 電子發(fā)燒友App
電子發(fā)燒友App


本文為大家介紹了在日常的電子交易中對用戶的交易信息進行聚類分析和建模,提供了用戶分析的思路和建議。
我們正生活在數(shù)字技術時代。還記得你上次去到?jīng)]有PayTM或BHIM UPI的商店是什么時候嗎?很顯然,這些數(shù)字交易技術已迅速成為我們日常生活的關鍵部分。
數(shù)字技術不僅是個人,也是各大金融機構的核心。依托著可靠的后臺運行系統(tǒng),執(zhí)行多種選項的支付交易或資金轉帳(例如,網(wǎng)上銀行,ATM,信用卡或借記卡,UPI,POS機等)是一件非常順利的事。
對于我們進行的每筆交易,都會針對它生成一個適當?shù)拿枋鱿ⅲ缦滤荆?/p>
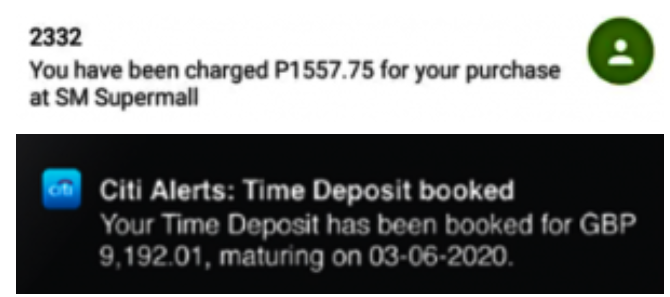
在本文中,我們將討論一個金融機構的實際使用案例,該案例使用-聚類clustering(一種流行的機器學習算法)來為其客戶群定制其產(chǎn)品。
本案例研究的動機
作為一家金融機構,始終根據(jù)客戶的興趣為他們量身定制報價,并以此來吸引現(xiàn)有客戶群是很重要的事。對于任何金融機構而言,把握全方位的客戶信息是一項重大挑戰(zhàn)。
Twitter,WhatsApp,F(xiàn)acebook等社交媒體平臺已成為描述客戶興趣和偏好的主要信息來源。金融機構使用第三方來源的數(shù)據(jù)通常會付出巨大的成本。即使如此,將社交媒體帳戶映射到每一個客戶也非常困難。
那么我們該如何解決呢?
“A partial solution to the above problem can be addressed by using in-house transaction data available with the institution”
“上述問題的部分解決方案可以通過使用該機構提供的內部交易數(shù)據(jù)來解決”
我們可以根據(jù)交易描述消息將客戶執(zhí)行的交易分為不同的類別。此方法可用于標記是否進行了食品,運動,衣服,賬單支付,家庭,其他等類別的交易。如果客戶的大部分交易都出現(xiàn)在特定類別中,那么我們可以對他/她的交易偏好有更好的預估。
這是我們采取的方法
來了解我們如何處理此問題,并為之找出解決方案時而采取的關鍵步驟吧。
確定主題數(shù)量
我們從所有交易開始,將其描述消息映射到每個客戶。首先,我們有一項重要的任務,即確定集群(clusters)(或)類別(catergories)(或)主題(topics)的數(shù)量。為了實現(xiàn)這個目標,我們使用主題建模( Topic Modelling)。
Topic Modelling
https://www.analyticsvidhya.com/blog/2018/10/stepwise-guide-topic-modeling-latent-semantic-analysis/
主題建模是一種對文檔進行無監(jiān)督分類的方法,即便我們不確定要查找的內容,它也可以找到適合的項目組。它主要使用狄利克雷分布(LDA)來擬合主題模型。
它將每個文檔(即交易)視為主題的混合,而將每個主題視為文字的混合。舉個例子:預算一詞可能出現(xiàn)在電影主題和政治主題中。該LDA的基本假設是,樣本中的每個觀察值來自可以被生成統(tǒng)計模型解釋的任意未知分布中。
主題建模可以解決我們的問題。這里有一種生成統(tǒng)計模型,該統(tǒng)計模型已經(jīng)生成了交易描述中的所有文字,這些文字來自未知的任意分布(即未知的組或主題)。我們嘗試估計/建立一個統(tǒng)計模型,以便預測一個單詞屬于特定主題的概率。

主題連貫
我們已經(jīng)通過手動查看各個主題中的熱門關鍵字來確定主題總數(shù),這可能有點主題不一致,而且我們還需要一種主觀的方法來評估正確的主題數(shù)量。那么,我們使用主題連貫性( Topic Coherence)來確定正確的主題數(shù)。
Topic Coherence
https://rare-technologies.com/what-is-topic-coherence/
主題連貫性應用于該主題的前N個單詞。它被定義為主題中單詞的成對相似度得分的平均值/中位數(shù)。好的模型會產(chǎn)生連貫的主題,即主題連貫得分高的主題。
好的主題是可以用短標簽描述的。因此,這就是主題一致性方法所捕獲的內容:

是時候聚類了!
我們已經(jīng)確定了主題/群集的總數(shù)(在我們的案例中為7個主題)。我們應該開始將每個交易描述消息分配給主題。在將文檔分配給主題時,僅依靠主題建模可能無法產(chǎn)生準確的結果。
在這里,我們使用主題建模的輸出以及其他一些功能,使用 K-Means clustering對交易描述消息進行聚類,我們將主要為K-Means集群構建功能集。
K-Means clustering
https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-k-means-clustering/
特征:
基本特征
- 字數(shù),位數(shù),特殊符號數(shù)
- 最長數(shù)字序列長度,數(shù)字-字符比
- 平均,最長字長等
- 交易的周,日和月,當前日期,周末交易等
- 每月最后5天或每月前5天執(zhí)行的交易
- 公眾假期和節(jié)日交易等
查找功能–使用行業(yè)中的頂級品牌和常用名詞作為查找名稱。計算與特定行業(yè)相關的交易描述中的單詞數(shù)。
- 食品:蔬菜,多米諾骨牌Dominos(披薩品牌),F(xiàn)reshDirect(美國的在線食品雜貨商),賽百味等
- 體育:棒球,阿迪達斯,足球,防滑釘?shù)?/p>
- 衛(wèi)生:藥房,醫(yī)院,體育館等
- Bill&EMI:政策,能源,聲明,時間表,取款,電話等。
- 娛樂:Netflix,Prime節(jié)目,Spotify,Soundcloud,酒吧
- 電子商務:亞馬遜,沃爾瑪,eBay,Ticketmaster等
其他:Uber,Airbus,打包機等
主題建模功能
對使用TF-IDF方法生成的DTM矩陣的一元模型和二元模型執(zhí)行主題建模。對于每個主題的交易描述的unigram一元模型和bigram 二元模型DTM矩陣,我們使其獲得2組7種的不同概率。
最后的想法
每個交易描述大約有30個功能,我們執(zhí)行K-Means聚類將每個交易描述分配給7個集群之一。
結果表明,聚類中心附近的觀測結果大多標有正確的主題。少量錯誤的主題標簽被分配在距離聚類中心較遠的觀察點。在手動查看的350個交易描述中,大約240個(準確率為69%)交易描述已正確標記了適當?shù)闹黝}。
現(xiàn)在,我們至少可以對內部客戶的偏好和興趣進行基本估算。我們可以通過發(fā)送定制的要約和選項使內部客戶參與并改善業(yè)務。
盡管使用主題建模的方法相對新穎,實際上,大多數(shù)的信用卡的發(fā)行商都會使用對客戶交易的興趣進行分類。例如,美國運通公司一直在使用這種方法為其客戶創(chuàng)建興趣圖。這樣的興趣圖不僅將交易分為食物,旅行等主要類別,而且還創(chuàng)建了諸如泰國美食迷,野生動物愛好者等的細分。所有這些分類都僅僅基于交易數(shù)據(jù)的豐富性!
關于作者
Ravindra Reddy Tamma –數(shù)據(jù)科學家(Actify數(shù)據(jù)實驗室)
Ravindra是Actify Data Labs的機器學習專家。他的專長包括信用風險分析,應用程序欺詐建模,OCR,文本挖掘以及將模型部署為API。他與貸方廣泛合作,以開發(fā)應用程序,行為和收款記分卡。
Ravindra還使用非結構化征信機構標頭信息為印度的無抵押貸款開發(fā)了國家級應用程序欺詐模型。除信用風險外,Ravindra在OCR,圖像分析和文本挖掘方面擁有深厚的專業(yè)知識。
編輯:hfy

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論