 電子發燒友App
電子發燒友App


Index
多層感知機(MLP)介紹
深度神經網絡的激活函數
深度神經網絡的損失函數
多層感知機的反向傳播算法
神經網絡的訓練技巧
深度卷積神經網絡
前饋神經網絡(feedforward neural network)是一種最簡單的神經網絡,各神經元分層排列。每個神經元只與前一層的神經元相連。接收前一層的輸出,并輸出給下一層.各層間沒有反饋。是目前應用最廣泛、發展最迅速的人工神經網絡之一。研究從20世紀60年代開始,目前理論研究和實際應用達到了很高的水平。
——百度百科
而深度學習模型,類似的模型統稱是叫深度前饋網絡(Deep Feedforward Network),其目標是擬合某個函數f,由于從輸入到輸出的過程中不存在與模型自身的反饋連接,因此被稱為“前饋”。常見的深度前饋網絡有:多層感知機、自編碼器、限制玻爾茲曼機、卷積神經網絡等等。
01 多層感知機(MLP)介紹
說起多層感知器(Multi-Later Perceptron),不得不先介紹下單層感知器(Single Layer Perceptron),它是最簡單的神經網絡,包含了輸入層和輸出層,沒有所謂的中間層(隱含層),可看下圖:
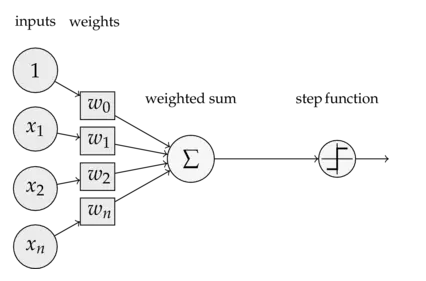
也就是說,將輸入向量賦予不同的權重向量,整合后加起來,并通過激活函數輸出1或-1,一般單層感知機只能解決線性可分的問題,如下圖:
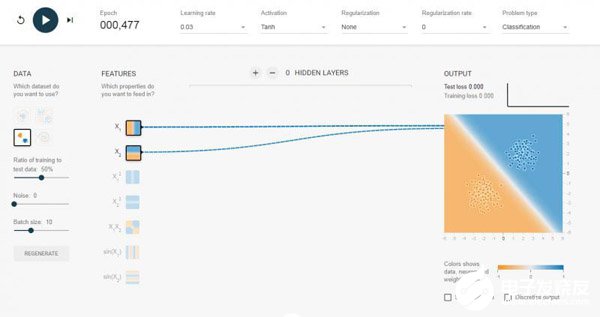
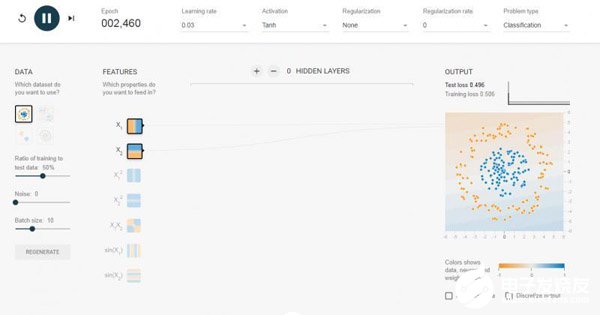
我選擇了0個隱含層,也就是我們介紹的單層感知機,對于可以線性可分的數據,效果還是可以的。如果我換成線性不可分的數據集,如下圖,那么跑半天都跑不出個什么結果來。
這個時候就引入多層感知器,它相比單層感知器多了一個隱含層的東西,同樣的數據集,我加入兩層 隱含層,瞬間就可以被分類得很好。
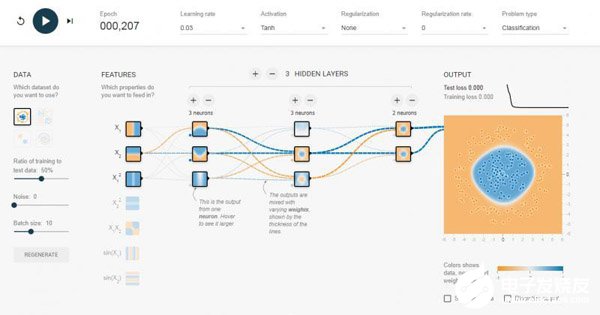
對于上面直觀的了解,我這里還是要深入介紹一下多層感知機的原理。Multi-Layer Perceptron(我們后面都叫MLP),MLP并沒有規定隱含層的數量,因此我們可以根據自己的需求選擇合適的層數,也對輸出層神經元沒有個數限制。
02 深度神經網絡的激活函數
感知機算法中包含了前向傳播(FP)和反向傳播(BP)算法,但在介紹它們之前,我們先來了解一下深度神經網絡的激活函數。
為了解決非線性的分類或回歸問題,我們的激活函數必須是非線性的函數,另外我們使用基于梯度的方式來訓練模型,因此激活函數也必須是連續可導的。 @ 磐創 AI
常用的激活函數主要是:
Sigmoid激活函數
Sigmoid函數就是Logistic函數,其數學表達式為:
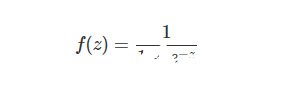
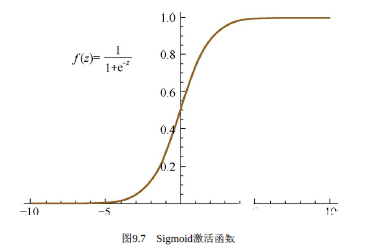
對應函數圖像為:
對應的導函數為:
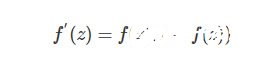
可以看出,Sigmoid激活函數在定義域上是單調遞增的,越靠近兩端變化越平緩,而這會導致我們在使用BP算法的時候出現梯度消失的問題。
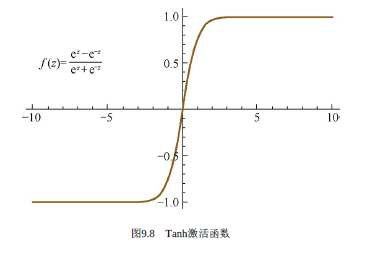
Tanh激活函數
Tanh激活函數中文名叫雙曲正切激活函數,其數學表達式為:
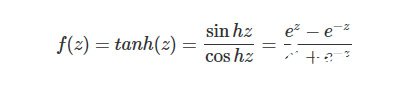
對應函數圖像為:
對應的導函數為:
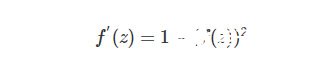
同樣的,tanh激活函數和sigmoid激活函數一樣存在梯度消失的問題,但是tanh激活函數整體效果會優于Sigmoid激活函數。
Q:為什么Sigmoid和Tanh激活函數會出現梯度消失的現象?
A:兩者在z很大(正無窮)或者很小(負無窮)的時候,其導函數都會趨近于0,造成梯度消失的現象。
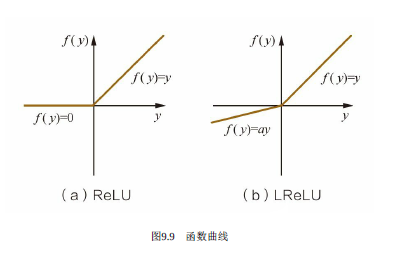
ReLU激活函數
ReLU激活函數又稱為修正線性單元或整流性單元函數,是目前使用比較多的激活函數,其數學表達式為:
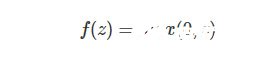
對應函數圖像為(a):
對應的導函數為:
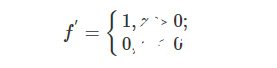
ReLU激活函數的收斂速度要比上面兩種要快得多,ReLU激活函數的X軸左側值恒為0,使得網絡具有一定的稀疏性,從而減少參數之間的依存關系,緩解了過擬合的情況,而且它的導函數有部分為常數1,因此不存在梯度消失的問題。但ReLU激活函數也有弊端,那就是會丟失一些特征信息。
LReLU激活函數
上面可以看到LReLU激活函數的圖像了,它和ReLU激活函數的區別在于當z<0時,其值不為0,而是一個斜率為a的線性函數(一般a會是一個十分小的正數),這樣子即起到了單側抑制,也不完全丟失負梯度信息,其導函數表達式為:
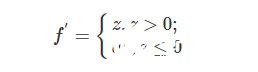
03 深度神經網絡的損失函數
損失函數(Loss Function)又被稱為Cost Function,作用是用來表示預測值與真實值之間的誤差,深度學習模型的訓練是基于梯度的方法最小化Loss Function的過程,下面就介紹幾種常見的損失函數。
均方誤差損失函數
均方誤差(Mean Squared Error,MSE)是比較常用的損失函數,其數學表達式如下:
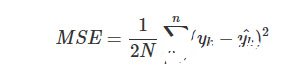
交叉熵損失函數
交叉熵(Crocs Entropy)損失函數使用訓練數據的預測值與真實值之間的交叉熵來作為損失函數,其數學表達式如下:
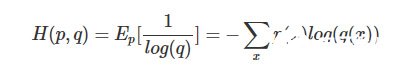
適用場景
一般來說,MSE更適合輸出值為連續值,并且最后一層不含Sigmoid或Softmax激活函數的神經網絡;而交叉熵則適合二分類或者多分類的場景。
04 多層感知機的反向傳播算法
在MLP中,輸入信號通過各個網絡層的隱節點產生輸出的過程,我們稱之為“前向傳播“,而前向傳播最終是產生一個標量損失函數。而反向傳播算法(Backpropagation)則是將損失函數的信息沿著網絡層向后傳播用以計算梯度,達到優化網絡參數的目的。
05 神經網絡的訓練技巧
神經網絡的訓練,常常會遇到的問題就是過擬合,而解決過擬合問題的方法也有很多,簡單羅列下:Data Augmentation(數據增廣)、Regularization(正則化)、Model Ensemble(模型集成)、Dropout等等。此外,訓練深度學習網絡還有學習率、權重衰減系數、Dropout比例的調參等。還有Batch Normalization,BN(批量歸一化)也可以加速訓練過程的收斂,有效規避復雜參數對網絡訓練效率的影響。
Data Augmentation
Data Augmentation也就是數據增廣的意思,就是在不改變數據類別的情況下,這里主要針對圖像數據來說,主要包括但不限于:
1)角度旋轉
2)隨機裁剪
3)顏色抖動:指的是對顏色的數據增強,包括圖像亮度、飽和度、對比度變化等
4)增加噪聲:主要是高斯噪聲,在圖像中隨機加入
5)水平翻轉
6)豎直翻轉
參數初始化
考慮到全連接的深度神經網絡,同一層中的任意神經元都是同構的,所以擁有相同的輸入和輸出,如果參數全部初始化為同一個值,無論是前向傳播還是反向傳播的取值都會是一樣的,學習的過程將無法打破這種情況。因此,我們需要隨機地初始化神經網絡的參數值,簡單的一般會在
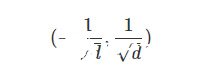
的均勻分布中去隨機抽取,其中d是一個神經元接受的輸入維度。
學習率
學習率我們通常設為0.1,但是如果在實踐中驗證集上的loss或者accuracy不變的時候,可以考慮增加2~5倍的學習率。
Dropout原理
Dropout在深度學習網絡訓練中是十分常用的,指的是以一定的概率p隨機丟棄一部分神經元節點,而這個“丟棄”只是臨時的,是針對每一次小批量的訓練數據而言,由于是隨機丟棄,所以每一次的神經網絡結構都會不一樣,相當于每次迭代都是在訓練不同結構的神經網絡,有點像傳統機器學習中的Bagging方法。
具體實現上,在訓練過程中,神經元的節點激活值以一定的概率p被“丟棄”,也就是“停工”。因此,對于包含N個神經元節點的網絡,在Dropout的作用下可以看做是生成 2的N次方個模型的集合,這個過程會減弱全體神經元之間的聯合適應性,減少過擬合的風險,增強泛化能力。
Batch Normalization原理
因為神經網絡的訓練過程本質就是對數據分布的學習,因此訓練前對輸入數據進行歸一化處理顯得很重要。我們知道,神經網絡有很多層,每經過一個隱含層,訓練數據的分布會因為參數的變化而發生改變,導致網絡在每次迭代中都需要擬合不同的數據分布,這樣子會增加訓練的復雜度以及過擬合的風險。
因此我們需要對數據進行歸一化處理(均值為0,標準差為1),把數據分布強制統一再一個數據分布下,而且這一步不是一開始做的,而是在每次進行下一層之前都需要做的。也就是說,在網路的每一層輸入之前增加一個當前數據歸一化處理,然后再輸入到下一層網路中去訓練。
Regularizations(正則化)
這個我們見多了,一般就是L1、L2比較常見,也是用來防止過擬合的。
L1正則化會使得權重向量w在優化期間變得稀疏(例如非常接近零向量)。 帶有L1正則化項結尾的神經網絡僅僅使用它的最重要的并且接近常量的噪聲的輸入的一個稀疏的子集。相比之下,最終的權重向量從L2正則化通常是分散的、小數字。在實踐中,如果你不關心明確的特征選擇,可以預計L2正則化在L1的性能優越。
L2正則化也許是最常用的正則化的形式。它可以通過將模型中所有的參數的平方級作為懲罰項加入到目標函數(objective)中來實現,L2正則化對尖峰向量的懲罰很強,并且傾向于分散權重的向量。
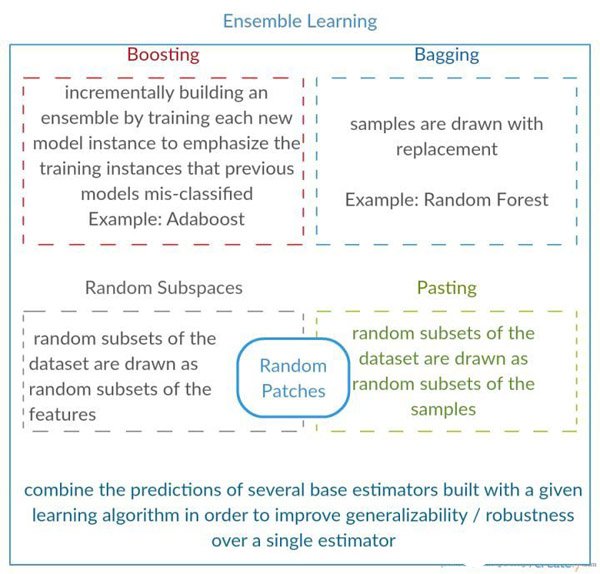
Model Ensemble(模型集成)
模型集成在現實中很常用,通俗來說就是針對一個目標,訓練多個模型,并將各個模型的預測結果進行加權,輸出最后結果。主要有3種方式:
1)相同模型,不同的初始化參數;
2)集成幾個在驗證集上表現效果較好的模型;
3)直接采用相關的Boosting和Bagging算法。
06 深度卷積神經網絡(CNN)
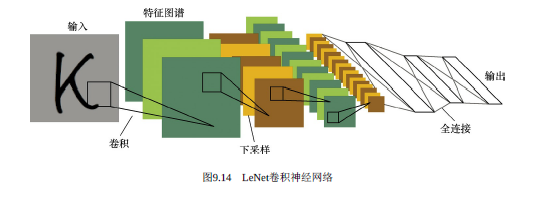
終于來到了我們耳熟能詳的CNN了,也就是卷積神經網絡(Convolutional Neural Network,CNN),它也是屬于前饋神經網絡的一種,其特點是每層的神經元節點只響應前一層局部區域范圍內的神經元(全連接網絡中每個神經元節點則是響應前一層的全部節點)。
一個深度卷積神經網絡模型,一般由若干卷積層疊加若干全連接層組成,中間包含各種的非線性操作、池化操作。卷積運算主要用于處理網格結構的數據,因此CNN天生對圖像數據的分析與處理有著優勢,簡單地來理解,那就是CNN是利用濾波器(Filter)將相鄰像素之間的輪廓過濾出來。
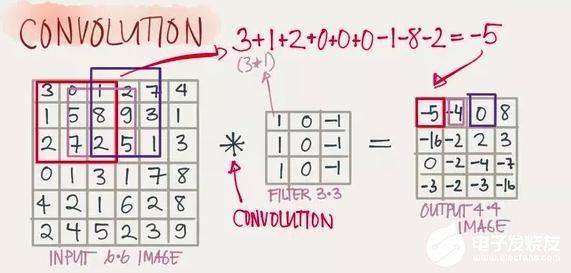
Convolution(卷積)
卷積的濾波器(Filter)我們可以看做是一個window,可以觀察下面的案例,有一個6X6的網絡以及一個3X3的Filter,其中Filter的每個格子上有權值。拿著FIlter在網絡上去移動,直到所有的小格子都被覆蓋到,每次移動,都將Filter“觀察”到的內容,與之權值相乘作為結果輸出。最后,我們可以得到一個4X4的網格矩陣。(下面的6張圖來自參考文獻5,侵刪)
Padding(填充)
卷積后的矩陣大小與一開始的不一致,那么我們需要對邊緣進行填充,以保證尺寸一致。
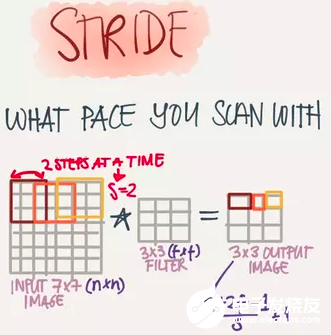
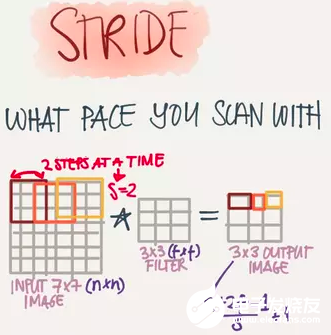
Stride(步長)
也就是Filter移動的步伐大小,上面的例子為1,其實可以由我們自己來指定,有點像是學習率。
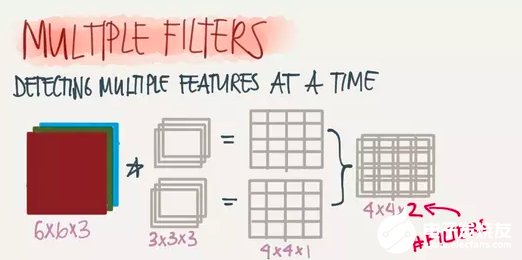
Depth(深度)
深度指的是圖片的深度,一張6X6X3大小的圖片經過3X3X3的Filter過濾后會得到一個4X4X1大小的圖片,因此深度為1。我們也可以通過增加Filter的個數來增加深度,如下:
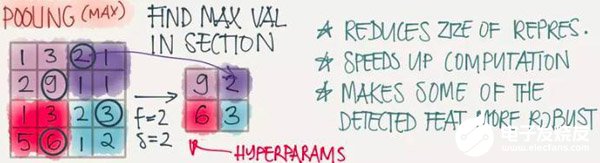
Pooling(池化)
因為濾波器在進行窗口移動的過程中會有很多冗余計算,效率很慢,池化操作的目的在于加速卷積操作,最常用的有Maxpooling,其原理如下圖所示:
完整的深度CNN網絡
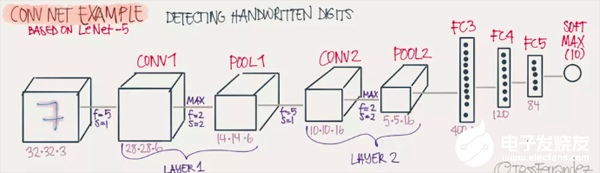
卷積操作的本質
1)Sparse Interaction(稀疏交互)
因為卷積核的尺度會小于輸入的維度,也就是我們的FIlter會小于網絡大小一樣,這樣子每個輸出神經元僅僅會與部分特定局部區域內的神經元存在連接權重(也就是產生交互),這種操作特性我們就叫稀疏交互。稀疏交互會把時間復雜度減少好幾個數量級,同時對過擬合的情況也有一定的改善。
2)Parameter Sharing(參數共享)
指的是在同一個模型的不同模塊使用相同的參數,它是卷積運算的固有屬性。和我們上面說的Filter上的權值大小應用于所有網格一樣。
















 工商網監
工商網監
評論