 電子發(fā)燒友App
電子發(fā)燒友App


-01-
AI編解碼的意義與挑戰(zhàn)

以上是高通總結(jié)的關(guān)于AI編解碼優(yōu)勢(shì)的一張示意圖。其中相當(dāng)多的優(yōu)勢(shì)來(lái)自于端到端優(yōu)化這一特性,它的壓縮率比較好,可以對(duì)任意分布的數(shù)據(jù)做專門優(yōu)化,可以針對(duì)任意更符合主觀質(zhì)量的、更符合下游任務(wù)的損失函數(shù)進(jìn)行優(yōu)化。
另一方面,由于它是用神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)的,那便可以在人工智能的大潮中進(jìn)行復(fù)用,例如復(fù)用各種推理硬件和算法。還有一個(gè)好處是權(quán)重比較容易更新,傳統(tǒng)編解碼算法在做成硬件后很難進(jìn)行修改,但對(duì)于基于神經(jīng)網(wǎng)絡(luò)的AI編解碼算法,它的權(quán)重是可以進(jìn)行修改的,這是一個(gè)很大的優(yōu)勢(shì)。

接下來(lái)介紹個(gè)人認(rèn)為對(duì)AI編解碼器較為重要的六個(gè)評(píng)價(jià)維度,第一是率失真性能和主觀質(zhì)量,它主要和壓縮率有關(guān);第二是復(fù)雜度,它與延時(shí)、計(jì)算量和顯存的要求還有功耗、吞吐率等因素有關(guān);第三是跨平臺(tái)解碼,在手機(jī)、CPU、GPU上互相編解碼不應(yīng)該出錯(cuò);第四是對(duì)下游AI任務(wù)訓(xùn)練和推理的影響,對(duì)測(cè)試或推理的影響類似于現(xiàn)在比較熱門的面向機(jī)器視覺(jué)的編解碼,在訓(xùn)練方面大家會(huì)比較關(guān)注用AI壓縮的數(shù)據(jù)是否會(huì)對(duì)神經(jīng)網(wǎng)絡(luò)的訓(xùn)練效果產(chǎn)生影響;第五是泛化與特化能力,有時(shí)我們希望它可以泛化,使用同一個(gè)模型可以壓縮不同數(shù)據(jù),有時(shí)我們希望它可以特異化,例如在壓縮遙感或者醫(yī)學(xué)類數(shù)據(jù)時(shí),可以構(gòu)造專門的模型使對(duì)應(yīng)數(shù)據(jù)的壓縮率更高;最后則是轉(zhuǎn)碼穩(wěn)定性,這也是一個(gè)有意思的問(wèn)題,包括傳統(tǒng)算法和AI算法間的互編互解,例如將JPEG二次壓縮再解碼,過(guò)程中是否有性能損失。
-02-
提升RD性能與解碼速度

接下來(lái)介紹如何提升RD性能和解碼速度,圖中的白色文字為前人所做的一些早期經(jīng)典研究成果。第一篇為紐約大學(xué)的論文,模型成果第一次在PSNR上超過(guò)JPEG 2000。第三篇論文的模型成果首次在PSNR上超過(guò)BPG,BPG對(duì)應(yīng)H.265的幀內(nèi)壓縮技術(shù),但解碼速度下降了約60倍。
我們的工作自此開(kāi)始展開(kāi),具體表述為下面的黃字部分。首先我們于2021年構(gòu)造了棋盤格上下文模型,消除了60倍復(fù)雜度,又于2022年對(duì)模型進(jìn)行了一些新的改進(jìn)。
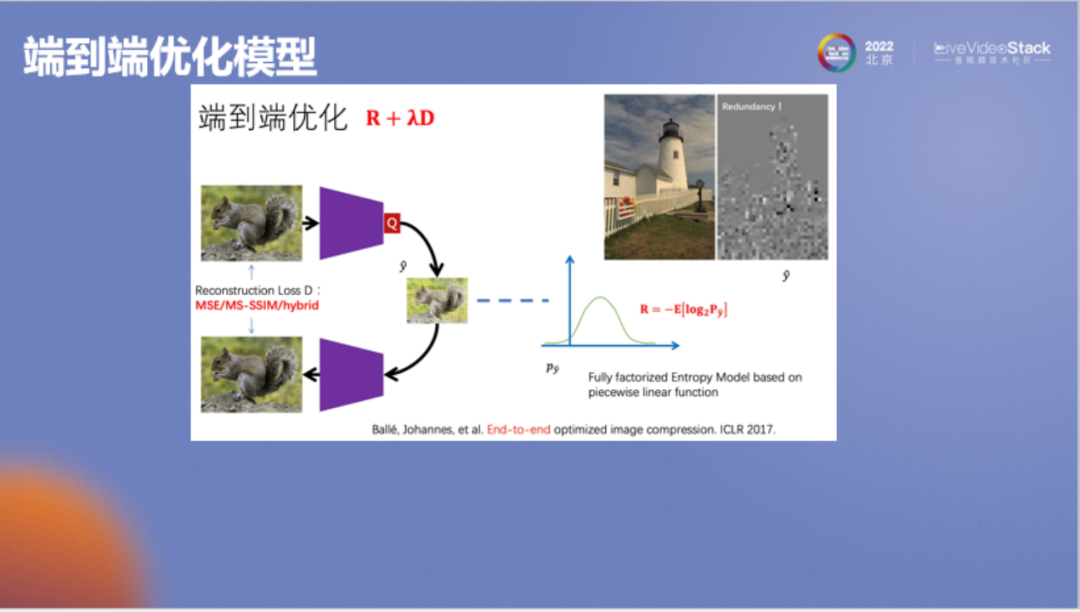
以上是紐約大學(xué)在ICLR上發(fā)表的論文,它是一個(gè)簡(jiǎn)單的變分自編碼器(Variational Auto-Encoders)。它首先將圖像變到一個(gè)特征域進(jìn)行概率估計(jì),然后用熵編碼對(duì)特征進(jìn)行壓縮。該模型是2017年的研究成果,當(dāng)時(shí)已經(jīng)超過(guò)了JPEG 2000。

論文作者在加入谷歌后構(gòu)造了一個(gè)新的尺度超先驗(yàn)?zāi)P停⊿cale Hyperprior)。它的思想是:在壓縮神經(jīng)網(wǎng)絡(luò)特征時(shí)我們實(shí)際使用的是獨(dú)立假設(shè),由于它是一個(gè)很高維的向量,所以不能使用聯(lián)合概率密度分布。該模型通過(guò)引入先驗(yàn)Z使得要壓縮的特征Y變?yōu)闂l件獨(dú)立,因而可以使用概率密度估計(jì)和熵編碼算法將特征Y壓縮得更小。該模型中特征Y和先驗(yàn)Z的碼率之和比2017年論文中Y的碼率更小,這是通過(guò)引入更精準(zhǔn)的數(shù)學(xué)建模帶來(lái)的提升。
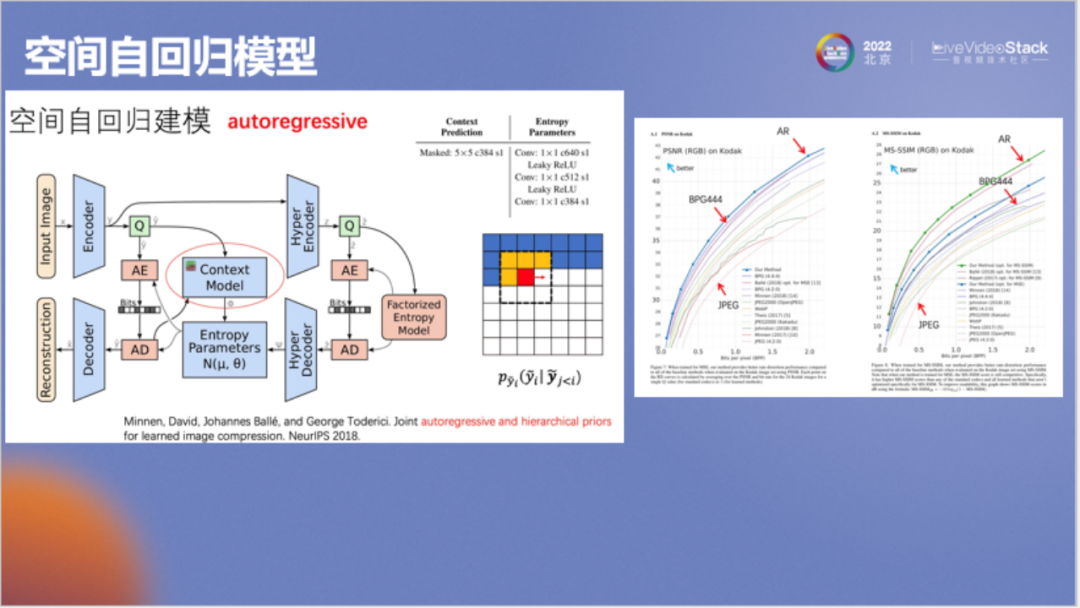
谷歌接著又對(duì)模型做了進(jìn)一步改進(jìn),即前面提到的空間自回歸模型(autoregressive),它的思想是:在壓縮碼字Y時(shí)我們并不能做到獨(dú)立壓縮,如在壓縮左側(cè)方格圖中的紅色像素時(shí),需一并考慮周邊的黃色像素結(jié)果,這與傳統(tǒng)算法中的幀內(nèi)預(yù)測(cè)相似,被稱為自回歸。模型效果如右圖所示,其成果第一次超過(guò)了BPG,非常有代表性。

接下來(lái)介紹我們的算法,剛才提到的自回歸模型要逐個(gè)像素串行解碼,速度相當(dāng)慢。我們?cè)诖嘶A(chǔ)上提出右圖所示的棋盤格模型。例如在第一次解碼時(shí),我們使用GPU來(lái)并行解碼右側(cè)方格圖中所有藍(lán)色和黃色的點(diǎn),第二次解碼紅色和白色點(diǎn),由此可通過(guò)兩次解碼解出整張圖。按照谷歌的原方法,串行復(fù)雜度為N^2,使用棋盤格模型,串行復(fù)雜度僅為2。
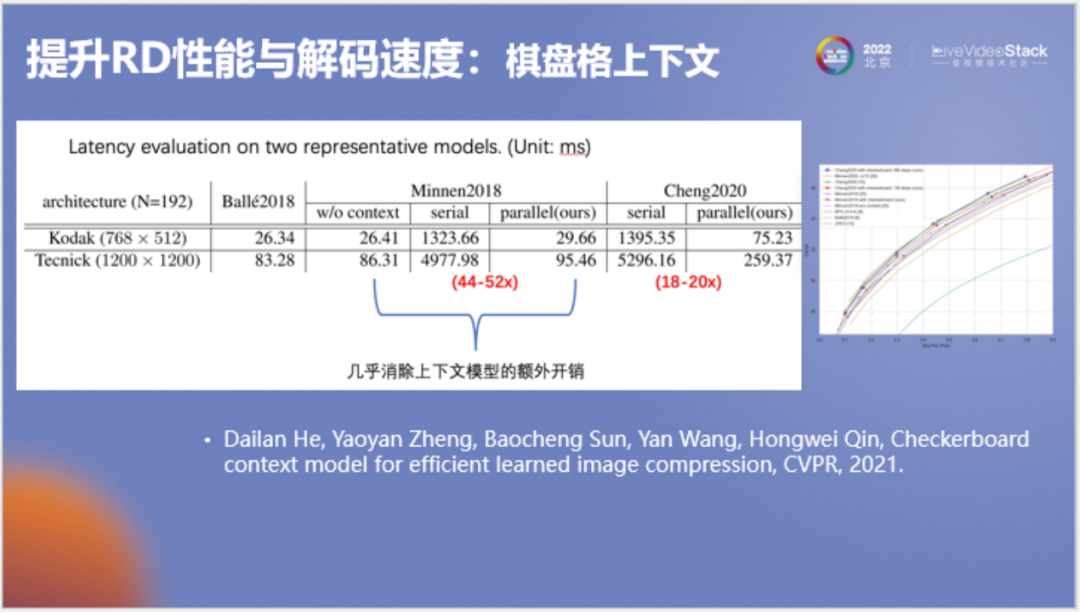
以上為測(cè)速結(jié)果,在典型模型上棋盤格模型能加速40到50倍,在變換網(wǎng)絡(luò)較大的模型上能加速18到20倍。該研究成果發(fā)表于CVPR 2021。
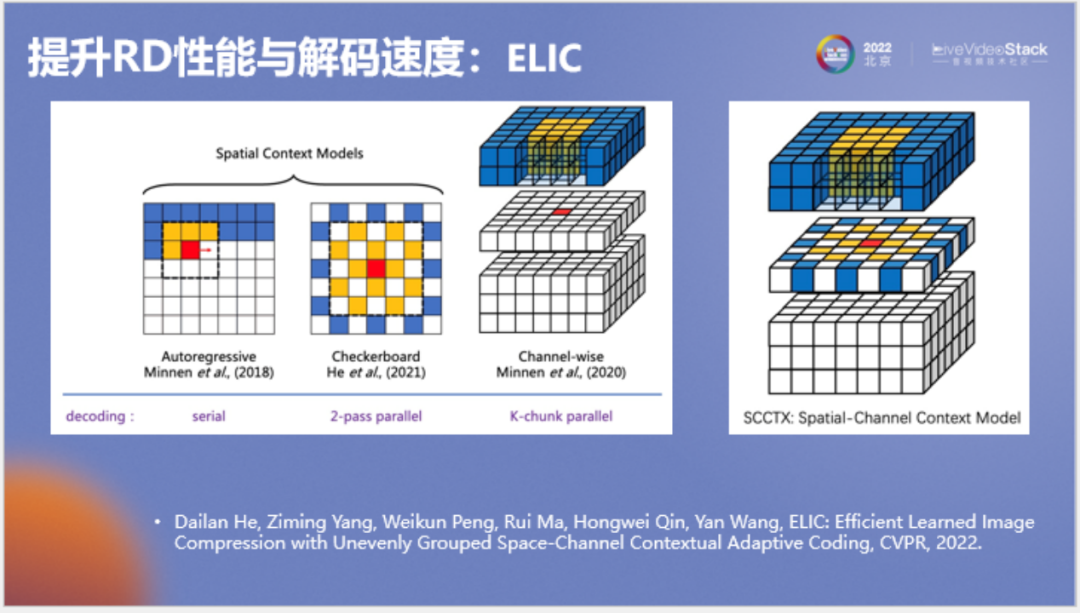
在2022年CVPR中,我們對(duì)原論文進(jìn)行了改進(jìn),將谷歌的自回歸模型和棋盤格模型進(jìn)行了結(jié)合,成為了一種既有通道自回歸、也有空間上下文的并行上下文模型,該模型取得了非常好的效果。
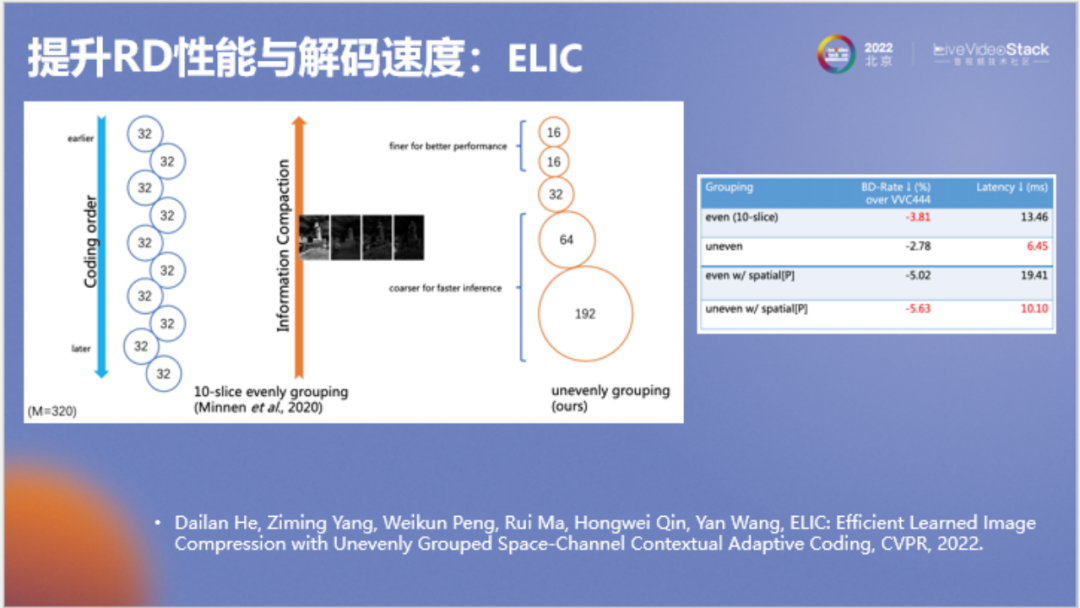
以上為對(duì)模型所做的另一項(xiàng)改進(jìn),即將通道劃分改為非均勻劃分。谷歌原模型每個(gè)通道分組都為32,需要的分組較多。我們發(fā)現(xiàn)實(shí)際上其中信息的分布是不對(duì)稱的,只有少數(shù)信息分組比較重要。為了提高速度,我們將非重要分組進(jìn)行了合并,在提高速度的同時(shí)甚至提高了壓縮率。
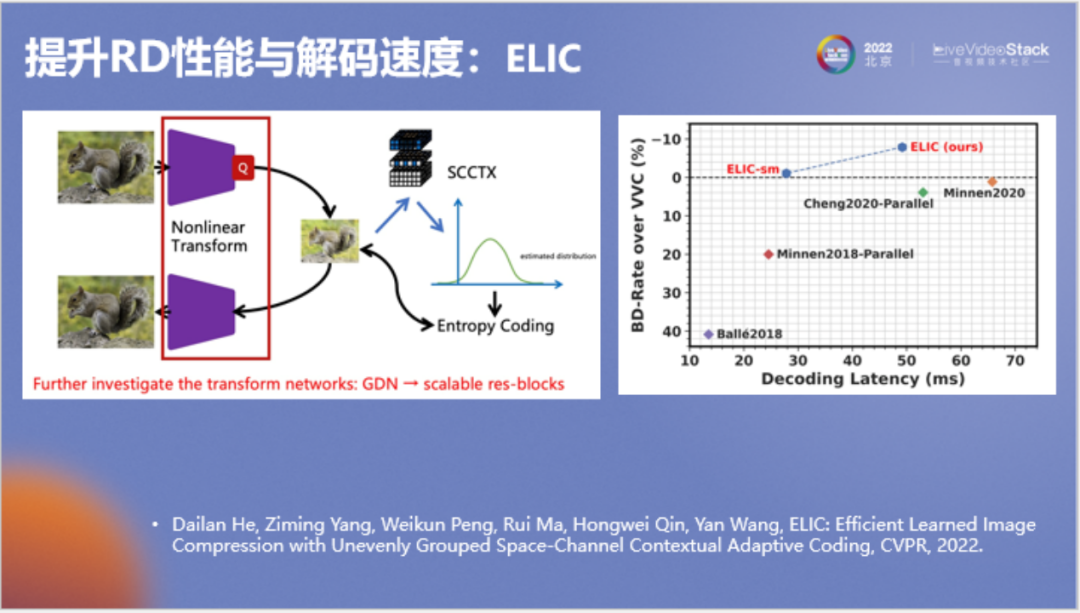
以上是我們新模型的結(jié)果,顯示為紅色,最終要優(yōu)于VVC,并且與之前的一些網(wǎng)絡(luò)速度相近。圖表中橫軸為解碼速度,縱軸為壓縮率。
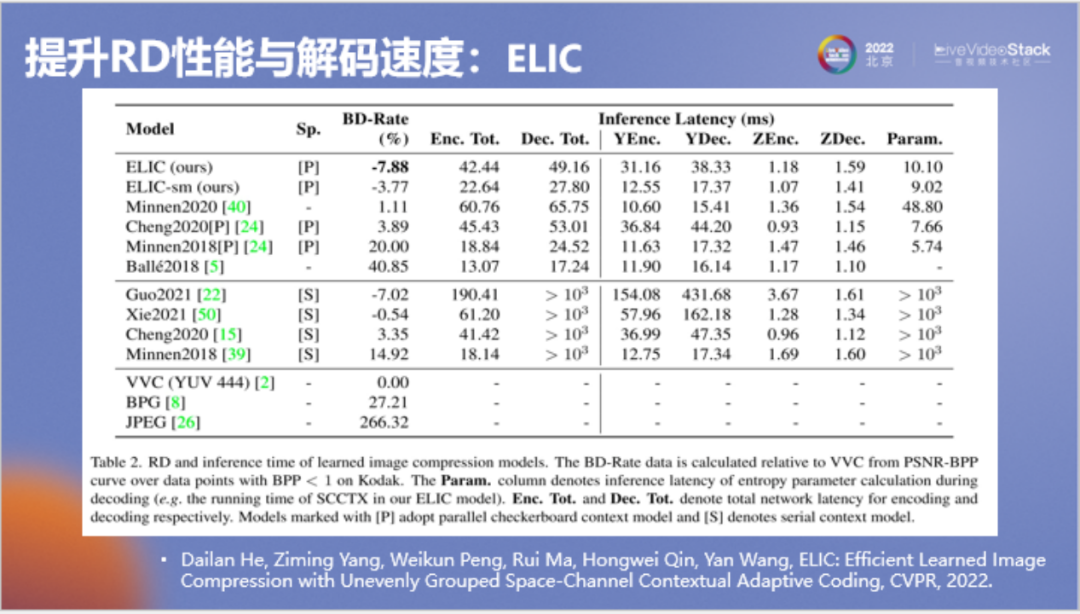
上表可以更加直觀體現(xiàn)論文研究成果的貢獻(xiàn),這實(shí)際是端到端圖像壓縮領(lǐng)域的一個(gè)里程碑式的進(jìn)展。可以看到所有在BD-Rate上顯示為負(fù)數(shù)的優(yōu)于VVC的方法,其解碼速度都要大于1000,解碼一張圖大約要大于1秒。早期論文的解碼速度都在20到50毫秒。我們的論文首次實(shí)現(xiàn)了BD-Rate在約-7%時(shí),解碼速度仍只有50毫秒,這是相當(dāng)快的速度。

此后我們對(duì)VAE框架進(jìn)行了進(jìn)一步研究,VAE框架中存在均攤變分推理現(xiàn)象,利用這個(gè)現(xiàn)象引入半均攤變分推理,可以在編碼時(shí)對(duì)碼字進(jìn)行一定更新并實(shí)現(xiàn)很多靈活的控制。如可以實(shí)現(xiàn)連續(xù)變碼率,使用同一個(gè)解碼器可以解不同碼率的圖像。可以實(shí)現(xiàn)任意ROI編碼,還可以去權(quán)衡不同的質(zhì)量評(píng)價(jià)指標(biāo),比如PSNR和LPIPS,大家知道這些指標(biāo)和主觀質(zhì)量的相關(guān)性各有不同,權(quán)衡不同指標(biāo)等于在權(quán)衡解碼圖像的不同特點(diǎn)。我們將相關(guān)方法也擴(kuò)展到了端到端視頻編解碼上,相關(guān)成果發(fā)表在ICML 2023。

這是我們發(fā)在NeurIPS 2022上的一篇論文,端到端圖像壓縮領(lǐng)域除了調(diào)整網(wǎng)絡(luò)結(jié)構(gòu)外,其實(shí)會(huì)有比較深入的理論背景,我們對(duì)理論進(jìn)行了更深入的探索,將單樣本采樣改為多樣本采樣。造成的結(jié)果是訓(xùn)練速度會(huì)變慢一些,但壓縮和解壓縮速度完全不受影響。利用這個(gè)技術(shù)我們?nèi)〉昧艘粋€(gè)較明顯的壓縮率的提升。
-03-
提升主觀質(zhì)量

下面介紹一下如何提升主觀質(zhì)量。一般編解碼器在進(jìn)行設(shè)計(jì)時(shí),優(yōu)化指標(biāo)為PSNR、 SSIM或VMAF。但它們與主觀質(zhì)量的差距都較大,實(shí)際上也不存在與主觀質(zhì)量絕對(duì)一致的數(shù)學(xué)指標(biāo),這給我們?cè)斐闪撕艽罄щy,一般我們會(huì)選擇同時(shí)優(yōu)化多個(gè)數(shù)學(xué)指標(biāo)來(lái)使最終的主觀質(zhì)量變好。

在端到端圖像壓縮領(lǐng)域一般會(huì)有兩個(gè)較常見(jiàn)的數(shù)學(xué)指標(biāo):PSNR和MS-SSIM,我們希望設(shè)計(jì)一種模型,在其訓(xùn)練后使兩種指標(biāo)都較高,最后的主觀質(zhì)量更好。
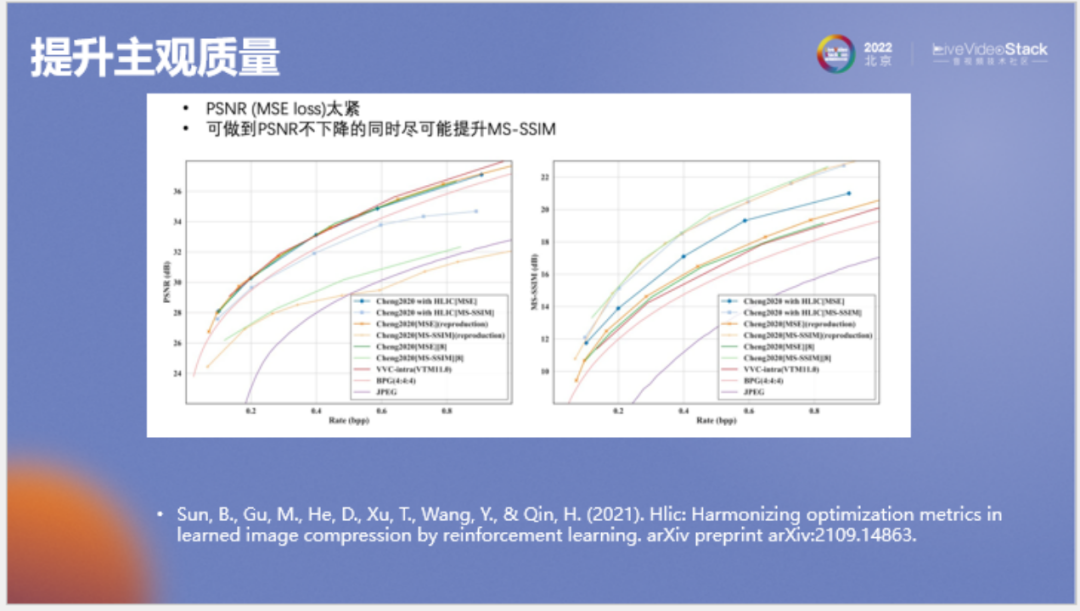
通過(guò)實(shí)驗(yàn)發(fā)現(xiàn),我們能夠做到在PSNR不下降的情況下盡可能提升SSIM指標(biāo),使主觀質(zhì)量得到提升。

以上為展示效果圖,左上角為原圖,最右側(cè)為VVC結(jié)果。中間以SSIM標(biāo)記的是使用MS-SSIM做損失函數(shù)訓(xùn)練的模型所優(yōu)化的結(jié)果,最終會(huì)出現(xiàn)色偏。用MSE訓(xùn)練的結(jié)果在碼率較低的位置(如圖中水的位置)會(huì)損失紋理。使用我們的方法訓(xùn)練的兩個(gè)模型可以較好的平衡PSNR和SSIM,不發(fā)生色偏和紋理?yè)p失。

在上圖中情況是相同的,尤其在草地部分,MSE結(jié)果草地會(huì)較糊,SSIM結(jié)果草地顏色會(huì)出現(xiàn)偏差,而經(jīng)過(guò)改進(jìn)后模型的效果是較好的。

谷歌也相當(dāng)重視提升主觀質(zhì)量這方面工作,在每年的CVPR上都會(huì)組織圖像壓縮競(jìng)賽,該賽事?lián)碛斜容^完善的主觀質(zhì)量評(píng)估流程,通過(guò)眾包的方式請(qǐng)很多人來(lái)看圖,會(huì)規(guī)定圖片的分辨率和與屏幕的不同距離來(lái)評(píng)估解壓圖像的主觀質(zhì)量,競(jìng)賽的組織者一般是國(guó)際上比較知名的一些廠商。

我們也參加了該賽事,使用的方法就是同時(shí)優(yōu)化多個(gè)數(shù)學(xué)指標(biāo),第一個(gè)是感知損失,第二是重建損失(例如PSNR或SSIM),第三是對(duì)抗損失,第四是風(fēng)格損失,其中三個(gè)損失函數(shù)都和深度學(xué)習(xí)有關(guān)。我們將四個(gè)損失函數(shù)以一種特定系數(shù)去進(jìn)行組合,最后優(yōu)化出來(lái)的模型在各種評(píng)價(jià)指標(biāo)上都是最佳的。
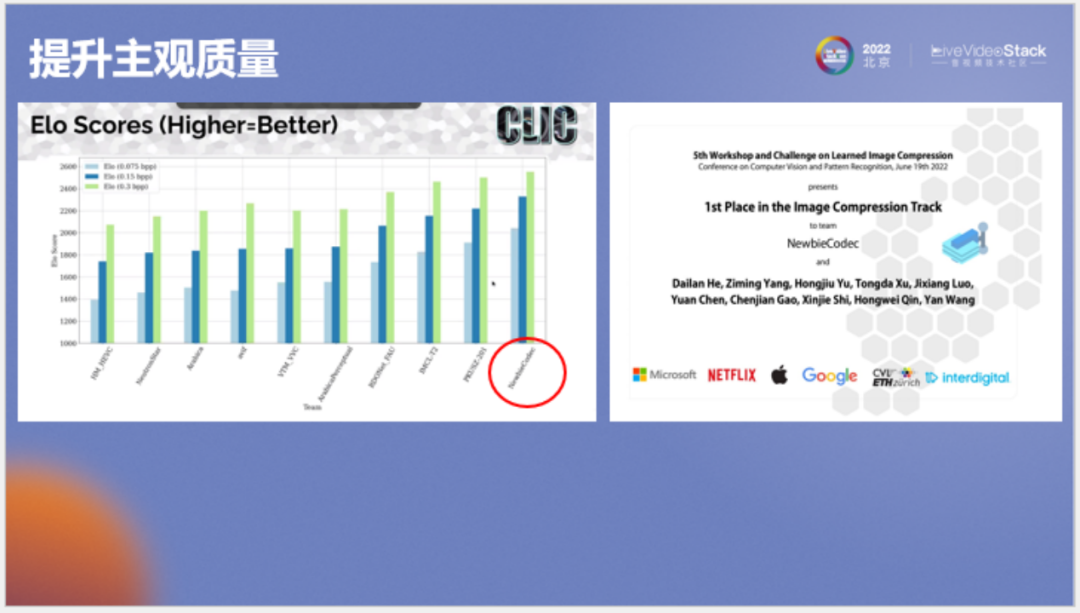
我們以該模型解壓的圖像參賽,最終獲得了所有碼點(diǎn)的第一名。
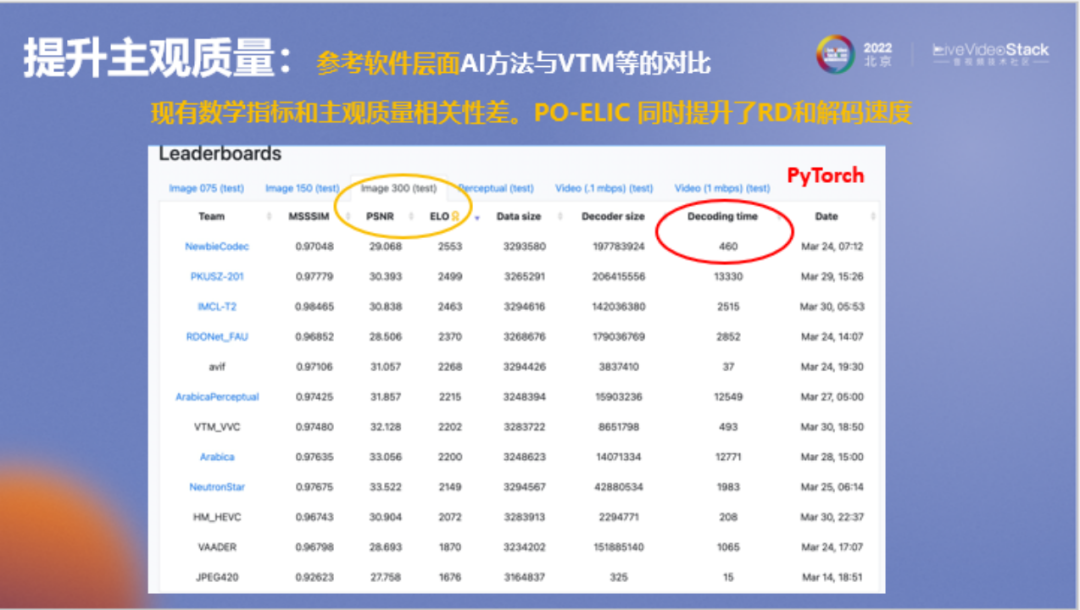
這是谷歌官網(wǎng)對(duì)所有方法的評(píng)測(cè)結(jié)果,首先我們關(guān)注一下主觀質(zhì)量和數(shù)學(xué)指標(biāo)間的關(guān)系,例如PSNR,我們可以看到像avif、VVC和HEVC方法的PSNR都較高,但對(duì)應(yīng)的ELO列(人眼看圖的主觀質(zhì)量)都不太好,印證了PSNR和SSIM不代表主觀質(zhì)量這一結(jié)論。
另一方面,可以看到我們方法的解碼速度,它是用PyTorch編寫的,解碼速度達(dá)到了460,VVC在谷歌測(cè)試中是493。我們的模型主觀質(zhì)量比VVC更好,解碼速度還要更快,但比avif在解碼速度上要慢一些。
不過(guò)需要注意的是,它只是參考軟件層面的對(duì)比,因?yàn)檫@里的VVC是使用VTM進(jìn)行測(cè)試,AI方法一般是使用PyTorch進(jìn)行測(cè)試,所有方法都沒(méi)有進(jìn)行工業(yè)級(jí)的性能優(yōu)化。
-04-
跨平臺(tái)編碼
下面講一個(gè)看起來(lái)比較偏,但實(shí)際對(duì)編解碼比較重要的問(wèn)題,即跨平臺(tái)解碼。
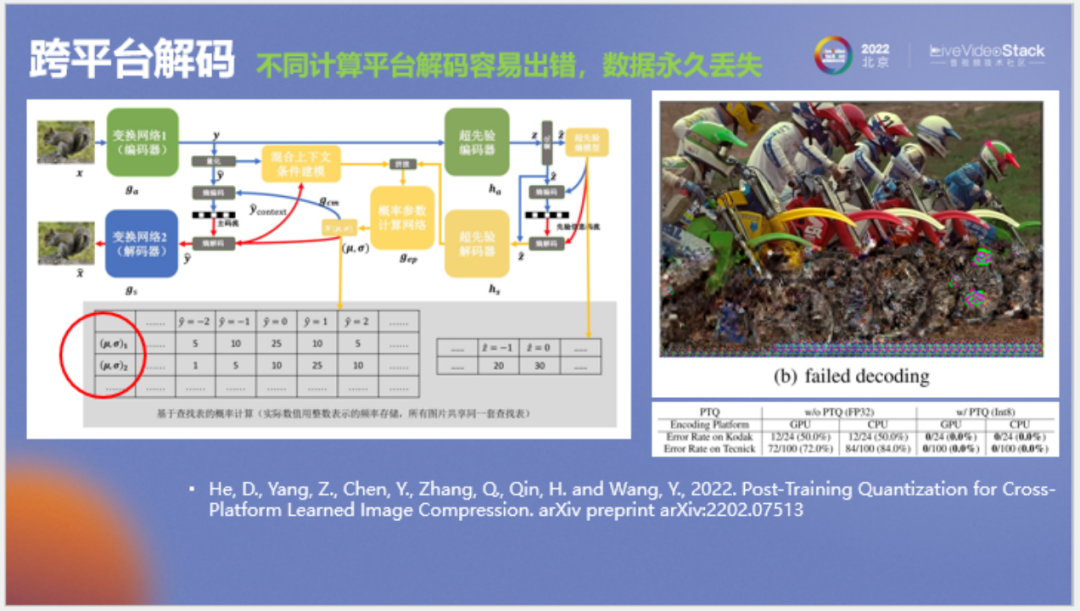
這個(gè)問(wèn)題主要來(lái)自于熵編碼,我們進(jìn)行熵編碼或算數(shù)編碼時(shí)每個(gè)碼字的概率不能出錯(cuò),如果有任何微小的錯(cuò)誤,后面的碼點(diǎn)便解不出來(lái)。如上圖所示,前面一直在正常解碼,一旦算到某處一個(gè)像素不對(duì),那么后面所有的解碼都會(huì)出錯(cuò),概率錯(cuò)了所有碼點(diǎn)都解不出來(lái)。假如在壓縮圖片時(shí)原先使用的硬件丟失,那么圖片數(shù)據(jù)也會(huì)永久消失。
這個(gè)問(wèn)題的解決辦法是使圖片的編解碼過(guò)程,尤其是熵編碼的概率計(jì)算過(guò)程不管在何種硬件上(如CPU、GPU還是不同型號(hào)的NPU或DSP)計(jì)算結(jié)果都完全一致。據(jù)我所知,唯一的方法便是使用完全整數(shù)計(jì)算來(lái)實(shí)現(xiàn)。
首先針對(duì)概率計(jì)算有關(guān)的所有神經(jīng)網(wǎng)絡(luò),我們均使用全整數(shù)推理,同時(shí)以使用查找表而非直接計(jì)算的方式來(lái)進(jìn)行概率計(jì)算。這樣所有過(guò)程都是用整數(shù)來(lái)實(shí)現(xiàn)的,可以確保編解碼具備跨平臺(tái)條件。以上工作比較細(xì)節(jié),所以我們公開(kāi)了一個(gè)比較詳細(xì)的技術(shù)報(bào)告,有興趣實(shí)現(xiàn)技術(shù)落地的可以參考。
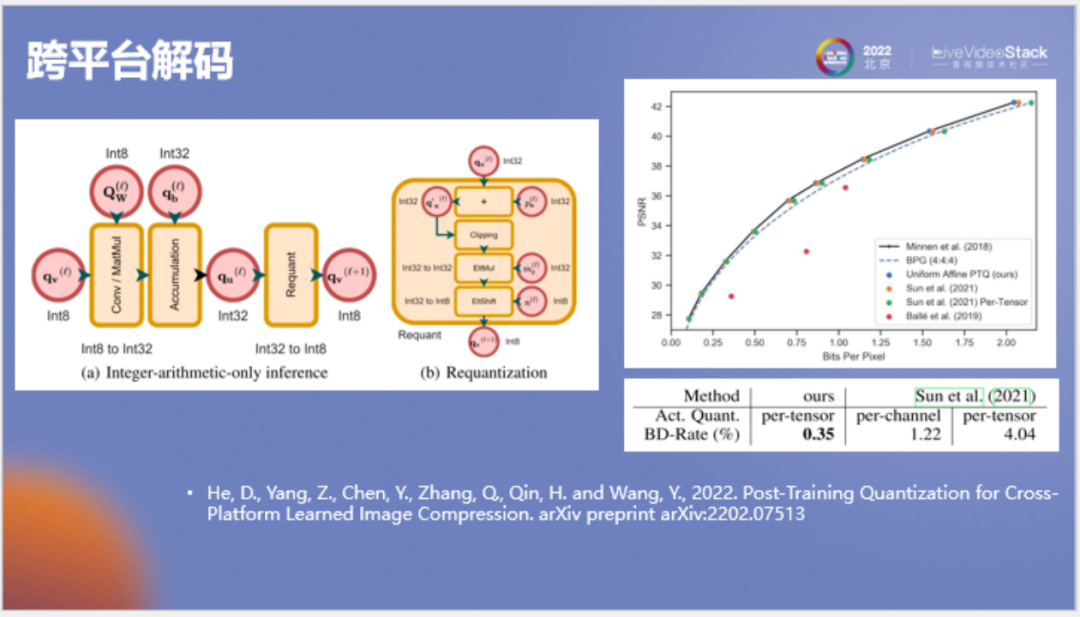
上圖為性能對(duì)比,我們將新方法和之前類似的方法進(jìn)行了對(duì)比,我們是首先在有上下文的圖像壓縮模型上實(shí)現(xiàn)不掉點(diǎn)的整數(shù)推理,而且我們的量化方案比較標(biāo)準(zhǔn),沒(méi)用對(duì)激活值進(jìn)行逐個(gè)通道的分組量化,適用于常見(jiàn)的GPU和NPU。
-05-
優(yōu)化延時(shí)與吞吐

最后關(guān)于有損壓縮方面介紹一下優(yōu)化延時(shí)與吞吐。優(yōu)化一個(gè)AI編解碼器的速度主要包括兩部分工作:一是優(yōu)化神經(jīng)網(wǎng)絡(luò)推理的延時(shí),另一個(gè)是優(yōu)化熵編碼的延時(shí)。最后整個(gè)系統(tǒng)要做一個(gè)代碼層面或者軟件工程層面的優(yōu)化。
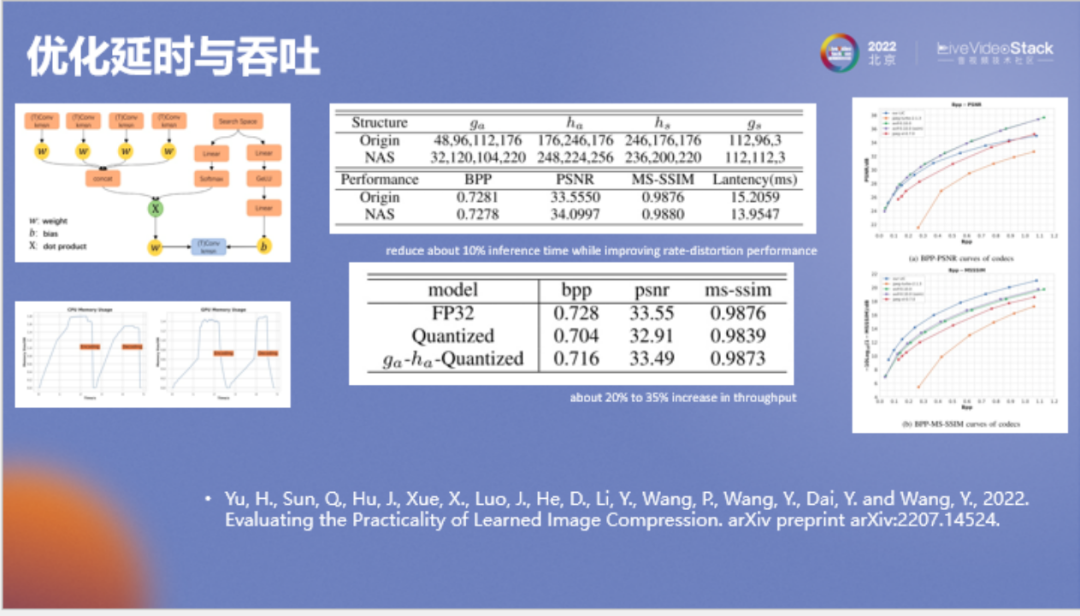
首先看一下神經(jīng)網(wǎng)絡(luò)的優(yōu)化,它的方法都是比較標(biāo)準(zhǔn)的。其中一個(gè)是神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(NAS),一個(gè)是模型量化。NAS提升顯得較小是因?yàn)檫@些神經(jīng)網(wǎng)絡(luò)已經(jīng)經(jīng)過(guò)了人工優(yōu)化。左下角是它的CPU和GPU顯存占用情況。由于針對(duì)此模型我們主要調(diào)整它的主觀質(zhì)量,所以它的PSNR會(huì)弱一些。可以看到該模型的PSNR比avif低,但SSIM值很高。
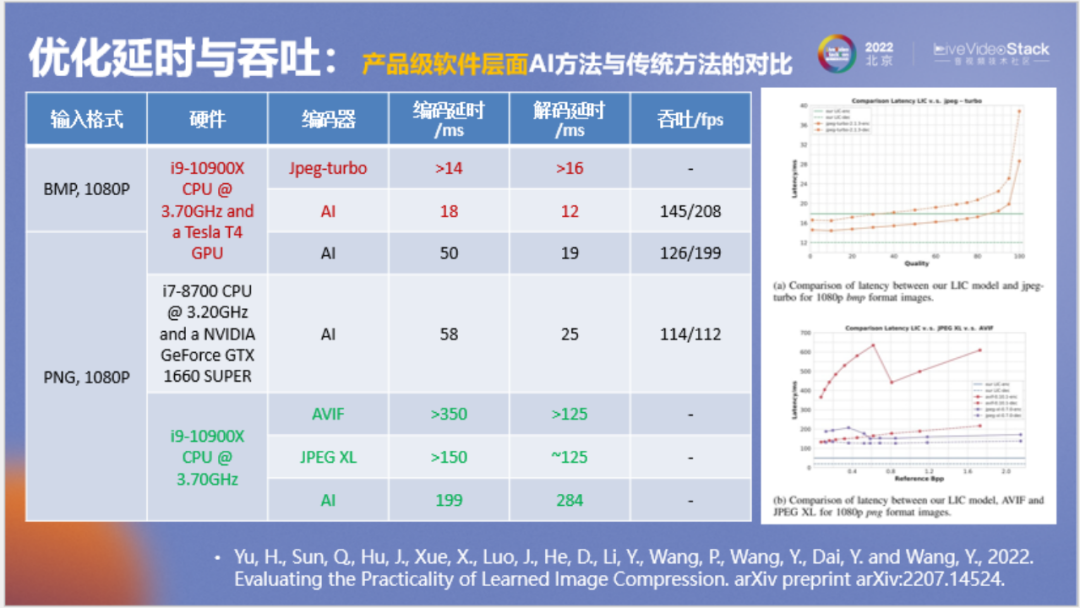
在本頁(yè)我們想回答一個(gè)問(wèn)題,神經(jīng)網(wǎng)絡(luò)圖像壓縮和傳統(tǒng)方法相比性能有何差距?我們希望進(jìn)行相對(duì)公平的對(duì)比。首先要使用相同的硬件,例如都使用CPU,以編解碼延時(shí)來(lái)衡量,神經(jīng)網(wǎng)絡(luò)圖像壓縮和JPEG XL和avif在性能上是接近的,如果我們將avif和JPEG XL作為工業(yè)應(yīng)用的發(fā)展方向,顯然神經(jīng)網(wǎng)絡(luò)圖像壓縮也可以作為一個(gè)發(fā)展方向。
如果我們看GPU,可以發(fā)現(xiàn)在相同的輸入條件下,神經(jīng)網(wǎng)絡(luò)方法和JPEG-turbo相比,它在編解碼上并沒(méi)有很大的劣勢(shì),解碼還要快一些。
但這里有一個(gè)關(guān)于線程的小問(wèn)題,從JPEG官網(wǎng)來(lái)看,它的測(cè)試也會(huì)有一些問(wèn)題,就是到底采用什么樣的線程數(shù)來(lái)測(cè)試這些模型,使用不同的線程數(shù)測(cè)試結(jié)果也不同。我們采用了單線程進(jìn)行測(cè)試,對(duì)于傳統(tǒng)方法采用的是默認(rèn)配置,使用多線程在測(cè)吞吐時(shí)會(huì)有更大優(yōu)勢(shì),具體可以參考我們的技術(shù)報(bào)告。這個(gè)結(jié)果可以作為一個(gè)參考,實(shí)際使用中應(yīng)該結(jié)合運(yùn)行環(huán)境進(jìn)一步對(duì)線程資源進(jìn)行適配。
-06-
應(yīng)用拓展:JPEG無(wú)損壓縮
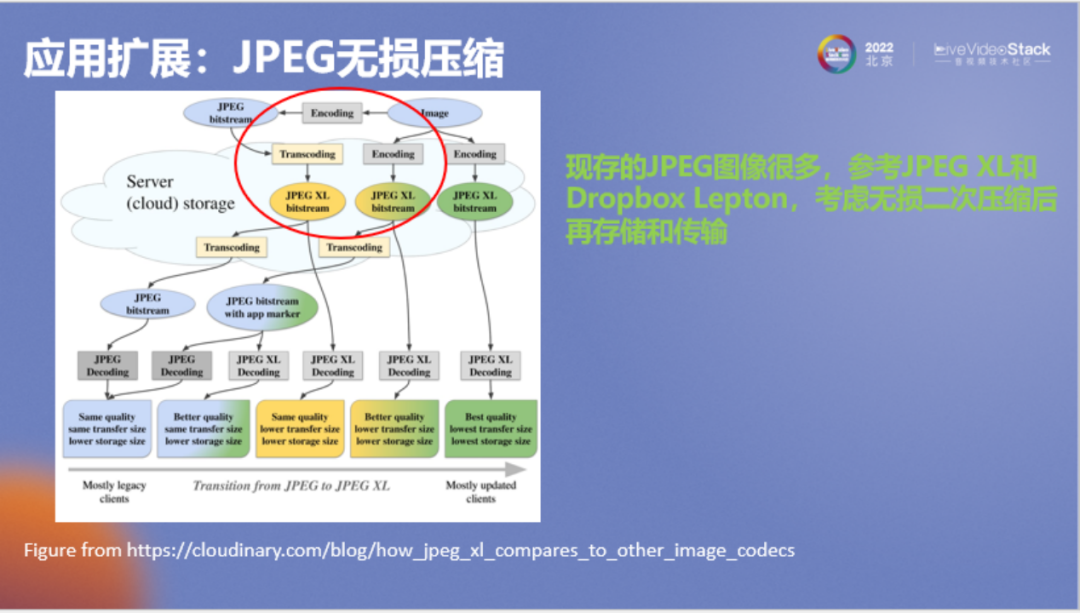
剛才介紹了有損壓縮,接下來(lái)分享一個(gè)比較有意思的應(yīng)用,即無(wú)損壓縮。假如端到端有損壓縮方法實(shí)際落地要等很長(zhǎng)時(shí)間,那么我們現(xiàn)在已經(jīng)有了非常多的JPEG圖像,能不能考慮使用AI方法對(duì)這些圖像進(jìn)行無(wú)損壓縮。
其實(shí)已經(jīng)有人注意到這個(gè)問(wèn)題,但使用的不是神經(jīng)網(wǎng)絡(luò),例如JPEG XL或者Dropbox的Lepton,Lepton目前已經(jīng)被Dropbox使用了很久,它的思想是在進(jìn)行云存儲(chǔ)時(shí)對(duì)JPEG圖像進(jìn)行無(wú)損二次壓縮,在不改變用戶數(shù)據(jù)的同時(shí)極大壓縮存儲(chǔ)量。所以它整個(gè)生態(tài)不會(huì)受到任何影響,在網(wǎng)絡(luò)上還是以JPEG格式進(jìn)行傳遞,但是云存儲(chǔ)使用的是二次壓縮后的碼流。
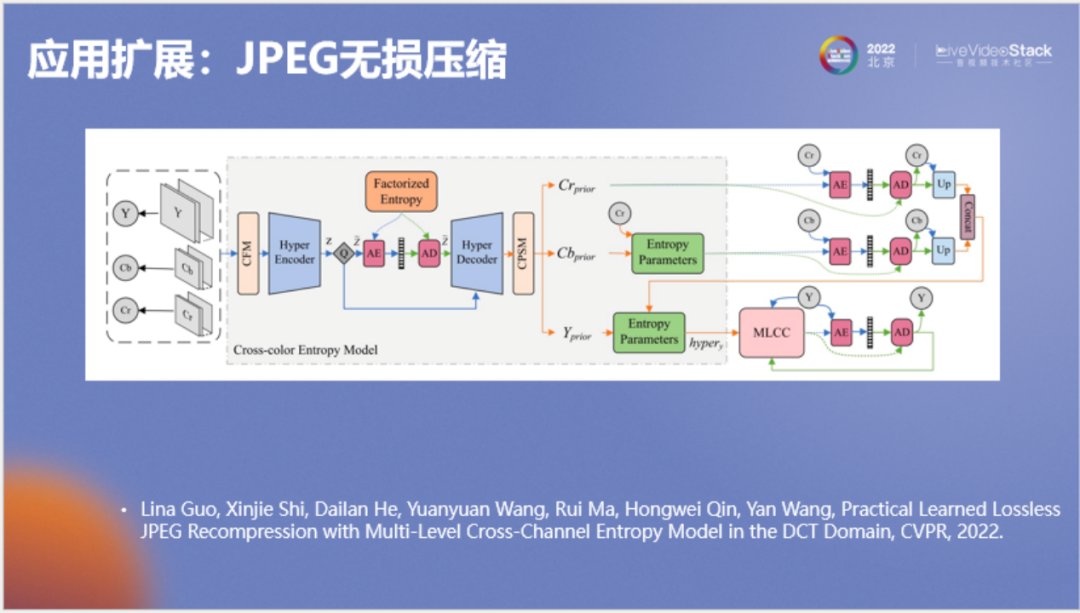
就此我們?cè)贑VPR上也發(fā)表了一篇文章,專門介紹如何使用神經(jīng)網(wǎng)絡(luò)來(lái)無(wú)損壓縮JPEG圖像。在這里對(duì)研究?jī)?nèi)容做一個(gè)簡(jiǎn)單介紹,首先我們將JPEG圖像的三個(gè)分量(YUV或YCbCr)整合成一個(gè)引變量Z,整合后的Z涵蓋了YUV之間的關(guān)聯(lián),在壓縮YUV三個(gè)分量前使用Z來(lái)作為先驗(yàn)。Y叫作亮度分量,由于它包含的信息最多,所以我們?yōu)檫@個(gè)分量專門設(shè)計(jì)一個(gè)模型叫作MLCC,它的結(jié)構(gòu)如下。
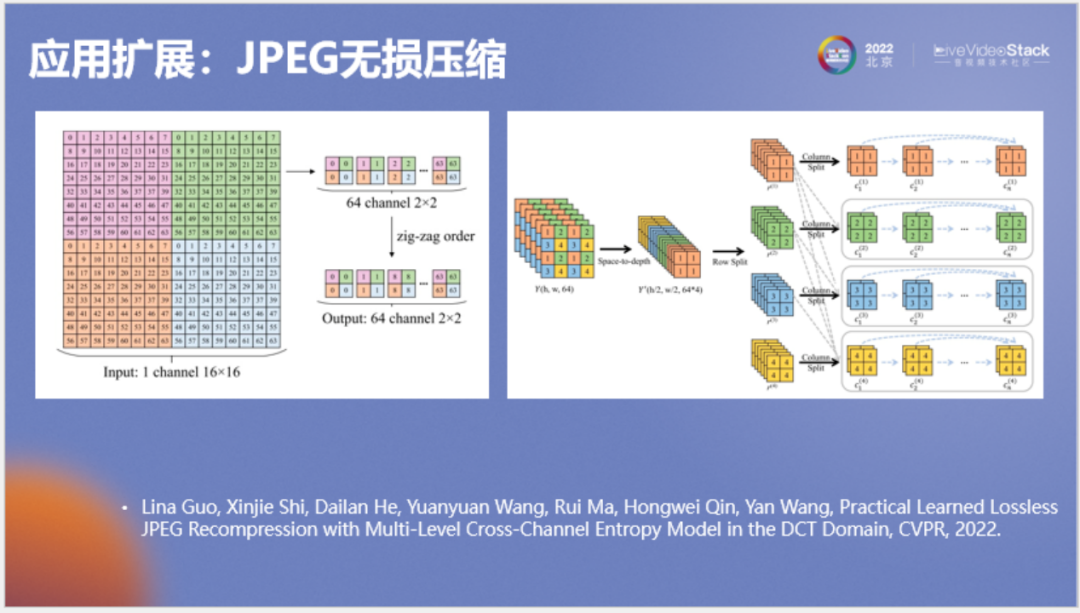
MLCC是一種比較復(fù)雜的并行自回歸模型。左圖中為JPEG的dct系數(shù),我們對(duì)它進(jìn)行重新排列,將相同頻率排到神經(jīng)網(wǎng)絡(luò)的相同通道上得到右圖,并將右圖中三維長(zhǎng)方體的行列進(jìn)行展開(kāi),按照類似自回歸的方式進(jìn)行條件建模。它看起來(lái)很復(fù)雜,但實(shí)際執(zhí)行的速度還是很快的。
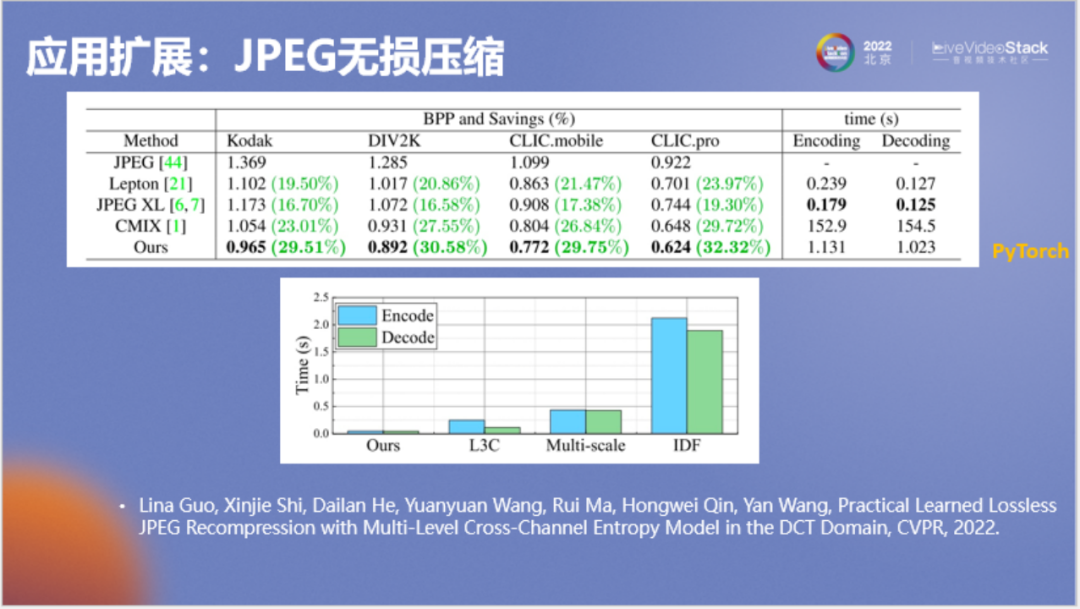
以上為測(cè)速結(jié)果,Dropbox在大規(guī)模使用的Lepton,其無(wú)損壓縮率是20%左右,編碼解碼時(shí)間分別是0.239和0127。JPEG XL稍差,但編碼稍微快一些。作為傳統(tǒng)算法中號(hào)稱最強(qiáng)的無(wú)損壓縮器CMIX,它的壓縮率能達(dá)到23%或27%,但編碼和解碼時(shí)間都很長(zhǎng),要150秒。該軟件是壓縮從業(yè)者為了探索無(wú)損壓縮極限構(gòu)造出的一套十分復(fù)雜的模型,它的算力消耗和內(nèi)存消耗都非常非常大。
我們的神經(jīng)網(wǎng)絡(luò)方法壓縮率可以達(dá)到29%或30%以上,優(yōu)于CMIX,使用PyTorch在GPU上的編解碼時(shí)間大約為1秒,比Lepton要慢約十倍。
不過(guò)我們要知道Lepton不是一個(gè)參考軟件,而是一個(gè)工業(yè)軟件,我們的算法作為學(xué)術(shù)上的參考軟件,兩者gap并不大。
我們也將神經(jīng)網(wǎng)絡(luò)方法和之前做無(wú)損壓縮的一些網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了對(duì)比,可以看到本方法的編解碼時(shí)間實(shí)際是比較短的。
小結(jié)

下面進(jìn)行一個(gè)小結(jié)。經(jīng)過(guò)剛才提到的一些優(yōu)化,AI編解碼方法整體上在一些場(chǎng)景下是可以使用的,但在我剛才提到的六個(gè)維度上還有一些持續(xù)的挑戰(zhàn)。

本次分享的內(nèi)容來(lái)自這些已經(jīng)發(fā)表或公開(kāi)的論文和技術(shù)報(bào)告,感謝商湯科技和清華大學(xué)的合作者。
審核編輯:劉清




























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論