 電子發(fā)燒友App
電子發(fā)燒友App


人類學習本質(zhì)上是多模態(tài) (multi-modal) 的,因為聯(lián)合利用多種感官有助于我們更好地理解和分析新信息。理所當然地,多模態(tài)學習的最新進展即是從這一人類學習過程的有效性中汲取靈感,創(chuàng)建可以利用圖像、視頻、文本、音頻、肢體語言、面部表情和生理信號等各種模態(tài)信息來處理和鏈接信息的模型。
自 2021 年以來,我們看到大家對結(jié)合視覺和語言模態(tài)的模型 (也稱為聯(lián)合視覺語言模型) 的興趣越來越濃,一個例子就是 OpenAI 的 CLIP。聯(lián)合視覺語言模型在非常具有挑戰(zhàn)性的任務中表現(xiàn)出了讓人眼前一亮的能力,諸如圖像標題生成、文本引導圖像生成、文本引導圖像操作以及視覺問答等。這個領(lǐng)域在不斷發(fā)展,其零樣本泛化能力也在不斷改進,從而產(chǎn)生了各種實際應用。
本文,我們將介紹聯(lián)合視覺語言模型,重點關(guān)注它們的訓練方式。我們還將展示如何利用 Transformers 對該領(lǐng)域的最新進展進行實驗。
簡介
將模型稱為 “視覺語言” 模型是什么意思?一個結(jié)合了視覺和語言模態(tài)的模型?但這到底是什么意思呢?
有助于定義此類模型的一個特性是它們處理圖像 (視覺) 和自然語言文本 (語言) 的能力。而這個過程體現(xiàn)在輸入、輸出以及要求這些模型執(zhí)行的任務上。
以零樣本圖像分類任務為例。我們將傳給模型如下一張圖像和一些候選提示 (prompt),以獲得與輸入圖像最匹配的提示。
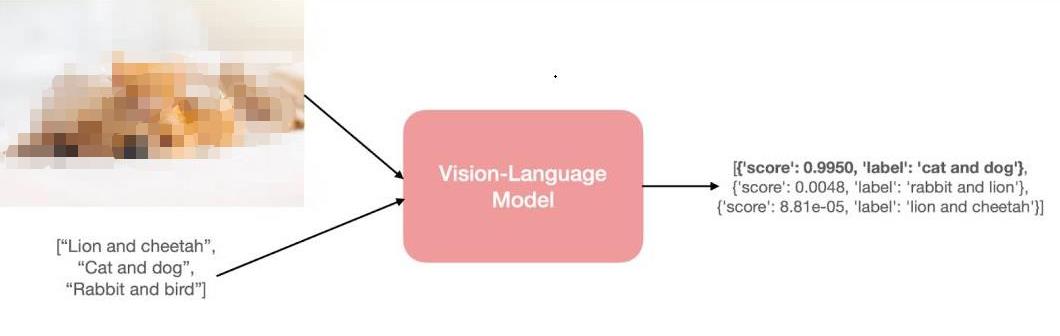
小動物圖片出自:
https://www.istockphoto.com/photos/dog-cat-love
為了預測類似的東西,模型需要理解輸入圖像和文本提示。它將使用單獨或融合的視覺和語言編碼器來達到理解的目的。
輸入和輸出可以有多種形式。下面僅舉幾例:
用自然語言文本來檢索圖像。
短語關(guān)聯(lián) (Phrase grounding),即在輸入圖像中檢測出文本中提到的短語 (例如: 一個 年輕人 揮動 球拍)。
視覺問答,即在輸入圖像中找到自然語言問題的答案。
為給定圖像生成標題。該任務還有一個形式就是條件文本生成,此時輸入變成了兩個,即自然語言提示和圖像。
從包含圖像和文本模態(tài)的社交媒體內(nèi)容中檢測仇恨言論。
學習策略
視覺語言模型通常由 3 個關(guān)鍵元素組成: 圖像編碼器、文本編碼器以及融合兩個編碼器的信息的策略。這些關(guān)鍵元素緊密耦合在一起,因為損失函數(shù)是圍繞模型架構(gòu)和學習策略設(shè)計的。雖然視覺語言模型研究算不上是一個新的研究領(lǐng)域,但此類模型的設(shè)計隨著時間的變遷發(fā)生了巨大變化。早期的研究采用手工設(shè)計的圖像描述子、預訓練詞向量或基于頻率的 TF-IDF 特征,而最新的研究主要采用 Transformer 架構(gòu)的圖像和文本編碼器來單獨或聯(lián)合學習圖像和文本特征。我們使用戰(zhàn)略性的預訓練目標來訓練這些模型,從而使之可用于各種下游任務。
關(guān)于 Transformers 注意力理論的論文:
https://arxiv.org/abs/1706.03762
在本節(jié)中,我們將討論視覺語言模型的一些典型預訓練目標和策略,這些模型已被證明有良好的遷移性能。我們還將討論其他有趣的東西,它們要么特定于某些預訓練目標,要么可以用作預訓練的通用組件。
我們將在預訓練目標中涵蓋以下主題:
對比學習: 以對比方式將圖像和文本對齊到聯(lián)合特征空間
PrefixLM: 通過將圖像視作語言模型的前綴來聯(lián)合學習圖像和文本嵌入
基于交叉注意力的多模態(tài)融合:?將視覺信息融合到具有交叉注意力機制的語言模型的各層中
MLM / ITM: 使用掩碼語言建模 (Masked-Language Modeling,MLM) 和圖像文本匹配 (Image-Text Matching,ITM) 目標將圖像的各部分與文本對齊
無訓練:?通過迭代優(yōu)化來利用獨立視覺和語言模型
請注意,本節(jié)并未詳盡陳述所有方法,還有各種其他方法以及混合策略,例如 Unified-IO。如需更全面地了解多模態(tài)模型,請參閱此項工作:
Unified-IO 論文地址:
https://arxiv.org/abs/2206.08916 多模態(tài)模型參考論文地址:
https://arxiv.org/abs/2210.09263
1) 對比學習

對比預訓練和零樣本圖像分類
上圖出處:
https://openai.com/blog/clip
對比學習是視覺模型常用的預訓練目標,也已被證明同時是視覺語言模型的高效預訓練目標。近期的工作如 CLIP、CLOOB、ALIGN 和 DeCLIP 在 {圖像,標題} 對組成的大型數(shù)據(jù)集上,通過使用對比損失函數(shù)聯(lián)合訓練文本編碼器和圖像編碼器,從而橋接視覺和語言兩個模態(tài)。對比學習旨在將輸入圖像和文本映射到相同的特征空間,使得圖像 - 文本對的嵌入之間的距離在兩者匹配時最小化,而在不匹配時最大化。
CLIP 論文地址:
https://arxiv.org/abs/2103.00020 CLOOB 論文地址:
https://arxiv.org/abs/2110.11316 ALIGN 論文地址:
https://arxiv.org/abs/2102.05918 DeCLIP 論文地址:
https://arxiv.org/abs/2110.05208
CLIP 僅采用文本和圖像嵌入之間的余弦距離作為距離度量。而 ALIGN 和 DeCLIP 等模型則設(shè)計了自己的距離度量,這些距離在設(shè)計時考慮了數(shù)據(jù)集是有噪聲的。
另一項工作 LiT 引入了一種凍結(jié)圖像編碼器而僅使用 CLIP 預訓練目標來微調(diào)文本編碼器的簡單方法。作者將這個想法解釋為 一種教文本編碼器更好地讀懂圖像編碼器生成的圖像嵌入的方法。這種方法已被證明是有效的,并且比 CLIP 的樣本效率更高。FLAVA 等其他工作將對比學習和其他預訓練策略相結(jié)合來對齊視覺和語言嵌入。
LiT 論文地址:
https://arxiv.org/abs/2111.07991 FLAVA 論文地址:
https://arxiv.org/abs/2112.04482
2) PrefixLM

PrefixLM 預訓練策略框圖
上圖出處:
https://ai.googleblog.com/2021/10/simvlm-simple-visual-language-model-pre.html
另一種訓練視覺語言模型的方法是使用 PrefixLM 目標。SimVLM 和 VirTex 等模型使用該預訓練目標并使用一個統(tǒng)一的由 transformer 編碼器和 transformer 解碼器組成的多模態(tài)架構(gòu),有點類似于自回歸語言模型。
SimVLM 論文地址:
https://arxiv.org/abs/2108.10904 VirTex 論文地址:
https://arxiv.org/abs/2006.06666v3
讓我們拆解一下,看看它是如何工作的。具有前綴目標的語言模型在給定輸入文本作為前綴的情況下預測下一個詞。例如,給定序列 “一個男人站在墻角”,我們可以使用” 一個男人站在” 作為前綴并訓練模型以預測下一個詞: 可以是 “墻角” 或另一個合理的補全詞。
Visual transformers (ViT) 通過將每個圖像劃分為多個塊 (patch) 并將這些塊按順序輸入給模型,從而將相同的前綴概念應用于圖像。利用這個想法,SimVLM 實現(xiàn)了這樣一種架構(gòu),將圖像塊序列和前綴文本序列串接起來作為最終的前綴,輸入給編碼器,然后由解碼器來預測該文本序列的接續(xù)文本。上圖描述了該思想。SimVLM 模型首先在前綴中沒有圖像塊的文本數(shù)據(jù)集上進行預訓練,然后在對齊的圖像文本數(shù)據(jù)集上進行預訓練。這些模型用于圖生文 / 圖像標題生成和 VQA 任務。
利用統(tǒng)一的多模態(tài)架構(gòu)將視覺信息融合到語言模型 (Language Model,LM) 中,最終生成的模型在圖像引導類任務中顯示出令人印象深刻的能力。然而,僅使用 PrefixLM 策略的模型在應用領(lǐng)域上可能會受到限制,因為它們主要為圖像標題生成或視覺問答這兩個下游任務而設(shè)計。例如,給定一組包含人的圖像,我們通過圖像的描述來查詢符合描述的圖像 (例如,“一群人站在一起微笑著站在建筑物前”) 或使用以下視覺推理問題來查詢: “有多少人穿著紅色 T 恤?” 圖像。另一方面,學習多模態(tài)表示或采用混合方法的模型可以適用于各種其他下游任務,例如目標檢測和圖像分割。
凍結(jié) PrefixLM

凍結(jié) PrefixLM 預訓練策略
上圖出處:
https://lilianweng.github.io/posts/2022-06-09-vlm
雖然將視覺信息融合到語言模型中非常有效,但能夠使用預訓練語言模型 (LM) 而無需微調(diào)會更有效。因此,視覺語言模型的另一個預訓練目標是學習與凍結(jié)語言模型對齊的圖像嵌入。
Frozen、MAPL 和 ClipCap 使用了凍結(jié) PrefixLM 預訓練目標。它們在訓練時僅更新圖像編碼器的參數(shù)以生成圖像嵌入,這些圖像嵌入可以用作預訓練的凍結(jié)語言模型的前綴,其方式與上面討論的 PrefixLM 目標類似。Frozen 和 ClipCap 都在對齊的圖像文本 (標題) 數(shù)據(jù)集上進行訓練,目的是在給定圖像嵌入和前綴文本的情況下生成標題中的下一個詞。
Frozen 論文地址:
https://arxiv.org/abs/2106.13884 MAPL 論文地址:
https://arxiv.org/abs/2210.07179 ClipCap 論文地址:
https://arxiv.org/abs/2111.09734
最后,F(xiàn)lamingo 索性把預訓練視覺編碼器和語言模型都凍結(jié)了,并在一系列廣泛的開放式視覺和語言任務上刷新了少樣本學習的最高水平。Flamingo 通過在預訓練的凍結(jié)視覺模型之上添加一個感知器重采樣器 (Perceiver Resampler) ?模塊并在凍結(jié)的預訓練 LM 層之間插入新的交叉注意層以根據(jù)視覺數(shù)據(jù)調(diào)節(jié) LM 來達到這個性能。
Flamingo 論文地址:
https://arxiv.org/abs/2204.14198
凍結(jié) PrefixLM 預訓練目標的一個很好的優(yōu)勢是它可以使用有限的對齊圖像文本數(shù)據(jù)進行訓練,這對于那些沒有對齊多模態(tài)數(shù)據(jù)集的領(lǐng)域特別有用。
3) 多模態(tài)融合與交叉注意力

使用交叉注意力機制將視覺信息直接融合到語言模型中
上圖出處:
https://www.semanticscholar.org/paper/VisualGPT%3A-Data-efficient-Adaptation-of-Pretrained-Chen-Guo/616e0ed02ca024a8c1d4b86167f7486ea92a13d9
將預訓練語言模型用于多模態(tài)任務的另一種方法是使用交叉注意機制將視覺信息直接融合到語言模型解碼器的層中,而不是使用圖像作為語言模型的附加前綴。VisualGPT、VC-GPT 和 Flamingo 使用此預訓練策略并在圖像標題任務和視覺問答任務上進行訓練。此類模型的主要目標是在把視覺信息融入文本生成能力時在這兩者間取得高效的平衡,這在沒有大型多模態(tài)數(shù)據(jù)集的情況下非常重要。
VisualGPT 論文地址:
https://arxiv.org/abs/2102.10407 VC-GPT 論文地址:
https://arxiv.org/abs/2201.12723
VisualGPT 等模型使用視覺編碼器來生成圖像嵌入,并將視覺嵌入提供給預訓練語言解碼器模塊的交叉注意層,以生成合理的標題。最近的一項工作 FIBER 將具有門控機制的交叉注意力層插入到視覺和語言的主干模型中,以實現(xiàn)更高效的多模態(tài)融合,并使能各種其他下游任務,如圖文互搜、開放域 (open-vocabulary) 目標檢測等。
FIBER 論文地址:
http://arxiv.org/abs/2206.07643
4) 掩膜語言建模及圖文匹配
另一派視覺語言模型把掩碼語言建模 (MLM) 和圖文匹配 (ITM) 目標組合起來使用,將圖像的特定部分與文本對齊,并使能各種下游任務,例如視覺問答、視覺常識推理、文搜圖以及文本引導的目標檢測。遵循這種預訓練設(shè)置的模型包括 VisualBERT、FLAVA、ViLBERT、LXMERT 和 BridgeTower。
VisualBERT 論文地址:
https://arxiv.org/abs/1908.03557 FLAVA 論文地址:
https://arxiv.org/abs/2112.04482 ViLBERT 論文地址:
https://arxiv.org/abs/1908.02265 LXMERT 論文地址:
https://arxiv.org/abs/1908.07490 BridgeTower 論文地址:
https://arxiv.org/abs/2206.08657
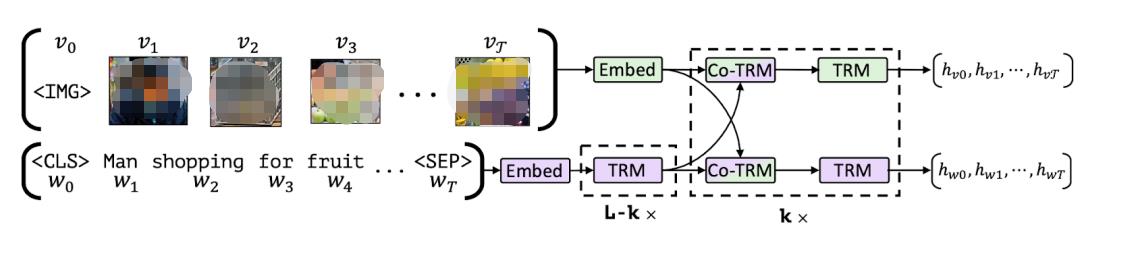
將圖像與文本按部分相應對齊
上圖出處:
https://arxiv.org/abs/1908.02265
讓我們解釋一下 MLM 和 ITM 目標。給定一個部分遮蓋的標題,MLM 的目標是根據(jù)相應的圖像預測遮蓋的單詞。請注意,MLM 目標需要使用帶有邊界框的標注豐富的多模態(tài)數(shù)據(jù)集,或者使用目標檢測模型為部分輸入文本生成候選目標區(qū)域。
對于 ITM 目標,給定圖像和標題對,任務是預測標題是否與圖像匹配。負樣本通常是從數(shù)據(jù)集中隨機抽取的。MLM 和 ITM 目標通常在多模態(tài)模型的預訓練期間結(jié)合使用。例如,VisualBERT 提出了一種類似 BERT 的架構(gòu),它使用預訓練的目標檢測模型 Faster-RCNN 來檢測目標。VisualBERT 在預訓練期間結(jié)合了 MLM 和 ITM 目標,通過自注意力機制隱式對齊輸入文本的元素和相應輸入圖像中的區(qū)域。
Faster-RCNN 論文地址:
https://arxiv.org/abs/1506.01497
另一項工作 FLAVA 由一個圖像編碼器、一個文本編碼器和一個多模態(tài)編碼器組成,用于融合和對齊圖像和文本表示以進行多模態(tài)推理,所有這些都基于 transformers。為了實現(xiàn)這一點,F(xiàn)LAVA 使用了多種預訓練目標: MLM、ITM,以及 掩膜圖像建模 (Masked-Image Modeling,MIM) 和對比學習。
5) 無訓練
最后,各種優(yōu)化策略旨在使用預訓練的圖像和文本模型來橋接圖像和文本表示,或者使預訓練的多模態(tài)模型能夠在無需額外訓練的情況下適應新的下游任務。
例如,MaGiC 提出通過預訓練的自回歸語言模型進行迭代優(yōu)化,為輸入圖像生成標題。為此,MaGiC 使用生成的詞的 CLIP 嵌入和輸入圖像的 CLIP 嵌入來計算基于 CLIP 的 “魔法分數(shù) (magic score) ”。
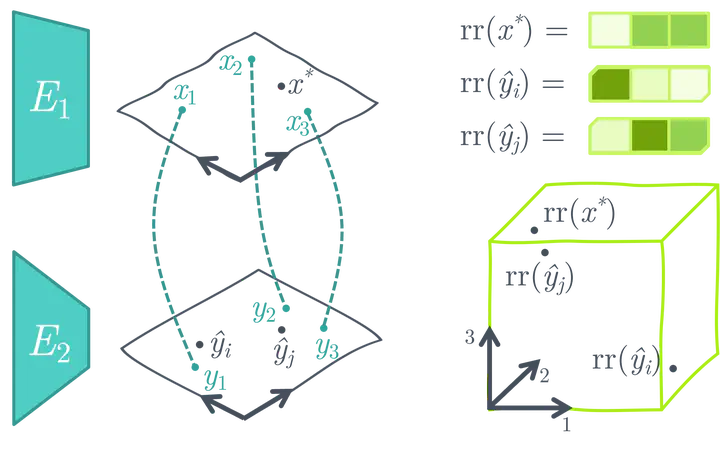
用預訓練的凍結(jié)的單模態(tài)圖像和文本編碼器創(chuàng)建一個相似性搜索空間
ASIF 提出了一種簡單的方法,可以使用相對較小的多模態(tài)數(shù)據(jù)集將預訓練的單模態(tài)圖像和文本模型轉(zhuǎn)換為多模態(tài)模型來用于圖像標題生成,無需附加訓練。ASIF 背后的關(guān)鍵直覺是相似圖像的標題也彼此相似。因此,我們可以通過使用小型數(shù)據(jù)集里的真實多模態(tài)對的來構(gòu)建一個相對表示空間,然后在該空間執(zhí)行基于相似性的搜索。
MaGic 論文地址:
https://arxiv.org/abs/2205.02655 ASIF 論文地址:
https://arxiv.org/abs/2210.01738
數(shù)據(jù)集
視覺語言模型通常根據(jù)預訓練目標在結(jié)構(gòu)各異的大型圖像和文本數(shù)據(jù)集上進行訓練。在對它們進行預訓練后,再使用特定于任務的數(shù)據(jù)集進一步針對各種下游任務進行微調(diào)。本節(jié)概述了一些用于訓練和評估視覺語言模型的流行的預訓練和下游數(shù)據(jù)集。
預訓練數(shù)據(jù)集
一般來講,我們從網(wǎng)上收集大量的多模態(tài)數(shù)據(jù)并將它們組織成圖像 / 視頻 - 文本對數(shù)據(jù)集。這些數(shù)據(jù)集中的文本數(shù)據(jù)可以是人工生成的標題、自動生成的標題、圖像元數(shù)據(jù)或簡單的目標類別標簽。此類大型數(shù)據(jù)集有 PMD 和 LAION-5B 等。PMD 數(shù)據(jù)集結(jié)合了多個較小的數(shù)據(jù)集,例如 Flickr30K、COCO 和 Conceptual Captions 數(shù)據(jù)集。COCO 檢測和圖像標題 (>330K 圖像) 數(shù)據(jù)集分別由圖像實例和其所含目標的文本標簽及描述對組成。Conceptual Captions (> 3.3M images) 和 Flickr30K (> 31K images) 數(shù)據(jù)集中的圖像以及它們的對應的用自然語言描述圖像的標題都是從網(wǎng)上爬取的。
即使是那些人工生成標題的圖像文本數(shù)據(jù)集 (例如 Flickr30K) 也存在固有的噪聲,因為用戶并不總是為其圖像編寫描述性或反應圖像內(nèi)容的標題。為了克服這個問題,LAION-5B 等數(shù)據(jù)集利用 CLIP 或其他預訓練的多模態(tài)模型來過濾噪聲數(shù)據(jù)并創(chuàng)建高質(zhì)量的多模態(tài)數(shù)據(jù)集。此外,一些視覺語言模型,如 ALIGN,提出了進一步的預處理步驟并創(chuàng)建了自己的高質(zhì)量數(shù)據(jù)集。還有些視覺語言數(shù)據(jù)集包含了視頻和文本雙模態(tài),例如 LSVTD 和 WebVid 數(shù)據(jù)集,雖然它們規(guī)模較小。
上文提到的數(shù)據(jù)集鏈接:
PMD:
https://hf.co/datasets/facebook/pmd LAION-5B:
https://laion.ai/blog/laion-5b/ Flickr30K:
https://www.kaggle.com/datasets/hsankesara/flickr-image-dataset COCO:
https://cocodataset.org/ Conceptual Captions:
https://ai.google.com/research/ConceptualCaptions/ LSVTD:
https://davar-lab.github.io/dataset/lsvtd.html WebVid:
https://github.com/m-bain/webvid
下游數(shù)據(jù)集
預訓練視覺語言模型通常還會針對各種下游任務進行訓練,例如視覺問答、文本引導目標檢測、文本引導圖像修復、多模態(tài)分類以及各種獨立的 NLP 和計算機視覺任務。
針對問答類下游任務進行微調(diào)的模型,例如 ViLT 和 GLIP,一般使用 VQA (視覺問答) 、VQA v2、NLVR2、OKVQA、TextVQA、TextCaps 和 VizWiz 數(shù)據(jù)集。這些數(shù)據(jù)集的圖像通常都配有多個開放式問題和答案。此外,VizWiz 和 TextCaps 等數(shù)據(jù)集也可用于圖像分割和目標定位這些下游任務。其他一些有趣的多模態(tài)下游數(shù)據(jù)集有,用于多模態(tài)分類的 Hateful Memes,用于視覺蘊含預測的 SNLI-VE,以及用于視覺語言組合推理的 Winoground。
請注意,視覺語言模型也可用于各種經(jīng)典的 NLP 和計算機視覺任務,例如文本或圖像分類。此時,通常使用單模態(tài)數(shù)據(jù)集如 SST2、ImageNet-1k 來完成此類下游任務。此外,COCO 和 Conceptual Captions 等數(shù)據(jù)集也常用于預訓練模型以及標題生成等下游任務。
相關(guān)模型及論文地址:
ViLT:
https://arxiv.org/abs/2102.03334 GLIP:
https://arxiv.org/abs/2112.03857 VQA:
https://visualqa.org/ VQA v2:
https://visualqa.org/ NLVR2:
https://lil.nlp.cornell.edu/nlvr/ OKVQA:
https://okvqa.allenai.org/ TextVQA:
https://hf.co/datasets/textvqa TextCaps:
https://textvqa.org/textcaps/ VizWiz:
https://vizwiz.org/ Hateful Memes:
https://hf.co/datasets/limjiayi/hateful_memes_expanded SNLI-VE:
https://github.com/necla-ml/SNLI-VE Winoground:
https://hf.co/datasets/facebook/winoground SST2:
https://hf.co/datasets/sst2 ImageNet-1k:
https://hf.co/datasets/imagenet-1k
在 Transformers 中支持視覺語言模型
使用 Hugging Face Transformers,你可以輕松下載、運行和微調(diào)各種預訓練視覺語言模型,或者混合搭配預訓練視覺模型和預訓練語言模型來搭建你自己的模型。 Transformers 支持的一些視覺語言模型有:
CLIP:https://hf.co/docs/transformers/model_doc/clip FLAVA:?
https://hf.co/docs/transformers/main/en/model_doc/flava GIT:?
https://hf.co/docs/transformers/main/en/model_doc/git BridgeTower:https://hf.co/docs/transformers/main/en/model_doc/bridgetower GroupViT:?
https://hf.co/docs/transformers/v4.25.1/en/model_doc/groupvit BLIP:?
https://hf.co/docs/transformers/main/en/model_doc/blip OWL-ViT:?
https://hf.co/docs/transformers/main/en/model_doc/owlvit CLIPSeg:?
https://hf.co/docs/transformers/main/en/model_doc/clipseg X-CLIP:
https://hf.co/docs/transformers/main/en/model_doc/xclip VisualBERT:?
https://hf.co/docs/transformers/main/en/model_doc/visual_bert ViLT:?
https://hf.co/docs/transformers/main/en/model_doc/vilt LiT (VisionTextDualEncoder 的一個實例):?
https://hf.co/docs/transformers/main/en/model_doc/vision-text-dual-encoder TrOCR (VisionEncoderDecoderModel 的一個實例):??
https://hf.co/docs/transformers/main/en/model_doc/trocr VisionTextDualEncoder:?
https://hf.co/docs/transformers/main/en/model_doc/vision-text-dual-encoder VisionEncoderDecoderModel:? ? ?
https://hf.co/docs/transformers/main/en/model_doc/vision-encoder-decoder
這里 CLIP、FLAVA、BridgeTower、BLIP、LiT 和 VisionEncoderDecoder 等模型會生成聯(lián)合圖像 - 文本嵌入,可用之于零樣本圖像分類等下游任務,而其他模型則針對有趣的下游任務進行訓練。此外,F(xiàn)LAVA 是基于單模態(tài)和多模態(tài)兩個預訓練目標訓練的,因此可用于單模態(tài)視覺或語言任務以及多模態(tài)任務。
例如,OWL-ViT 使能 了零樣本 - 文本引導目標檢測和單樣本 - 圖像引導目標檢測任務,CLIPSeg 和 GroupViT 使能 了文本和圖像引導的圖像分割任務,VisualBERT、GIT 和 ViLT 使能 了視覺問答以及其他各種任務。X-CLIP 是一種使用視頻和文本模態(tài)進行訓練的多模態(tài)模型,它能夠 使能 類似于 CLIP 的零樣本圖像分類的視頻分類任務。
幾個相關(guān)的 Hugging Face Spaces 體驗地址:
OWL-ViT:
https://hf.co/spaces/adirik/OWL-ViT CLIPSeg:
https://hf.co/spaces/nielsr/CLIPSeg ViLT:
https://hf.co/spaces/nielsr/vilt-vqa X-CLIP:??
https://hf.co/spaces/fcakyon/zero-shot-video-classification
與其他模型不同,VisionEncoderDecoderModel 是一個標準化的模型,可用于初始化任意圖像轉(zhuǎn)文本模型,這類模型可以使用任何預訓練的基于 Transformer 的視覺模型作為編碼器 (例如 ViT、BEiT、DeiT、Swin) 以及任何預訓練的語言模型作為解碼器 (例如 RoBERTa、GPT2、BERT、DistilBERT)。事實上,TrOCR 是這個標準類的一個實例。
讓我們繼續(xù)試驗其中的一些模型。我們將使用 ViLT 進行視覺問答,使用 CLIPSeg 進行零樣本圖像分割。首先,我們要安裝 Transformers: pip install transformers。
基于 ViLT 的 VQA
讓我們從 ViLT 開始,下載一個在 VQA 數(shù)據(jù)集上預訓練的模型。我們可以簡單地初始化相應的模型類然后調(diào)用 “from_pretrained ()” 方法來下載想要的 checkpoint。
?
?
from?transformers?import?ViltProcessor,?ViltForQuestionAnswering
model?=?ViltForQuestionAnswering.from_pretrained?("dandelin/vilt-b32-finetuned-vqa")
?
?
接下來,我們隨便下載一張有兩只貓的圖像,并對該圖像和我們的查詢問題進行預處理,將它們轉(zhuǎn)換為模型期望的輸入格式。為此,我們可以方便地使用相應的預處理器類 (ViltProcessor) 并使用相應 checkpoint 的預處理配置對其進行初始化。
?
?
import?requests
from?PIL?import?Image
processor?=?ViltProcessor.from_pretrained?("dandelin/vilt-b32-finetuned-vqa")
#?download?an?input?image
url?=?"http://images.cocodataset.org/val2017/000000039769.jpg"
image?=?Image.open?(requests.get?(url,?stream=True).raw)
text?=?"How?many?cats?are?there?"
#?prepare?inputs
inputs?=?processor?(image,?text,?return_tensors="pt")
?
?
最后,我們可以使用預處理后的圖像和問題作為輸入進行推理,并打印出預測答案。但是,要牢記的重要一點是確保你的文本輸入與訓練時所用的問題模板相似。你可以參考 論文和數(shù)據(jù)集 來了解如何生成這些問題。
論文地址:
https://arxiv.org/abs/2102.03334
?
?
import?torch
#?forward?pass
with?torch.no_grad?():
????outputs?=?model?(**inputs)
logits?=?outputs.logits
idx?=?logits.argmax?(-1).item?()
print?("Predicted?answer:",?model.config.id2label?[idx])
?
?
直截了當,對吧?讓我們用 CLIPSeg 做另一個演示,看看我們?nèi)绾斡脦仔写a執(zhí)行零樣本圖像分割。
使用 CLIPSeg 做零樣本圖像分割
我們將從初始化 CLIPSegForImageSegmentation 及其相應的預處理類開始,并加載我們的預訓練模型。
?
?
from?transformers?import?CLIPSegProcessor,?CLIPSegForImageSegmentation
processor?=?CLIPSegProcessor.from_pretrained?("CIDAS/clipseg-rd64-refined")
model?=?CLIPSegForImageSegmentation.from_pretrained?("CIDAS/clipseg-rd64-refined")
?
?
接下來,我們將使用相同的輸入圖像,并用描述待分割目標的文本來查詢模型。與其他預處理器類似,CLIPSegProcessor 將輸入轉(zhuǎn)換為模型期望的格式。由于我們要分割多個目標,我們分別對每個描述文本都使用相同的輸入圖像。
?
?
from?PIL?import?Image import?requests url?=?"http://images.cocodataset.org/val2017/000000039769.jpg" image?=?Image.open?(requests.get?(url,?stream=True).raw) texts?=?["a?cat",?"a?remote",?"a?blanket"] inputs?=?processor?(text=texts,?images=[image]?*?len?(texts),?padding=True,?return_tensors="pt")
?
?
與 ViLT 類似,重要的是要參考 原作,看看他們用什么樣的文本提示來訓練模型,以便在推理時獲得最佳性能。雖然 CLIPSeg 在簡單的對象描述 (例如 “汽車”) 上進行訓練的,但其 CLIP 主干是在設(shè)計好的文本模板 (例如 “汽車圖像”、“汽車照片”) 上預訓練的,并在隨后的訓練中凍結(jié)。輸入經(jīng)過預處理后,我們可以執(zhí)行推理以獲得每個文本查詢的二值分割圖。
上述論文地址:
https://arxiv.org/abs/2112.10003
?
?
import?torch with?torch.no_grad?(): ????outputs?=?model?(**inputs) logits?=?outputs.logits print?(logits.shape) >>>?torch.Size?([3,?352,?352])
?
?
讓我們可視化一下結(jié)果,看看 CLIPSeg 的表現(xiàn)如何 (代碼改編自 這篇文章)
文章鏈接:
https://hf.co/blog/clipseg-zero-shot
?
?
import?matplotlib.pyplot?as?plt logits?=?logits.unsqueeze?(1) _,?ax?=?plt.subplots?(1,?len?(texts)?+?1,?figsize=(3*(len?(texts)?+?1),?12)) [a.axis?('off')?for?a?in?ax.flatten?()] ax?[0].imshow?(image) [ax?[i+1].imshow?(torch.sigmoid?(logits?[i][0]))?for?i?in?range?(len?(texts))]; [ax?[i+1].text?(0,?-15,?prompt)?for?i,?prompt?in?enumerate?(texts)]

?
?
太棒了,不是嗎?
視覺語言模型支持大量有用且有趣的用例,并不僅限于 VQA 和零樣本分割。我們鼓勵你嘗試將本節(jié)中提到的模型用于不同的應用。有關(guān)示例代碼,請參閱模型的相應文檔。
新興研究領(lǐng)域
伴隨著視覺語言模型的巨大進步,我們看到了新的下游任務和應用領(lǐng)域的出現(xiàn),例如醫(yī)學和機器人技術(shù)。例如,視覺語言模型越來越多地被用于醫(yī)療,產(chǎn)生了諸如 Clinical-BERT 之類的工作來根據(jù)放射照片來進行醫(yī)學診斷和報告生成,以及 MedFuseNet 來用于醫(yī)學領(lǐng)域的視覺問答。
我們還看到大量將聯(lián)合視覺語言表示應用于各種領(lǐng)域的工作,如用于圖像處理 (例如,StyleCLIP、StyleMC,DiffusionCLIP)、基于文本的視頻檢索 (例如,X-CLIP) 、基于文本的操作 (例如,Text2Live 以及 基于文本的 3D 形狀和紋理操作 (例如,AvatarCLIP,CLIP-NeRF, Latent3D, CLIPFace, Text2Mesh)。在類似的工作中,MVT 提出了一種聯(lián)合 3D 場景 - 文本表示模型,可用于各種下游任務,例如 3D 場景補全。
雖然機器人研究尚未大規(guī)模利用視覺語言模型,但我們看到 CLIPort 等工作利用聯(lián)合視覺語言表示進行端到端模仿學習,并宣稱比之前的 SOTA 有了很大的改進。我們還看到,大型語言模型越來越多地被用于機器人任務,例如常識推理、導航和任務規(guī)劃。例如,ProgPrompt 提出了一個使用大語言模型 (Large Language Model,LLM) 生成情境機器人任務計劃的框架。同樣,SayCan 使用 LLM 根據(jù)給定的環(huán)境及環(huán)境中物體的視覺描述,選擇最合理的動作。盡管這些進展令人印象深刻,但由于目標檢測數(shù)據(jù)集的限制,機器人研究仍然局限在有限的環(huán)境和目標集中。隨著 OWL-ViT 和 GLIP 等開放集目標檢測模型的出現(xiàn),我們可以期待多模態(tài)模型與機器人導航、推理、操作和任務規(guī)劃框架的集成會更緊密。
新型研究領(lǐng)域的一些重要參考:
Clinical-BERT:
https://ojs.aaai.org/index.php/AAAI/article/view/20204 MedFuseNet:
https://www.nature.com/articles/s41598-021-98390-1 StyleCLIP:
https://arxiv.org/abs/2103.17249 StyleMC:
https://arxiv.org/abs/2112.08493 DiffusionCLIP:
https://arxiv.org/abs/2110.02711 X-CLIP:
https://arxiv.org/abs/2207.07285 Text2Live:
https://arxiv.org/abs/2204.02491 AvatarCLIP:
https://arxiv.org/abs/2205.08535 CLIP-NeRF:
https://arxiv.org/abs/2112.05139 Latent3D:
https://arxiv.org/abs/2202.06079 CLIPFace:
https://arxiv.org/abs/2212.01406 Text2Mesh:
https://arxiv.org/abs/2112.03221 MVT:
https://arxiv.org/abs/2204.02174 CLIPort:
https://arxiv.org/abs/2109.12098 ProgPrompt:
https://arxiv.org/abs/2209.11302 SayCan:
https://say-can.github.io/assets/palm_saycan.pdf OWL-ViT:
https://arxiv.org/abs/2205.06230 GLIP:
https://arxiv.org/abs/2112.03857
結(jié)論
近年來,多模態(tài)模型取得了令人難以置信的進步,視覺語言模型在性能、用例以及應用的多樣性方面取得了顯著的飛躍。在這篇文章中,我們討論了視覺語言模型的最新進展,可用的多模態(tài)數(shù)據(jù)集以及我們可以使用哪些預訓練策略來訓練和微調(diào)此類模型。我們還展示了如何將這些模型集成到 Transformers 中,以及如何使用它們通過幾行代碼來執(zhí)行各種任務。
編輯:黃飛
?















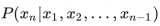











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論