)題,研究人員提出了基于多尺度的場(chǎng)景分割算法,通過(guò)獲取多尺度信息學(xué)習(xí)不同尺度視覺要素的特征表達(dá),以提高場(chǎng)景分割的精度.大部分基于多尺度的算法通過(guò)設(shè)計(jì)不同的網(wǎng)絡(luò)結(jié)構(gòu)獲取多尺度特征,可分為共享結(jié)構(gòu)、層級(jí)結(jié)構(gòu)、并行結(jié)構(gòu)3類,如圖6所示.這些算法所采用的尺度通常通過(guò)人工設(shè)計(jì),與網(wǎng)絡(luò)的結(jié)構(gòu)緊密相關(guān).獲取多尺度信息之后再通過(guò)多種方法融合多尺度特征.另外一些算法則利用自適應(yīng)學(xué)習(xí)而非人工設(shè)計(jì)的方法獲取多尺度特征.
4.1 共享結(jié)構(gòu)算法
基于共享結(jié)構(gòu)的算法[61-62]主要在卷積模塊中利用一個(gè)參數(shù)共享的卷積神經(jīng)網(wǎng)絡(luò).通過(guò)將輸入圖像縮放為不同的尺度(通常使用2~3種),均輸入到共享網(wǎng)絡(luò)中,從而獲取不同尺度的語(yǔ)義特征圖.之后通過(guò)上下采樣將不同尺度的語(yǔ)義特征圖插值到相同的分辨率,再進(jìn)行特征融合.這種算法并沒有改變卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),即沒有改變網(wǎng)絡(luò)的感受野大小,而是通過(guò)調(diào)整輸入圖像的尺度獲取多尺度特征.同時(shí)通過(guò)將輸入圖像進(jìn)行縮放,使共享網(wǎng)絡(luò)獲得處理多尺度視覺要素的能力.利用共享結(jié)構(gòu),F(xiàn)eatMap-Net[62]在Cityscapes數(shù)據(jù)集上達(dá)到mIoU為71.6%.基于共享結(jié)構(gòu)的算法需要將同一幅輸入圖像利用不同尺度計(jì)算若干次,因此會(huì)使卷積模塊的計(jì)算量成倍增加,降低分割速度.
4.2 層級(jí)結(jié)構(gòu)算法
基于層級(jí)結(jié)構(gòu)的算法[63-65]通過(guò)卷積神經(jīng)網(wǎng)絡(luò)不同階段的特征圖獲取多尺度信息.卷積神經(jīng)網(wǎng)絡(luò)在前向傳播過(guò)程中,隨著卷積和池化操作,感受野不斷增大.較淺層的特征圖對(duì)應(yīng)的感受野較小,特征的尺度也較小;而較深層的特征圖對(duì)應(yīng)的感受野較大,特征的尺度也較大.因此,通過(guò)融合卷積神經(jīng)網(wǎng)絡(luò)不同階段的特征圖即可獲取多尺度信息.
利用層級(jí)結(jié)構(gòu),ML-CRNN[65]在Cityscapes數(shù)據(jù)集的mIoU達(dá)到71.2%.由于不同階段特征圖的分辨率不同,融合前需要利用上下采樣等方法將特征圖插值到相同的分辨率再進(jìn)行融合.基于層級(jí)結(jié)構(gòu)的算法不會(huì)引起過(guò)多的計(jì)算量,但卷積神經(jīng)網(wǎng)絡(luò)的較淺層通常更偏重學(xué)習(xí)圖像的視覺特征,而較深層更偏重學(xué)習(xí)圖像的語(yǔ)義特征.將淺層與深層特征進(jìn)行融合時(shí)會(huì)對(duì)最終的語(yǔ)義特征圖引入一定的噪聲,損害語(yǔ)義表達(dá)的精確度.
4.3 并行結(jié)構(gòu)算法
基于并行結(jié)構(gòu)的算法在卷積模塊獲得的語(yǔ)義特征圖之后連接多個(gè)感受野不同的并行分支,形成一種并行的結(jié)構(gòu),以捕捉不同尺度的特征.其中,PSPNet[66]使用空間金字塔池化,利用不同系數(shù)的池化層生成對(duì)應(yīng)多個(gè)尺度的分支,再利用不同的上采樣系數(shù)在特征圖上采樣到相同的分辨率,在Cityscapes數(shù)據(jù)集上獲得mIoU為81.2%.而DeepLab系列算法[48,58-59]則使用多尺度膨脹卷積的思想,建立ASPP(atrous spatial pyramid pooling)模塊,利用不同系數(shù)的膨脹卷積層生成對(duì)應(yīng)多個(gè)尺度的分支.ASPP模塊中不同分支的特征圖分辨率相同,融合前不需要進(jìn)行上采樣.其中,在Cityscapes數(shù)據(jù)集上DeepLabv3[58]的mIoU為81.2%,而DeepLabv3+[59]則將mIoU提升至82.1%.TKCN[67]將多個(gè)并行分支建立為樹型結(jié)構(gòu),提高了多尺度融合的效率,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到79.5%.Dense ASPP[68]將并行的ASPP模塊內(nèi)部加入全連接,從而高效地?cái)U(kuò)增了ASPP模塊能夠捕捉的尺度,并在Cityscapes數(shù)據(jù)集上DeepLabv3的mIoU達(dá)到80.6%.基于并行結(jié)構(gòu)的算法僅需在語(yǔ)義特征圖之后加入幾個(gè)新的分支,因此增加的計(jì)算量遠(yuǎn)遠(yuǎn)小于基于共享結(jié)構(gòu)的算法.同時(shí)由于這些并行分支都是從卷積模塊獲得的語(yǔ)義特征圖計(jì)算得到,相比基于層級(jí)結(jié)構(gòu)的算法更加適合于進(jìn)行語(yǔ)義特征的學(xué)習(xí).
4.4 多尺度特征融合
利用4.1~4.3節(jié)所述的結(jié)構(gòu)獲取多尺度特征后,還需要將特征融合起來(lái)以預(yù)測(cè)分割結(jié)果.目前主流的特征融合算法包括特征連接、加權(quán)融合或基于注意力機(jī)制.基于特征連接的算法[63-64]將不同尺度的特征直接按通道進(jìn)行拼接,后面連接一個(gè)卷積層或全連接層進(jìn)行融合.因此這個(gè)卷積層的參數(shù)可以被視為是多尺度特征的融合系數(shù).基于加權(quán)融合的算法[48]則對(duì)每個(gè)尺度的特征使用不同的融合系數(shù),這些融合系數(shù)通常是人工預(yù)設(shè)的.基于注意力機(jī)制的融合算法[61,65]則通過(guò)學(xué)習(xí)不同尺度、不同位置最合適的注意力參數(shù)進(jìn)行融合.這3種融合算法的最大區(qū)別是其需要的融合系數(shù)數(shù)量不同.其中特征連接算法使用的融合系數(shù)數(shù)量最多,特征圖的每個(gè)尺度、每個(gè)位置、每個(gè)通道的值都需要學(xué)習(xí)不同的融合系數(shù);而加權(quán)融合算法使用的融合系數(shù)數(shù)量最少,僅需要與尺度數(shù)量相同的融合系數(shù),這是因?yàn)橄嗤某叨忍卣髟诓煌奈恢煤屯ǖ赖闹稻褂孟嗤南禂?shù);而使用注意力機(jī)制的算法需要的融合系數(shù)數(shù)量介于特征連接和加權(quán)融合算法之間,其思想為在每個(gè)空間位置學(xué)習(xí)最合適的尺度融合系數(shù).因此雖然不同尺度、不同位置需要利用注意力思想學(xué)習(xí)不同的融合系數(shù),但同一通道內(nèi)會(huì)共享融合系數(shù).在實(shí)際應(yīng)用中,特征連接算法參數(shù)量較大,加權(quán)融合算法相對(duì)簡(jiǎn)單便捷,但需要人工設(shè)定合適的融合系數(shù).而由于場(chǎng)景圖像中不同空間位置的視覺要素尺度不同,使用注意力機(jī)制對(duì)不同空間位置學(xué)習(xí)不同的融合系數(shù)常常可以有效提高特征融合的效果,從而獲得較高的分割精度.
4.5 自適應(yīng)學(xué)習(xí)算法
4.4節(jié)所述的基于多尺度融合的算法所捕捉的尺度通常是人工預(yù)設(shè)的,且受限于計(jì)算復(fù)雜度一般僅使用3~5種尺度.這些人工設(shè)計(jì)的尺度無(wú)法涵蓋場(chǎng)景圖像中的視覺要素可能出現(xiàn)的所有尺度,會(huì)出現(xiàn)遺漏和偏差.視覺要素的尺度可能會(huì)較大或較小,超出人工預(yù)設(shè)尺度的范圍;而尺度在人工預(yù)設(shè)范圍內(nèi)的視覺要素也不一定會(huì)恰好符合某個(gè)預(yù)設(shè)尺度,而是更可能介于2個(gè)預(yù)設(shè)尺度之間.針對(duì)以上問(wèn)題,文獻(xiàn)[69-72]提出了基于自適應(yīng)學(xué)習(xí)的多尺度變換算法.其中SAC[69]通過(guò)自適應(yīng)學(xué)習(xí)卷積核的縮放系數(shù)調(diào)整卷積的感受野大小,從而對(duì)場(chǎng)景圖像的不同空間位置學(xué)習(xí)多種尺度的特征,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到78.1%.而DeformableNet[71]則通過(guò)學(xué)習(xí)卷積核中卷積向量的偏移對(duì)卷積的感受野產(chǎn)生形變,也可以實(shí)現(xiàn)學(xué)習(xí)多種尺度特征的目的,并在Cityscapes數(shù)據(jù)集上獲得的mIoU為75.2%.FoveaNet[72]借鑒目標(biāo)檢測(cè)的思想,先自適應(yīng)檢測(cè)場(chǎng)景圖像中視覺要素尺度較小的區(qū)域,然后將該區(qū)域放大進(jìn)行特征學(xué)習(xí),最后融合2種尺度的結(jié)果,在Cityscapes數(shù)據(jù)集上的mIoU為74.1%.相比人工預(yù)設(shè)尺度,基于自適應(yīng)學(xué)習(xí)的算法更加靈活,學(xué)習(xí)到的尺度更加貼合場(chǎng)景圖像中視覺要素的實(shí)際尺度.
5 基于空間上下文的場(chǎng)景分割算法
場(chǎng)景圖像存在著復(fù)雜的空間相關(guān)關(guān)系,可以用于區(qū)分視覺上較為相似的類別,對(duì)于視覺要素的識(shí)別具有重要的幫助作用.而目前基于“卷積-反卷積”結(jié)構(gòu)的場(chǎng)景分割算法所得到的語(yǔ)義特征圖是通過(guò)卷積的滑動(dòng)窗口操作計(jì)算所得,特征向量之間并沒有交互,即并沒有考慮場(chǎng)景圖像的空間相關(guān)關(guān)系.針對(duì)上述問(wèn)題,研究人員提出了基于空間上下文的場(chǎng)景分割算法,通過(guò)捕捉場(chǎng)景圖像的空間上下文信息和相關(guān)關(guān)系輔助視覺要素的識(shí)別,進(jìn)一步提升分割精度.基于空間上下文的算法主要分為基于多維循環(huán)神經(jīng)網(wǎng)絡(luò)、基于概率圖模型和基于注意力機(jī)制的算法.
5.1 基于多維循環(huán)神經(jīng)網(wǎng)絡(luò)
多維循環(huán)神經(jīng)網(wǎng)絡(luò)[73]具有循環(huán)的結(jié)構(gòu),適用于序列數(shù)據(jù)的編碼和特征學(xué)習(xí).在循環(huán)的過(guò)程中,多維循環(huán)神經(jīng)網(wǎng)絡(luò)可以不斷存儲(chǔ)序列中的有用信息而丟棄無(wú)關(guān)信息,同時(shí)捕捉序列前后節(jié)點(diǎn)之間的相關(guān)關(guān)系.因此,可以利用多維循環(huán)神經(jīng)網(wǎng)絡(luò)捕捉場(chǎng)景圖像中的空間上下文信息和相關(guān)關(guān)系.為縮短循環(huán)神經(jīng)網(wǎng)絡(luò)的序列長(zhǎng)度、降低計(jì)算復(fù)雜度,文獻(xiàn)[74-76]將循環(huán)神經(jīng)網(wǎng)絡(luò)連接于卷積模塊得到的低分辨率語(yǔ)義特征圖之后,對(duì)語(yǔ)義特征圖的特征向量進(jìn)行編碼.另一些算法[65,77-78]則在深度神經(jīng)網(wǎng)絡(luò)不同層的特征圖之間利用循環(huán)神經(jīng)網(wǎng)絡(luò)進(jìn)行編碼,從不同層的特征圖中捕捉空間上下文信息.針對(duì)語(yǔ)義特征圖的結(jié)構(gòu)特點(diǎn),研究人員將循環(huán)神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)為對(duì)角結(jié)構(gòu)、八鄰域結(jié)構(gòu)、圖結(jié)構(gòu)等不同的拓?fù)浣Y(jié)構(gòu),如圖7所示.對(duì)角結(jié)構(gòu)算法[65,74]從語(yǔ)義特征圖的某個(gè)角點(diǎn)(如左上角點(diǎn))出發(fā),向?qū)欠较蜻M(jìn)行編碼.在每一步的編碼過(guò)程中,均使用水平(如從左到右)、垂直(如從上到下)、對(duì)角(如從左上到右下)3個(gè)方向的特征作為序列的輸入.為兼顧不同方向的空間上下文信息,可以將語(yǔ)義特征圖的4個(gè)角點(diǎn)均作為出發(fā)點(diǎn),將得到的4個(gè)方向編碼結(jié)果進(jìn)行融合,從而獲取整幅圖像的空間上下文信息.基于八鄰域結(jié)構(gòu)的算法[75]則以語(yǔ)義特征圖中的每個(gè)特征向量作為出發(fā)點(diǎn),向周圍的8個(gè)方向進(jìn)行輻射和傳播,逐漸擴(kuò)大到整幅圖像,因此語(yǔ)義特征圖中的每個(gè)位置都會(huì)聚合整幅圖像的空間上下文信息.對(duì)角結(jié)構(gòu)和八鄰域結(jié)構(gòu)算法都將語(yǔ)義特征圖中的每個(gè)特征向量作為序列單元.與之不同的是,圖結(jié)構(gòu)算法[76-77]結(jié)合了圖像的低層特征,使用圖像的超像素對(duì)應(yīng)的特征向量作為序列單元.同時(shí)通過(guò)超像素的鄰接關(guān)系構(gòu)建圖結(jié)構(gòu),然后建立序列對(duì)超像素對(duì)應(yīng)的節(jié)點(diǎn)進(jìn)行特征編碼.利用多維循環(huán)神經(jīng)網(wǎng)絡(luò),ML-CRNN[65]使用對(duì)角結(jié)構(gòu)對(duì)不同層特征圖進(jìn)行編碼捕捉空間上下文,在Cityscapes數(shù)據(jù)集上取得的mIoU為71.2%.
5.2 基于概率圖模型
概率圖模型具有很強(qiáng)的概率推理能力,通過(guò)最大化特征的概率分布獲得類別預(yù)測(cè)結(jié)果.概率圖模型也被應(yīng)用于場(chǎng)景分割中捕捉場(chǎng)景圖像的空間上下文信息和相關(guān)關(guān)系.為有效減少概率圖模型的計(jì)算復(fù)雜度,通常在卷積模塊獲得的低分辨率語(yǔ)義特征圖之后建立概率圖模型,并以語(yǔ)義特征圖的特征向量作為概率圖模型的節(jié)點(diǎn).概率圖模型通常被建模為某種特殊的層插入到卷積神經(jīng)網(wǎng)絡(luò)的整個(gè)結(jié)構(gòu)中,實(shí)現(xiàn)端對(duì)端的訓(xùn)練和優(yōu)化.其中最常用的是Markov隨機(jī)場(chǎng)和條件隨機(jī)場(chǎng).Markov隨機(jī)場(chǎng)基于Markov模型和貝葉斯理論,可以根據(jù)計(jì)算統(tǒng)計(jì)最優(yōu)準(zhǔn)則確定分割問(wèn)題的目標(biāo)函數(shù),通過(guò)求解滿足目標(biāo)函數(shù)的分布將分割問(wèn)題轉(zhuǎn)化為最優(yōu)化問(wèn)題.DPN[79]將深度卷積神經(jīng)網(wǎng)絡(luò)與Markov隨機(jī)場(chǎng)結(jié)合,設(shè)計(jì)同時(shí)性卷積層近似Mean-field算法對(duì)Markov隨機(jī)場(chǎng)進(jìn)行求解,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到66.8%.條件隨機(jī)場(chǎng)模型則是基于無(wú)向圖的概率模型,計(jì)算條件隨機(jī)場(chǎng)模型的能量函數(shù)中的勢(shì)函數(shù),通過(guò)最大化類別標(biāo)簽的條件概率來(lái)得到無(wú)向圖中節(jié)點(diǎn)的預(yù)測(cè)類別.CRFasRNN[80]將條件隨機(jī)場(chǎng)利用循環(huán)神經(jīng)網(wǎng)絡(luò)進(jìn)行建模,連接在深度卷積神經(jīng)網(wǎng)絡(luò)之后進(jìn)行端對(duì)端的訓(xùn)練,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到62.5%.FeatMap-Net[62]在多尺度融合得到的語(yǔ)義特征圖之后建立條件隨機(jī)場(chǎng)模型學(xué)習(xí)“塊與塊”和“塊與背景”的相關(guān)關(guān)系捕捉空間上下文,在Cityscapes數(shù)據(jù)集上取得的mIoU為71.6%.SegModel[81]利用條件隨機(jī)場(chǎng)同時(shí)捕捉特征圖和人工標(biāo)注見的空間上下文,從而提高分割精度,在Cityscapes數(shù)據(jù)集上獲得的mIoU為79.2%.
5.3 基于注意力機(jī)制
基于注意力機(jī)制的算法[82-85]通過(guò)融合局部區(qū)域內(nèi)的特征向量捕捉場(chǎng)景圖像中的空間上下文信息和相關(guān)關(guān)系.在使用注意力機(jī)制時(shí),需要添加額外的層學(xué)習(xí)注意力系數(shù),之后利用該系數(shù)對(duì)局部區(qū)域內(nèi)的特征向量進(jìn)行加權(quán)聚合.由于注意力系數(shù)的學(xué)習(xí)和局部特征的聚合過(guò)程都是可導(dǎo)的,注意力機(jī)制可以靈活被插入在神經(jīng)網(wǎng)絡(luò)的不同位置,并進(jìn)行端對(duì)端的學(xué)習(xí).由于注意力系數(shù)對(duì)局部區(qū)域內(nèi)的不同位置會(huì)學(xué)習(xí)到不同的參數(shù),因此在聚合時(shí)可以提高局部區(qū)域內(nèi)相關(guān)信息的影響,并抑制局部區(qū)域內(nèi)的無(wú)關(guān)信息的影響.同時(shí),特征圖中的不同位置可以通過(guò)模型訓(xùn)練學(xué)習(xí)到最適合的注意力系數(shù),從而有效捕捉空間上下文信息和相關(guān)關(guān)系.GLRN[82]通過(guò)學(xué)習(xí)注意力參數(shù)學(xué)習(xí)局部聚合系數(shù)捕捉局部上下文,對(duì)分割結(jié)果的邊界進(jìn)行修正,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到77.3%.PSANet[83]利用注意力機(jī)制學(xué)習(xí)雙向自適應(yīng)聚合參數(shù)捕捉局部上下文,在Cityscapes數(shù)據(jù)集上取得的mIoU為81.4%.DANet[84]設(shè)計(jì)了2個(gè)注意力分支,分別學(xué)習(xí)針對(duì)位置和通道的注意力參數(shù),用于捕捉局部和全局空間上下文,在Cityscapes數(shù)據(jù)集上的mIoU達(dá)到81.5%.OCNet[85]利用注意力機(jī)制學(xué)習(xí)針對(duì)相同視覺類別的空間上下文,在Cityscapes數(shù)據(jù)集上取得的mIoU為81.7%.
6 場(chǎng)景分割相關(guān)數(shù)據(jù)集
場(chǎng)景分割數(shù)據(jù)集對(duì)驗(yàn)證場(chǎng)景分割算法的有效性有重要意義.同時(shí),帶標(biāo)注的大規(guī)模數(shù)據(jù)集可以有效提升深度學(xué)習(xí)模型的性能.由于場(chǎng)景分割需要對(duì)場(chǎng)景中的每個(gè)像素進(jìn)行類別識(shí)別,場(chǎng)景分割數(shù)據(jù)集的人工標(biāo)注也需要精確到像素級(jí)別,因此場(chǎng)景分割數(shù)據(jù)集的標(biāo)注工作十分費(fèi)時(shí)費(fèi)力.近年來(lái),公開的場(chǎng)景分割數(shù)據(jù)集數(shù)量越來(lái)越多,規(guī)模越來(lái)越大,為場(chǎng)景分割問(wèn)題的發(fā)展起到極大的推動(dòng)作用.本節(jié)將從數(shù)據(jù)集規(guī)模等方面介紹常用的場(chǎng)景分割數(shù)據(jù)集,并分析其特點(diǎn).這些數(shù)據(jù)集的基本信息如表1所示,部分示例如圖8所示。
6.1 SIFT Flow
SIFT Flow數(shù)據(jù)集[51]中的圖像由8種典型的戶外場(chǎng)景組成.該數(shù)據(jù)集共包含2 688個(gè)圖像樣本,其中2 488個(gè)訓(xùn)練樣本、200個(gè)測(cè)試樣本,每個(gè)圖像的分辨率為256×256.同時(shí)數(shù)據(jù)集中包含33個(gè)語(yǔ)義類別的像素級(jí)人工標(biāo)注.SIFT Flow數(shù)據(jù)集的圖像分辨率較小,場(chǎng)景比較簡(jiǎn)單,類別數(shù)和圖像數(shù)量較少.
6.2 CamVid
CamVid數(shù)據(jù)集[86]中的圖像均采集于街景,包括701個(gè)街景圖像,其中包括468個(gè)訓(xùn)練圖像和233個(gè)測(cè)試圖像.每個(gè)圖像樣本的分辨率為960×720,并且包含11個(gè)語(yǔ)義類別的像素級(jí)人工標(biāo)記.CamVid數(shù)據(jù)集的類別數(shù)和圖像數(shù)量較少,但圖像分辨率相對(duì)較大,場(chǎng)景針對(duì)于街景,對(duì)自動(dòng)駕駛相關(guān)技術(shù)具有極大意義.
6.3 Barcelona
Barcelona數(shù)據(jù)集[87]由14 871個(gè)訓(xùn)練圖像樣本和279個(gè)測(cè)試圖像樣本組成.其中訓(xùn)練圖像采集于室內(nèi)和室外場(chǎng)景,而測(cè)試圖像均采集于巴塞羅那的街道場(chǎng)景.該數(shù)據(jù)集中不同圖像樣本的分辨率不同,并且包含170個(gè)語(yǔ)義類別的像素級(jí)人工標(biāo)記.
6.4 PASCAL Context
PASCAL Context數(shù)據(jù)集[88]是以PASCAL VOC數(shù)據(jù)集[89]為基礎(chǔ)建立的.原始PASCAL VOC數(shù)據(jù)集僅標(biāo)注了前景視覺要素的類別,而PASCAL Context數(shù)據(jù)集還提供了背景視覺要素的類別,因此更加適合于場(chǎng)景分割算法.PASCAL Context數(shù)據(jù)集包括4 998個(gè)訓(xùn)練圖像樣本和5 105個(gè)測(cè)試圖像樣本,每個(gè)圖像樣本的分辨率不超過(guò)500×500,并被標(biāo)記為59個(gè)類別和1個(gè)其他類.相比原始PASCAL VOC數(shù)據(jù)集,PASCAL Context數(shù)據(jù)集包含的圖像樣本和類別數(shù)量更多,難度也更大.
6.5 Cityscapes
Cityscapes數(shù)據(jù)集[53]中的圖像是利用車載攝像頭采集的歐洲城市的街景.該數(shù)據(jù)集包含共5 000個(gè)圖像樣本,劃分為2 975個(gè)訓(xùn)練圖像樣本、500個(gè)驗(yàn)證圖像樣本和1 525個(gè)測(cè)試圖像樣本.數(shù)據(jù)集中包含19個(gè)類別的像素級(jí)的人工標(biāo)注,其中每個(gè)圖像樣本的分辨率為2048×1024.Cityscapes數(shù)據(jù)集針對(duì)于街道場(chǎng)景,包含的圖像樣本數(shù)量和類別數(shù)較少,但圖像的分辨率較大,這就需要在設(shè)計(jì)算法時(shí)同時(shí)兼顧算法速度和性能,對(duì)自動(dòng)駕駛相關(guān)技術(shù)具有重大的意義,是目前評(píng)測(cè)深度學(xué)習(xí)場(chǎng)景分割算法常用的數(shù)據(jù)集之一.
6.6 ADE20K
ADE20K數(shù)據(jù)集[90]取材于Places場(chǎng)景分類數(shù)據(jù)集.該數(shù)據(jù)集包含20 210個(gè)訓(xùn)練圖像樣本、2 000個(gè)驗(yàn)證圖像樣本和3 351個(gè)測(cè)試圖像樣本,同時(shí)包含150個(gè)語(yǔ)義類別的像素級(jí)人工標(biāo)注.數(shù)據(jù)集中圖像樣本的分辨率不同且差距較大,最小的圖像邊長(zhǎng)約200像素,最大的圖像邊長(zhǎng)超過(guò)2 000像素.ADE20K數(shù)據(jù)集包含的場(chǎng)景類別較多,有會(huì)議室、臥室等室內(nèi)場(chǎng)景,也有沙灘、街道等室外場(chǎng)景,且數(shù)據(jù)集中包含的樣本數(shù)量和類別數(shù)也較多,圖像的分辨率差距較大,因此ADE20K數(shù)據(jù)集的難度較高,對(duì)場(chǎng)景分割算法提出了更大的挑戰(zhàn),也催生了一部分優(yōu)秀的研究成果,是目前評(píng)測(cè)深度學(xué)習(xí)場(chǎng)景分割算法常用的數(shù)據(jù)集之一.
6.7 COCO-Stuff
COCO-Stuff數(shù)據(jù)集[91]是在COCO數(shù)據(jù)集[92]的基礎(chǔ)上對(duì)標(biāo)注進(jìn)行擴(kuò)展得到的.與PASCAL Context數(shù)據(jù)集和PASCAL VOC數(shù)據(jù)集的關(guān)系類似,原始COCO數(shù)據(jù)集僅標(biāo)注了前景視覺要素的類別,而COCO-Stuff數(shù)據(jù)集還提供了背景視覺要素的類別,因此更加適合于場(chǎng)景分割算法.COCO-Stuff數(shù)據(jù)集共包含10 000個(gè)圖像樣本,其中9 000個(gè)訓(xùn)練圖像樣本和1 000個(gè)測(cè)試圖像樣本.同時(shí)包含172個(gè)類別的像素級(jí)標(biāo)注,其中80個(gè)前景類別、91個(gè)背景類別和1個(gè)無(wú)標(biāo)注類別.COCO-Stuff數(shù)據(jù)集包含的場(chǎng)景種類、語(yǔ)義類別和圖像樣本數(shù)量均較多,因此難度較高,對(duì)場(chǎng)景分割算法提出了更大的挑戰(zhàn),是目前評(píng)測(cè)深度學(xué)習(xí)場(chǎng)景分割算法常用的數(shù)據(jù)集之一.此外,COCO-Stuff數(shù)據(jù)集還可作為預(yù)訓(xùn)練數(shù)據(jù)集,從而提升深度學(xué)習(xí)場(chǎng)景分割模型在其他場(chǎng)景分割數(shù)據(jù)集上的性能.
7 算法泛化能力分析
算法泛化能力對(duì)算法的實(shí)際應(yīng)用具有重要意義.我們從2個(gè)方面分析基于深度學(xué)習(xí)的場(chǎng)景分割算法的泛化能力:1)算法在不同數(shù)據(jù)集的泛化能力;2)算法在不同任務(wù)的泛化能力.表2展示了目前流行的基于深度學(xué)習(xí)的場(chǎng)景分割算法在不同場(chǎng)景分割數(shù)據(jù)集的分割精度,包括Cityscapes[53],PASCAL Context[88]和ADE20K[90]這3個(gè)數(shù)據(jù)集.同時(shí)列舉了部分算法在語(yǔ)義分割數(shù)據(jù)集PASCAL VOC 2012[89]的分割精度.語(yǔ)義分割不需要對(duì)背景類別進(jìn)行分割,與場(chǎng)景分割相比更加關(guān)注前景的類別,因此場(chǎng)景分割與語(yǔ)義分割是不同的圖像分割子任務(wù).首先,我們對(duì)比表2中現(xiàn)有基于深度學(xué)習(xí)的場(chǎng)景分割算法在場(chǎng)景分割不同數(shù)據(jù)集上的結(jié)果.由于不同數(shù)據(jù)集存在著類別差異,導(dǎo)致同一算法在不同數(shù)據(jù)集的精度值會(huì)有一定差異.但總體看來(lái),在其中某個(gè)場(chǎng)景分割數(shù)據(jù)集上分割精度較高的算法在另外2個(gè)場(chǎng)景分割數(shù)據(jù)集的精度也相對(duì)較高,這說(shuō)明現(xiàn)有算法在場(chǎng)景分割的不同數(shù)據(jù)集上具有較好的泛化能力.其次,我們對(duì)比表2中算法在場(chǎng)景分割和語(yǔ)義分割數(shù)據(jù)集上的結(jié)果.總體而言,在場(chǎng)景分割數(shù)據(jù)集上分割精度越高的算法在語(yǔ)義分割數(shù)據(jù)集上也可以得到越高的分割精度,這說(shuō)明現(xiàn)有場(chǎng)景分割算法在不同的分割子任務(wù)上也具有較好的泛化能力.
8 總結(jié)與展望
本文通過(guò)對(duì)近年來(lái)出現(xiàn)的基于深度學(xué)習(xí)的場(chǎng)景分割算法進(jìn)行梳理和介紹,得到3個(gè)結(jié)論:
1) 目前基于深度學(xué)習(xí)的場(chǎng)景分割算法主要使用了全卷積網(wǎng)絡(luò)框架,該框架利用在大規(guī)模的圖像分類數(shù)據(jù)集上預(yù)訓(xùn)練得到的圖像識(shí)別網(wǎng)絡(luò),全卷積化后遷移到場(chǎng)景分割數(shù)據(jù)集上進(jìn)行重新訓(xùn)練.全卷積網(wǎng)絡(luò)的分割性能優(yōu)于傳統(tǒng)基于圖像特征的場(chǎng)景分割方法,將SIFT Flow數(shù)據(jù)集[51]的像素級(jí)正確率從傳統(tǒng)方法[52]的78.6%提升至85.2%.
2) 針對(duì)場(chǎng)景分割中面臨的分割粒度細(xì)、尺度變化多樣、空間相關(guān)性強(qiáng)3個(gè)主要難點(diǎn)和挑戰(zhàn),在全卷積網(wǎng)絡(luò)的基礎(chǔ)上,研究人員提出諸多基于深度學(xué)習(xí)的場(chǎng)景分割算法.其中針對(duì)分割粒度細(xì)的問(wèn)題,研究人員提出了基于高分辨率語(yǔ)義特征圖的算法,包括利用跨層結(jié)構(gòu)、膨脹卷積、全分辨率語(yǔ)義特征圖的算法;針對(duì)尺度變化多樣的問(wèn)題,研究人員提出了基于多尺度信息的算法,包括利用共享結(jié)構(gòu)、層級(jí)結(jié)構(gòu)、并行結(jié)構(gòu)再進(jìn)行多尺度特征融合和利用自適應(yīng)學(xué)習(xí)多尺度特征的算法;針對(duì)空間相關(guān)性強(qiáng)的問(wèn)題,研究人員提出了基于空間上下文的算法,包括利用多維循環(huán)神經(jīng)網(wǎng)絡(luò)、概率圖模型和注意力機(jī)制的算法.
3) 近年來(lái)基于深度學(xué)習(xí)的場(chǎng)景分割算法的性能取得了極大的提升,例如在Cityscapes數(shù)據(jù)集[53]上的mIoU從57.0%[16]提升至82.1%[57].
基于深度學(xué)習(xí)的算法雖然已經(jīng)成為場(chǎng)景分割的主流方法,但仍然面臨著諸多困難和挑戰(zhàn).除上述場(chǎng)景分割問(wèn)題本身帶來(lái)的困難和挑戰(zhàn)外,還存在4個(gè)更具挑戰(zhàn)性的場(chǎng)景分割問(wèn)題:
1) 基于快速和輕量級(jí)模型的場(chǎng)景分割.為達(dá)到較高的分割精度,目前的場(chǎng)景分割算法傾向于使用較大較深的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),導(dǎo)致計(jì)算復(fù)雜度高、分割速度慢.同時(shí)較大較深的神經(jīng)網(wǎng)絡(luò)包含較多的參數(shù),增加了場(chǎng)景分割模型的存儲(chǔ)開銷.計(jì)算復(fù)雜度高的問(wèn)題限制了場(chǎng)景分割算法在自動(dòng)駕駛、視頻監(jiān)控等場(chǎng)景中的應(yīng)用,而存儲(chǔ)開銷大的問(wèn)題限制了場(chǎng)景分割算法在移動(dòng)平臺(tái)的使用.因此,設(shè)計(jì)快速且輕量級(jí)的場(chǎng)景分割模型具有極大的實(shí)際應(yīng)用價(jià)值.如何對(duì)場(chǎng)景分割算法進(jìn)行模型壓縮、優(yōu)化和加速具有重要的研究意義且極具挑戰(zhàn)性.
2) 基于弱監(jiān)督的場(chǎng)景分割.由于場(chǎng)景分割問(wèn)題需要對(duì)場(chǎng)景圖像中的每個(gè)像素判斷類別,全監(jiān)督的場(chǎng)景分割算法需要依賴大量像素級(jí)的人工標(biāo)注,因此場(chǎng)景分割數(shù)據(jù)集的建立需要大量的人力物力.同時(shí),現(xiàn)有的場(chǎng)景分割數(shù)據(jù)集的圖像和類別數(shù)目有限,制約了場(chǎng)景分割算法的進(jìn)一步發(fā)展.因此,如果利用圖像的弱標(biāo)簽信息,如目標(biāo)框級(jí)別、圖像級(jí)別的標(biāo)注訓(xùn)練場(chǎng)景分割模型,可以大大降低人工標(biāo)注的成本.但利用弱監(jiān)督信息會(huì)大幅度降低場(chǎng)景分割模型的精度.因此,基于弱監(jiān)督的場(chǎng)景分割具有重要的研究意義,也更加具有挑戰(zhàn)性.
3) 基于深度信息的場(chǎng)景分割.現(xiàn)有的大部分場(chǎng)景分割算法主要利用了場(chǎng)景圖像的RGB信息.但在數(shù)據(jù)采集時(shí),可以通過(guò)Kinect等基于紅外的設(shè)備獲同時(shí)取場(chǎng)景的深度信息,并利用RGBD信息設(shè)計(jì)場(chǎng)景分割算法.場(chǎng)景的深度信息相比圖像信息具有較大差異,并在分割空間距離較大的視覺要素時(shí)具有獨(dú)特的優(yōu)勢(shì),例如可以更好地對(duì)前景和背景的邊緣進(jìn)行分割.因此可以利用深度信息對(duì)圖像信息進(jìn)行補(bǔ)充,對(duì)提高場(chǎng)景分割精度具有重要幫助.
4) 基于時(shí)序上下文信息的場(chǎng)景分割.現(xiàn)有的大部分場(chǎng)景分割算法主要利用了靜態(tài)的場(chǎng)景圖像.而在視頻監(jiān)控、自動(dòng)駕駛等實(shí)際應(yīng)用場(chǎng)景中,可以獲取場(chǎng)景圖像的時(shí)序上下文信息.可以通過(guò)挖掘時(shí)序上下文信息中的時(shí)序連續(xù)性提升場(chǎng)景分割精度.同時(shí)時(shí)序上連續(xù)的場(chǎng)景圖像也可以增加場(chǎng)景分割數(shù)據(jù)集的規(guī)模.因此,基于時(shí)序上下文信息的場(chǎng)景分割在實(shí)際應(yīng)用中具有重要的研究?jī)r(jià)值.
審核編輯:湯梓紅

































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論