 電子發(fā)燒友App
電子發(fā)燒友App


基礎(chǔ)模型的出現(xiàn)徹底改變了自然語(yǔ)言處理和計(jì)算機(jī)視覺(jué)領(lǐng)域,為其在自動(dòng)駕駛(AD)中的應(yīng)用鋪平了道路。這項(xiàng)調(diào)查對(duì)40多篇研究論文進(jìn)行了全面回顧,展示了基礎(chǔ)模型在增強(qiáng)AD中的作用。大型語(yǔ)言模型有助于AD的規(guī)劃和模擬,特別是通過(guò)其在推理、代碼生成和翻譯方面的熟練程度。與此同時(shí),視覺(jué)基礎(chǔ)模型越來(lái)越適用于關(guān)鍵任務(wù),如3D目標(biāo)檢測(cè)和跟蹤,以及為仿真和測(cè)試創(chuàng)建逼真的駕駛場(chǎng)景。多模態(tài)基礎(chǔ)模型,集成了不同的輸入,顯示了非凡的視覺(jué)理解和空間推理,對(duì)端到端AD至關(guān)重要。這項(xiàng)調(diào)查不僅提供了一個(gè)結(jié)構(gòu)化的分類(lèi)法,根據(jù)基礎(chǔ)模型在AD領(lǐng)域的模式和功能對(duì)其進(jìn)行分類(lèi),還深入研究了當(dāng)前研究中使用的方法。它確定了現(xiàn)有基礎(chǔ)模型和尖端AD方法之間的差距,從而規(guī)劃了未來(lái)的研究方向,并提出了彌合這些差距的路線圖。
簡(jiǎn)介
深度學(xué)習(xí)(DL)與自動(dòng)駕駛(AD)的融合標(biāo)志著該領(lǐng)域的重大飛躍,吸引了學(xué)術(shù)界和工業(yè)界的關(guān)注。配備了攝像頭和激光雷達(dá)的AD系統(tǒng)模擬了類(lèi)似人類(lèi)的決策過(guò)程。這些系統(tǒng)基本上由三個(gè)關(guān)鍵組成部分組成:感知、預(yù)測(cè)和規(guī)劃。Perception利用DL和計(jì)算機(jī)視覺(jué)算法,專(zhuān)注于物體檢測(cè)和跟蹤。預(yù)測(cè)預(yù)測(cè)交通代理的行為及其與自動(dòng)駕駛汽車(chē)的相互作用。規(guī)劃通常是分層結(jié)構(gòu)的,包括做出戰(zhàn)略性駕駛決策、計(jì)算最佳軌跡和執(zhí)行車(chē)輛控制命令。基礎(chǔ)模型的出現(xiàn),特別是在自然語(yǔ)言處理和計(jì)算機(jī)視覺(jué)領(lǐng)域,為AD研究引入了新的維度。這些模型是不同的,因?yàn)樗鼈冊(cè)趶V泛的網(wǎng)絡(luò)規(guī)模數(shù)據(jù)集上進(jìn)行訓(xùn)練,并且參數(shù)大小巨大。考慮到自動(dòng)駕駛汽車(chē)服務(wù)產(chǎn)生的大量數(shù)據(jù)和人工智能的進(jìn)步,包括NLP和人工智能生成內(nèi)容(AIGC),人們對(duì)基礎(chǔ)模型在AD中的潛力越來(lái)越好奇。這些模型可能有助于執(zhí)行一系列AD任務(wù),如物體檢測(cè)、場(chǎng)景理解和決策,具有與人類(lèi)駕駛員相似的智力水平。
基礎(chǔ)模型解決了AD中的幾個(gè)挑戰(zhàn)。傳統(tǒng)上,AD模型是以監(jiān)督的方式訓(xùn)練的,依賴(lài)于手動(dòng)注釋的數(shù)據(jù),這些數(shù)據(jù)往往缺乏多樣性,限制了它們的適應(yīng)性。然而,基礎(chǔ)模型由于在不同的網(wǎng)絡(luò)規(guī)模數(shù)據(jù)上進(jìn)行訓(xùn)練,顯示出卓越的泛化能力。它們可以用從廣泛的預(yù)訓(xùn)練中獲得的推理能力和知識(shí),潛在地取代規(guī)劃中復(fù)雜的啟發(fā)式基于規(guī)則的系統(tǒng)。例如,LLM具有從預(yù)訓(xùn)練數(shù)據(jù)集中獲得的推理能力和常識(shí)性駕駛知識(shí),這可能會(huì)取代啟發(fā)式基于規(guī)則的規(guī)劃系統(tǒng),后者需要在軟件代碼中手工制定規(guī)則并在角落案例中進(jìn)行調(diào)試的復(fù)雜工程工作。該領(lǐng)域中的生成模型可以為模擬創(chuàng)建真實(shí)的交通場(chǎng)景,這對(duì)于在罕見(jiàn)或具有挑戰(zhàn)性的情況下測(cè)試安全性和可靠性至關(guān)重要。此外,基礎(chǔ)模型有助于使AD技術(shù)更加以用戶為中心,語(yǔ)言模型可以用自然語(yǔ)言理解和執(zhí)行用戶命令。
盡管在將基礎(chǔ)模型應(yīng)用于AD方面進(jìn)行了大量研究,但在實(shí)際應(yīng)用中仍存在顯著的局限性和差距。我們的調(diào)查旨在提供一個(gè)系統(tǒng)的重新審視,并提出未來(lái)的研究方向。LLM4Drive更側(cè)重于大型語(yǔ)言模型。我們?cè)诂F(xiàn)有調(diào)查的基礎(chǔ)上,涵蓋了視覺(jué)基礎(chǔ)模型和多模態(tài)基礎(chǔ)模型,分析了它們?cè)陬A(yù)測(cè)和感知任務(wù)中的應(yīng)用。這種綜合方法包括對(duì)技術(shù)方面的詳細(xì)檢查,如預(yù)先訓(xùn)練的模型和方法,并確定未來(lái)的研究機(jī)會(huì)。創(chuàng)新性地,我們提出了一種基于模式和功能對(duì)AD中的基礎(chǔ)模型進(jìn)行分類(lèi)的分類(lèi)法,如圖1所示。以下部分將探討各種基礎(chǔ)模型在AD環(huán)境中的應(yīng)用,包括大型語(yǔ)言模型、視覺(jué)基礎(chǔ)模型和多模態(tài)基礎(chǔ)模型。
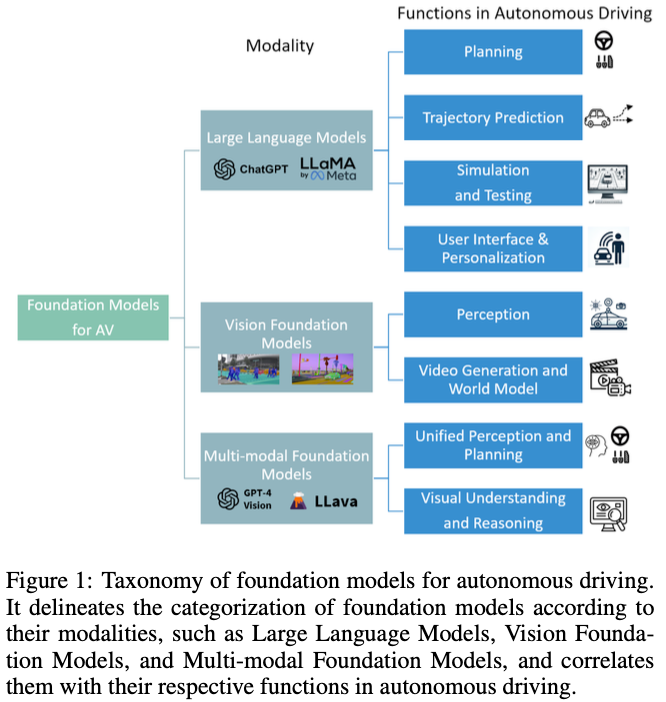
Large Language Models in AD
概述
LLM最初在NLP中具有變革性,現(xiàn)在正在推動(dòng)AD的創(chuàng)新。BERT開(kāi)創(chuàng)了NLP中的基礎(chǔ)模型,利用轉(zhuǎn)換器架構(gòu)來(lái)理解語(yǔ)言語(yǔ)義。這種預(yù)先訓(xùn)練的模型可以在特定的數(shù)據(jù)集上進(jìn)行微調(diào),并在廣泛的任務(wù)中實(shí)現(xiàn)最先進(jìn)的結(jié)果。在此之后,OpenAI的生成預(yù)訓(xùn)練轉(zhuǎn)換器(GPT)系列,包括GPT-4,由于在廣泛的數(shù)據(jù)集上進(jìn)行了訓(xùn)練,展示了非凡的NLP能力。后來(lái)的GPT模型,包括ChatGPT、GPT-4,使用數(shù)十億個(gè)參數(shù)和數(shù)萬(wàn)億個(gè)單詞的爬行網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行訓(xùn)練,并在許多NLP任務(wù)上取得了強(qiáng)大的性能,包括翻譯、文本摘要、問(wèn)題回答。它還展示了從上下文中學(xué)習(xí)新技能的一次性和少量推理能力。越來(lái)越3多的研究人員已經(jīng)開(kāi)始應(yīng)用這些推理、理解和上下文學(xué)習(xí)能力來(lái)應(yīng)對(duì)AD中的挑戰(zhàn)。
AD中的應(yīng)用
推理與規(guī)劃
AD的決策過(guò)程與人類(lèi)推理密切相似,因此必須對(duì)環(huán)境線索進(jìn)行解釋?zhuān)拍茏龀霭踩孢m的駕駛決策。LLM通過(guò)對(duì)各種網(wǎng)絡(luò)數(shù)據(jù)的培訓(xùn),吸收了與駕駛相關(guān)的常識(shí)性知識(shí),這些知識(shí)來(lái)自包括網(wǎng)絡(luò)論壇和政府官方網(wǎng)站在內(nèi)的眾多來(lái)源。這些豐富的信息使LLM能夠參與AD所需的細(xì)微決策。在AD中利用LLM的一種方法是向他們提供駕駛環(huán)境的詳細(xì)文本描述,促使他們提出駕駛決策或控制命令。如圖2所示,這個(gè)過(guò)程通常包括全面的提示,詳細(xì)說(shuō)明代理狀態(tài),如坐標(biāo)、速度和過(guò)去的軌跡,車(chē)輛的狀態(tài),即速度和加速度,以及地圖細(xì)節(jié),包括紅綠燈、車(chē)道信息和預(yù)定路線)。為了增強(qiáng)對(duì)交互的理解,LLM還可以被引導(dǎo)在其響應(yīng)的同時(shí)提供推理。例如,GPT駕駛員不僅建議車(chē)輛行動(dòng),還闡明了這些建議背后的理由,大大提高了自動(dòng)駕駛決策的透明度和可解釋性。這種方法,以LLM駕駛為例,增強(qiáng)了自動(dòng)駕駛決策的可解釋性。同樣,“接收、推理和反應(yīng)”方法指示LLM代理人評(píng)估車(chē)道占用情況并評(píng)估潛在行動(dòng)的安全性,從而促進(jìn)對(duì)動(dòng)態(tài)駕駛場(chǎng)景的更深入理解。這些方法不僅利用LLM理解復(fù)雜場(chǎng)景的固有能力,還利用它們的推理能力來(lái)模擬類(lèi)似人類(lèi)的決策過(guò)程。通過(guò)整合詳細(xì)的環(huán)境描述和戰(zhàn)略提示,LLM對(duì)AD的規(guī)劃和推理方面做出了重大貢獻(xiàn),提供了反映人類(lèi)判斷和專(zhuān)業(yè)知識(shí)的見(jiàn)解和決策。
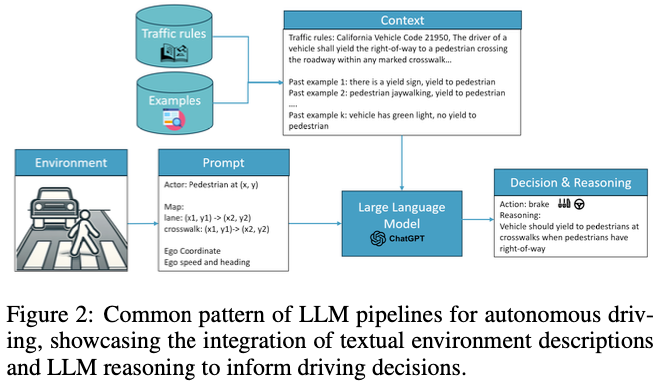
預(yù)測(cè)
Prediction預(yù)測(cè)交通參與者未來(lái)的軌跡、意圖以及可能與自車(chē)交通工具的互動(dòng)。常見(jiàn)的基于深度學(xué)習(xí)的模型基于交通場(chǎng)景的光柵化或矢量圖像,對(duì)空間信息進(jìn)行編碼。然而,準(zhǔn)確預(yù)測(cè)高度互動(dòng)的場(chǎng)景仍然具有挑戰(zhàn)性,這需要推理和語(yǔ)義信息,例如路權(quán)、車(chē)輛的轉(zhuǎn)向信號(hào)和行人的手勢(shì)。場(chǎng)景的文本表示可以提供更多的語(yǔ)義信息,并更好地利用LLM的推理能力和預(yù)訓(xùn)練數(shù)據(jù)集中的公共知識(shí)。將LLM應(yīng)用于軌跡預(yù)測(cè)的研究還不多。與僅使用圖像編碼或文本編碼的基線相比,他們的評(píng)估顯示出顯著的改進(jìn)。
用戶界面和個(gè)性化
自動(dòng)駕駛汽車(chē)應(yīng)便于用戶使用,并能夠遵循乘客或遠(yuǎn)程操作員的指示。當(dāng)前的Robotaxi遠(yuǎn)程輔助界面僅用于執(zhí)行一組有限的預(yù)定義命令。然而,LLM的理解和交互能力使自動(dòng)駕駛汽車(chē)能夠理解人類(lèi)的自由形式指令,從而更好地控制自動(dòng)駕駛汽車(chē),滿足用戶的個(gè)性化需求。LLM代理還能夠基于預(yù)定義的業(yè)務(wù)規(guī)則和系統(tǒng)要求來(lái)接受或拒絕用戶命令。
仿真和測(cè)試
LLM可以從現(xiàn)有的文本數(shù)據(jù)中總結(jié)和提取知識(shí),并生成新的內(nèi)容,這有助于仿真和測(cè)試。ADEPT系統(tǒng)使用GPT使用QA方法從NHTSA事故報(bào)告中提取關(guān)鍵信息,并能夠生成用于模擬和測(cè)試的各種場(chǎng)景代碼。TARGET系統(tǒng)能夠使用GPT將流量規(guī)則從自然語(yǔ)言轉(zhuǎn)換為特定領(lǐng)域的語(yǔ)言,用于生成測(cè)試場(chǎng)景。LCTGen使用LLM作為強(qiáng)大的解釋器,將用戶的文本查詢(xún)轉(zhuǎn)換為交通模擬場(chǎng)景中地圖車(chē)道和車(chē)輛位置的結(jié)構(gòu)化規(guī)范。
方法和技巧
研究人員在自然語(yǔ)言處理中使用類(lèi)似的技術(shù),將LLM用于自動(dòng)駕駛?cè)蝿?wù),如即時(shí)工程、上下文和少鏡頭學(xué)習(xí),以及來(lái)自人類(lèi)反饋的強(qiáng)化學(xué)習(xí)。
Prompt Engineering
Prompt engineering采用復(fù)雜的輸入提示和問(wèn)題設(shè)計(jì)來(lái)指導(dǎo)大型語(yǔ)言模型生成我們想要的答案。
一些論文增加了交通規(guī)則作為前置提示,以使LLM代理符合法律。Driving with LLMs有交通規(guī)則,涵蓋紅綠燈過(guò)渡和左側(cè)或右側(cè)駕駛等方面。
LanguageMPC采用自上而下的決策系統(tǒng):給定不同的情況,車(chē)輛有不同的可能動(dòng)作。LLM代理還被指示識(shí)別場(chǎng)景中的重要代理,并輸出注意力、權(quán)重和偏差矩陣,以從預(yù)先定義的動(dòng)作中進(jìn)行選擇。
Fine-tuning v.s. In-context Learning
微調(diào)和上下文學(xué)習(xí)都用于使預(yù)先訓(xùn)練的模型適應(yīng)自動(dòng)駕駛。微調(diào)在較小的特定領(lǐng)域數(shù)據(jù)集上重新訓(xùn)練模型參數(shù),而上下文學(xué)習(xí)或少鏡頭學(xué)習(xí)利用LLM的知識(shí)和推理能力,在輸入提示中從給定的例子中學(xué)習(xí)。大多數(shù)論文都專(zhuān)注于上下文學(xué)習(xí),但只有少數(shù)論文使用微調(diào)。研究人員對(duì)哪一個(gè)更好的結(jié)果喜憂參半:GPT-Driver有一個(gè)不同的結(jié)論,即使用OpenAI微調(diào)比少鏡頭學(xué)習(xí)表現(xiàn)得更好。
強(qiáng)化學(xué)習(xí)和人類(lèi)反饋
DILU提出了反射模塊,通過(guò)人工校正來(lái)存儲(chǔ)好的駕駛示例和壞的駕駛示例,以進(jìn)一步增強(qiáng)其推理能力。通過(guò)這種方式,LLM可以學(xué)會(huì)思考什么行動(dòng)是安全的和不安全的,并不斷反思過(guò)去的大量駕駛經(jīng)驗(yàn)。Surreal Driver采訪了24名駕駛員,并將他們對(duì)駕駛行為的描述作為思維鏈提示,開(kāi)發(fā)了一個(gè)“教練-代理”模塊,該模塊可以指導(dǎo)LLM模型具有類(lèi)似人類(lèi)的駕駛風(fēng)格。
限制和未來(lái)方向
幻覺(jué)與危害
幻覺(jué)是LLM中的一大挑戰(zhàn),最先進(jìn)的大型語(yǔ)言模型仍然會(huì)產(chǎn)生誤導(dǎo)和虛假信息。現(xiàn)有論文中提出的大多數(shù)方法仍然需要從LLM的響應(yīng)中解析驅(qū)動(dòng)動(dòng)作。當(dāng)給定一個(gè)看不見(jiàn)的場(chǎng)景時(shí),LLM模型仍然可能產(chǎn)生無(wú)益或錯(cuò)誤的駕駛決策。自動(dòng)駕駛是一種安全關(guān)鍵應(yīng)用程序,其可靠性和安全性要求遠(yuǎn)高于聊天機(jī)器人。根據(jù)評(píng)估結(jié)果,用于自動(dòng)駕駛的LLM模型的碰撞率為0.44%,高于其他方法。經(jīng)過(guò)預(yù)先培訓(xùn)的LLM也可能包括有害內(nèi)容,例如,激烈駕駛和超速行駛。更多的人在環(huán)訓(xùn)練和調(diào)整可以減少幻覺(jué)和有害的駕駛決策。
耗時(shí)和效率
大型語(yǔ)言模型通常存在高延遲,生成詳細(xì)的駕駛決策可能會(huì)耗盡車(chē)內(nèi)有限計(jì)算資源的延遲預(yù)算。推理需要幾秒鐘的時(shí)間。具有數(shù)十億個(gè)參數(shù)的LLM可能會(huì)消耗超過(guò)100GB的內(nèi)存,這可能會(huì)干擾自動(dòng)駕駛汽車(chē)中的其他關(guān)鍵模塊。在這一領(lǐng)域還需要做更多的研究,如模型壓縮和知識(shí)提取,以使LLM更高效、更容易部署。
對(duì)感知系統(tǒng)的依賴(lài)
盡管LLM具有最高的推理能力,但環(huán)境描述仍然依賴(lài)于上游感知模塊。駕駛決策可能會(huì)出錯(cuò),并在環(huán)境輸入中出現(xiàn)輕微錯(cuò)誤,從而導(dǎo)致重大事故。LLM還需要更好地適應(yīng)感知模型,并在出現(xiàn)錯(cuò)誤和不確定性時(shí)做出更好的決策。
Sim to Real Gap
大多數(shù)研究都是在仿真環(huán)境中進(jìn)行的,駕駛場(chǎng)景比真實(shí)世界的環(huán)境簡(jiǎn)單得多。為了覆蓋現(xiàn)實(shí)世界中的所有場(chǎng)景,需要進(jìn)行大量的工程和人類(lèi)詳細(xì)的注釋工作,例如,該模型知道如何向人類(lèi)屈服,但可能不擅長(zhǎng)處理與小動(dòng)物的互動(dòng)。
視覺(jué)基礎(chǔ)模型
視覺(jué)基礎(chǔ)模型在多個(gè)計(jì)算機(jī)視覺(jué)任務(wù)中取得了巨大成功,如物體檢測(cè)和分割。DINO使用ViT架構(gòu),并以自監(jiān)督的方式進(jìn)行訓(xùn)練,在給定局部圖像塊的情況下預(yù)測(cè)全局圖像特征。DINOV2利用10億個(gè)參數(shù)和12億幅圖像的多樣化數(shù)據(jù)集對(duì)訓(xùn)練進(jìn)行了擴(kuò)展,并在多任務(wù)中取得了最先進(jìn)的結(jié)果。Segment-anything模型是圖像分割的基礎(chǔ)模型。該模型使用不同類(lèi)型的提示(點(diǎn)、框或文本)進(jìn)行訓(xùn)練,以生成分割掩碼。在數(shù)據(jù)集中使用數(shù)十億分割掩碼進(jìn)行訓(xùn)練后,該模型顯示了零樣本傳遞能力,可以在適當(dāng)?shù)奶崾鞠路指钚履繕?biāo)。
擴(kuò)散模型是一種廣泛應(yīng)用于圖像生成的生成基礎(chǔ)模型。擴(kuò)散模型迭代地將噪聲添加到圖像,并應(yīng)用反向擴(kuò)散過(guò)程來(lái)恢復(fù)圖像。為了生成圖像,我們可以從學(xué)習(xí)的分布中進(jìn)行采樣,并從隨機(jī)噪聲中恢復(fù)高度逼真的圖像。穩(wěn)定擴(kuò)散模型使用VAE將圖像編碼為潛在表示,并使用UNet將潛在變量解碼為逐像素圖像。它還有一個(gè)可選的文本編碼器,并應(yīng)用交叉注意力機(jī)制生成基于提示的圖像(文本描述或其他圖像)。DALL-E模型使用數(shù)十億對(duì)圖像和文本進(jìn)行訓(xùn)練,并使用穩(wěn)定的擴(kuò)散來(lái)生成高保真圖像和遵循人類(lèi)指令的創(chuàng)造性藝術(shù)。
人們對(duì)視覺(jué)基礎(chǔ)模型在自動(dòng)駕駛中的應(yīng)用越來(lái)越感興趣,主要用于3D感知和視頻生成任務(wù)。
感知
SAM3D將SAM應(yīng)用于自動(dòng)駕駛中的3D物體檢測(cè)。激光雷達(dá)點(diǎn)云被投影到BEV(鳥(niǎo)瞰圖)圖像中,它使用32x32網(wǎng)格生成點(diǎn)提示,以檢測(cè)前景目標(biāo)的遮罩。它利用SAM模型的零樣本傳輸能力來(lái)生成分割掩模和2D盒。然后,它使用2D box內(nèi)的激光雷達(dá)點(diǎn)的垂直屬性來(lái)生成3D box。然而,Waymo開(kāi)放數(shù)據(jù)集評(píng)估顯示,平均精度指標(biāo)與現(xiàn)有最先進(jìn)的3D目標(biāo)檢測(cè)模型仍有很大差距。他們觀察到,SAM訓(xùn)練的基礎(chǔ)模型不能很好地處理那些稀疏和有噪聲的點(diǎn),并且經(jīng)常導(dǎo)致對(duì)遠(yuǎn)處物體的假陰性。
SAM應(yīng)用于3D分割任務(wù)的領(lǐng)域自適應(yīng),利用SAM模型的特征空間,該特征空間包含更多的語(yǔ)義信息和泛化能力。
SAM和Grounding DINO用于創(chuàng)建一個(gè)統(tǒng)一的分割和跟蹤框架,利用視頻幀之間的時(shí)間一致性。Grounding DINO是一個(gè)開(kāi)放集目標(biāo)檢測(cè)器,它從目標(biāo)的文本描述中獲取輸入并輸出相應(yīng)的邊界框。給定與自動(dòng)駕駛相關(guān)的目標(biāo)類(lèi)的文本提示,它可以檢測(cè)視頻幀中的目標(biāo),并生成車(chē)輛和行人的邊界框。SAM模型進(jìn)一步將這些框作為提示,并為檢測(cè)到的目標(biāo)生成分割掩碼。然后將生成的目標(biāo)掩碼傳遞給下游跟蹤器,后者比較連續(xù)幀中的掩碼,以確定是否存在新目標(biāo)。
視頻生成和世界模型
基礎(chǔ)模型,特別是生成模型和世界模型可以生成逼真的虛擬駕駛場(chǎng)景,用于自動(dòng)駕駛仿真。許多研究人員已經(jīng)開(kāi)始將擴(kuò)散模型應(yīng)用于真實(shí)場(chǎng)景生成的自動(dòng)駕駛。視頻生成問(wèn)題通常被公式化為一個(gè)世界模型:給定當(dāng)前世界狀態(tài),以環(huán)境輸入為條件,該模型預(yù)測(cè)下一個(gè)世界狀態(tài),并使用擴(kuò)散來(lái)解碼高度逼真的駕駛場(chǎng)景。
GAIA-1由Wayve開(kāi)發(fā),用于生成逼真的駕駛視頻。世界模型使用相機(jī)圖像、文本描述和車(chē)輛控制信號(hào)作為輸入標(biāo)記,并預(yù)測(cè)下一幀。本文利用預(yù)訓(xùn)練的DINO模型的嵌入和余弦相似性損失提取更多的語(yǔ)義知識(shí)用于圖像標(biāo)記嵌入。他們使用視頻擴(kuò)散模型從預(yù)測(cè)的圖像標(biāo)記中解碼高保真駕駛場(chǎng)景。有兩個(gè)單獨(dú)的任務(wù)來(lái)訓(xùn)練擴(kuò)散模型:圖像生成和視頻生成。圖像生成任務(wù)幫助解碼器生成高質(zhì)量的圖像,而視頻生成任務(wù)使用時(shí)間注意力來(lái)生成時(shí)間一致的視頻幀。生成的視頻遵循高級(jí)真實(shí)世界約束,并具有逼真的場(chǎng)景動(dòng)力學(xué),例如目標(biāo)的位置、交互、交通規(guī)則和道路結(jié)構(gòu)。視頻還展示了多樣性和創(chuàng)造力,這些都有現(xiàn)實(shí)的可能結(jié)果,取決于不同的文本描述和自我載體的行動(dòng)。
DriveDreamer還使用世界模型和擴(kuò)散模型為自動(dòng)駕駛生成視頻。除了圖像、文本描述和車(chē)輛動(dòng)作,該模型還使用了更多的結(jié)構(gòu)性交通信息作為輸入,如HDMap和目標(biāo)3D框,使模型能夠更好地理解交通場(chǎng)景的更高層結(jié)構(gòu)約束。模型訓(xùn)練分為兩個(gè)階段:第一階段是使用基于結(jié)構(gòu)化交通信息的擴(kuò)散模型生成視頻。
限制和未來(lái)方向
目前最先進(jìn)的基礎(chǔ)模型(如SAM)對(duì)于3D自動(dòng)駕駛感知任務(wù)(如物體檢測(cè)和分割)沒(méi)有足夠好的零樣本泛化能力。自動(dòng)駕駛感知依賴(lài)于多個(gè)攝像頭、激光雷達(dá)和傳感器融合來(lái)獲得最高精度的物體檢測(cè)結(jié)果,這與從網(wǎng)絡(luò)上隨機(jī)收集的圖像數(shù)據(jù)集大不相同。當(dāng)前用于自動(dòng)駕駛感知任務(wù)的公共數(shù)據(jù)集的規(guī)模仍然不足以訓(xùn)練基礎(chǔ)模型并覆蓋所有可能的長(zhǎng)尾場(chǎng)景。盡管存在局限性,現(xiàn)有的2D視覺(jué)基礎(chǔ)模型可以作為有用的特征提取器進(jìn)行知識(shí)提取,這有助于模型更好地結(jié)合語(yǔ)義信息。在視頻生成和預(yù)測(cè)任務(wù)領(lǐng)域,我們已經(jīng)看到了利用現(xiàn)有擴(kuò)散模型進(jìn)行視頻生成和點(diǎn)云預(yù)測(cè)的有希望的進(jìn)展,這可以進(jìn)一步應(yīng)用于創(chuàng)建自動(dòng)駕駛模擬和測(cè)試的高保真場(chǎng)景。
多模態(tài)基礎(chǔ)模型
多模態(tài)基礎(chǔ)模型通過(guò)從多種模態(tài)(如聲音、圖像和視頻)獲取輸入數(shù)據(jù)來(lái)執(zhí)行更復(fù)雜的任務(wù),例如從圖像生成文本、使用視覺(jué)輸入進(jìn)行分析和推理,從而受益更多。
最著名的多模態(tài)基礎(chǔ)模型之一是CLIP。使用對(duì)比預(yù)訓(xùn)練方法對(duì)模型進(jìn)行預(yù)訓(xùn)練。輸入是有噪聲的圖像和文本對(duì),并且訓(xùn)練模型來(lái)預(yù)測(cè)給定的圖像和文字是否是正確的對(duì)。訓(xùn)練該模型以最大化來(lái)自圖像編碼器和文本編碼器的嵌入的余弦相似性。CLIP模型顯示了其他計(jì)算機(jī)視覺(jué)任務(wù)的零樣本轉(zhuǎn)移能力,如圖像分類(lèi),以及在沒(méi)有監(jiān)督訓(xùn)練的情況下預(yù)測(cè)類(lèi)的正確文本描述。
LLaVA、LISA和CogVLM等多模態(tài)基礎(chǔ)模型可用于通用視覺(jué)人工智能代理,它在視覺(jué)任務(wù)中表現(xiàn)出優(yōu)異的性能,如目標(biāo)分割、檢測(cè)、定位和空間推理。
將通用知識(shí)從大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)集轉(zhuǎn)移到自動(dòng)駕駛中,多模態(tài)基礎(chǔ)模型可用于目標(biāo)檢測(cè)、視覺(jué)理解和空間推理,從而在自動(dòng)駕駛中實(shí)現(xiàn)更強(qiáng)大的應(yīng)用。
視覺(jué)理解和推理
傳統(tǒng)的物體檢測(cè)或分類(lèi)模型對(duì)于自動(dòng)駕駛來(lái)說(shuō)是不夠的,因?yàn)槲覀冃枰玫乩斫鈭?chǎng)景的語(yǔ)義和視覺(jué)推理,例如識(shí)別危險(xiǎn)物體,了解交通參與者的意圖。現(xiàn)有的基于深度學(xué)習(xí)的預(yù)測(cè)和規(guī)劃模型大多是暗箱模型,當(dāng)事故或不適事件發(fā)生時(shí),這些模型的可解釋性和可調(diào)試性較差。在多模態(tài)基礎(chǔ)模型的幫助下,我們可以生成模型的解釋和推理過(guò)程,以更好地研究問(wèn)題。
Talk2BEV提出了一種融合視覺(jué)和語(yǔ)義信息的場(chǎng)景創(chuàng)新鳥(niǎo)瞰圖(BEV)表示。該管道首先從圖像和激光雷達(dá)數(shù)據(jù)中生成BEV地圖,并使用通用視覺(jué)語(yǔ)言基礎(chǔ)模型添加對(duì)物體裁剪圖像的更詳細(xì)的文本描述。然后,BEV映射的JSON文本表示被傳遞給通用LLM,以執(zhí)行Visual QA,其中包括空間和視覺(jué)推理任務(wù)。結(jié)果表明,它很好地理解了詳細(xì)的實(shí)例屬性和目標(biāo)的更高層次意圖,并能夠就自我載體的行為提供自由形成的建議。
統(tǒng)一感知和規(guī)劃
Wen對(duì)GPT-4Vision在感知和規(guī)劃任務(wù)中的應(yīng)用進(jìn)行了早期探索,并評(píng)估了其在幾個(gè)場(chǎng)景中的能力。它表明GPT-4Vision可以了解天氣、交通標(biāo)志和紅綠燈,并識(shí)別場(chǎng)景中的交通參與者。它還可以提供這些目標(biāo)的更詳細(xì)的語(yǔ)義描述,如車(chē)輛尾燈、U型轉(zhuǎn)彎等意圖和詳細(xì)的車(chē)輛類(lèi)型(如水泥攪拌車(chē)、拖車(chē)和SUV)。它還顯示了基礎(chǔ)模型理解點(diǎn)云數(shù)據(jù)的潛力,GPT-4V可以從BEV圖像中投影的點(diǎn)云輪廓識(shí)別車(chē)輛。他們還評(píng)估了模型在規(guī)劃任務(wù)中的性能。考慮到交通場(chǎng)景,GPT4-V被要求描述其對(duì)車(chē)輛行動(dòng)的觀察和決定。結(jié)果顯示,與其他交通參與者的互動(dòng)良好,遵守了交通規(guī)則和常識(shí),例如在安全距離內(nèi)跟車(chē),在人行橫道上向騎自行車(chē)的人讓行,在綠燈變綠之前保持停車(chē)。它甚至可以很好地處理一些長(zhǎng)尾場(chǎng)景,比如門(mén)控停車(chē)場(chǎng)。
限制和未來(lái)方向
多模態(tài)基礎(chǔ)模型顯示了自動(dòng)駕駛?cè)蝿?wù)所需的空間和視覺(jué)推理能力。與傳統(tǒng)的目標(biāo)檢測(cè)相比,在閉集數(shù)據(jù)集上訓(xùn)練的分類(lèi)模型、視覺(jué)推理能力和自由形式的文本描述可以提供更豐富的語(yǔ)義信息,可以解決許多長(zhǎng)尾檢測(cè)問(wèn)題,如特種車(chē)輛的分類(lèi)、警察和交通管制員對(duì)手勢(shì)的理解。多模態(tài)基礎(chǔ)模型具有良好的泛化能力,可以很好地利用常識(shí)處理一些具有挑戰(zhàn)性的長(zhǎng)尾場(chǎng)景,例如在受控訪問(wèn)的門(mén)口停車(chē)。進(jìn)一步利用其規(guī)劃任務(wù)的推理能力,視覺(jué)語(yǔ)言模型可用于統(tǒng)一感知規(guī)劃和端到端自動(dòng)駕駛。
多基礎(chǔ)模型在自動(dòng)駕駛中仍然存在局限性。GPT-4V模型仍然存在幻覺(jué),并在幾個(gè)例子中產(chǎn)生不清楚的反應(yīng)或錯(cuò)誤的答案。該模型還顯示出在利用多視圖相機(jī)和激光雷達(dá)數(shù)據(jù)進(jìn)行精確的3D物體檢測(cè)和定位方面的無(wú)能,因?yàn)轭A(yù)訓(xùn)練數(shù)據(jù)集只包含來(lái)自網(wǎng)絡(luò)的2D圖像。需要更多特定領(lǐng)域的微調(diào)或預(yù)訓(xùn)練來(lái)訓(xùn)練多模態(tài)基礎(chǔ)模型,以更好地理解點(diǎn)云數(shù)據(jù)和傳感器融合,從而實(shí)現(xiàn)最先進(jìn)的感知系統(tǒng)的可比性能。
結(jié)論和未來(lái)方向
我們對(duì)最近將基礎(chǔ)模型應(yīng)用于自動(dòng)駕駛的論文進(jìn)行了總結(jié)和分類(lèi)。我們基于自動(dòng)駕駛中的模態(tài)和功能建立了一個(gè)新的分類(lèi)法。我們?cè)敿?xì)討論了使基礎(chǔ)模型適應(yīng)自動(dòng)駕駛的方法和技術(shù),例如上下文學(xué)習(xí)、微調(diào)、強(qiáng)化學(xué)習(xí)和視覺(jué)教學(xué)調(diào)整。我們還分析了自動(dòng)駕駛基礎(chǔ)模型的局限性,如幻覺(jué)、延遲和效率,以及數(shù)據(jù)集中的領(lǐng)域差距,從而提出了以下研究方向:
在自動(dòng)駕駛數(shù)據(jù)集上進(jìn)行特定領(lǐng)域的預(yù)訓(xùn)練或微調(diào);
強(qiáng)化學(xué)習(xí)和人在環(huán)對(duì)齊,以提高安全性并減少幻覺(jué);
2D基礎(chǔ)模型對(duì)3D的適應(yīng),例如語(yǔ)言引導(dǎo)的傳感器融合、微調(diào)或3D數(shù)據(jù)集上的few-shot學(xué)習(xí);
用于將基礎(chǔ)模型部署到車(chē)輛的延遲和內(nèi)存優(yōu)化、模型壓縮和知識(shí)提取。
我們還注意到,數(shù)據(jù)集是自動(dòng)駕駛基礎(chǔ)模型未來(lái)發(fā)展的最大障礙之一。現(xiàn)有的1000小時(shí)規(guī)模的自動(dòng)駕駛開(kāi)源數(shù)據(jù)集遠(yuǎn)遠(yuǎn)少于最先進(jìn)的LLM所使用的預(yù)訓(xùn)練數(shù)據(jù)集。用于現(xiàn)有基礎(chǔ)模型的網(wǎng)絡(luò)數(shù)據(jù)集并沒(méi)有利用自動(dòng)駕駛所需的所有模式,如激光雷達(dá)和環(huán)視攝像頭。網(wǎng)絡(luò)數(shù)據(jù)域也與真實(shí)的駕駛場(chǎng)景大不相同。
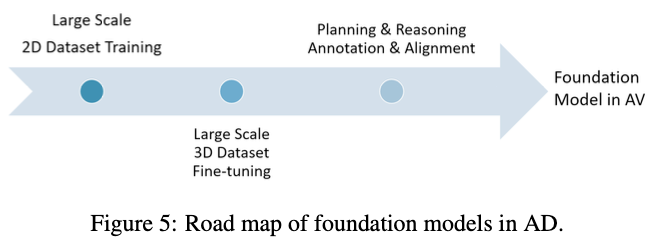
我們?cè)趫D5中提出了長(zhǎng)期的未來(lái)路線圖。在第一階段,我們可以收集一個(gè)大規(guī)模的2D數(shù)據(jù)集,該數(shù)據(jù)集可以覆蓋真實(shí)世界環(huán)境中駕駛場(chǎng)景的所有數(shù)據(jù)分布、多樣性和復(fù)雜性,用于預(yù)訓(xùn)練或微調(diào)。大多數(shù)車(chē)輛都可以配備前置攝像頭,在一天中的不同時(shí)間收集不同城市的數(shù)據(jù)。在第二階段,我們可以使用激光雷達(dá)使用更小但質(zhì)量更高的3D數(shù)據(jù)集來(lái)改善基礎(chǔ)模型的3D感知和推理,例如,我們可以作為教師使用現(xiàn)有最先進(jìn)的3D目標(biāo)檢測(cè)模型來(lái)微調(diào)基礎(chǔ)模型。最后,我們可以在規(guī)劃和推理中利用人類(lèi)駕駛示例或注釋來(lái)進(jìn)行對(duì)齊,從而達(dá)到自動(dòng)駕駛的最大安全目標(biāo)。
審核編輯:黃飛
?










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論