 電子發(fā)燒友App
電子發(fā)燒友App


本篇是《Rust與AI》系列的第二篇,上一篇我們主要介紹了本系列的概覽和方向,定下了一個(gè)基調(diào)。本篇我們將介紹LLM的基本架構(gòu),我們會(huì)以迄今為止使用最廣泛的開源模型LLaMA為例展開介紹。
LLM背景
Rust 本身是不挑 AI 模型的,但是 LLM 是當(dāng)下最熱的方向,我們就從它開始吧,先了解一些非常基礎(chǔ)的背景知識(shí)。
Token
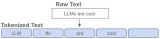
LLM 中非常重要的一個(gè)概念是 Token,我們輸入給 LLM 和它輸出的都是 Token。Token 在這里可以看做語言的基本單位,中文一般是詞或字(其實(shí)字也是詞)。比如:”我們喜歡 Rust 語言“,Token 化后會(huì)變成類似 ”我們/喜歡/Rust/語言“ 這樣的四個(gè)詞,可以理解為四個(gè) Token。
給定一段任意的自然語言文本,我們可以用一個(gè)分詞器(Tokenizer)將其 Token 化成一個(gè)個(gè)連續(xù)的 Token。這些 Token 接下來就可以映射成一個(gè)個(gè)數(shù)字,其實(shí)是在詞表中的索引,索引進(jìn)而可以找到一個(gè)稠密向量,用來表示該位置 Token 的語義輸入。
我們以剛剛的”我們喜歡 Rust 語言“為例,假定已有詞表如下。
…… 1000 Rust …… 2000 我們 2001 喜歡 2002 語言 ……
注意,前面的數(shù)字是行號(hào),并不是詞表內(nèi)容。剛剛那句話其實(shí)就是 [2000, 2001, 1000, 2002],這就是 LLM 的輸入。LLM 拿到這些 ID 后,會(huì)在一個(gè)非常大的表里查找對(duì)應(yīng)的稠密向量。這個(gè)非常大的表就是詞表,大小是:詞表大小N × 模型維度,如下所示。
…… 1000 0.9146, 0.066, 0.4469, 0.3867, 0.3221, 0.6566, 0.2895, 。.. …… 2000 0.5702, 0.9579, 0.0992, 0.9667, 0.5013, 0.4752, 0.1397, 。.. 2001 0.2896, 0.7756, 0.6392, 0.4034, 0.3267, 0.9643, 0.4311, 。.. 2002 0.4344, 0.6662, 0.3205, 0.3929, 0.6418, 0.6707, 0.2414, 。.. ……
也就是說,輸入”我們喜歡Rust語言“這句話,我們實(shí)際傳遞給模型的其實(shí)是一個(gè) 4×Dim 的矩陣,這里的 4 一般也叫 Sequence Length。
我們可以暫時(shí)把模型看作一個(gè)函數(shù) f(x),輸入一個(gè) Sequence Length × Dim 的矩陣,經(jīng)過模型 f(x) 各種運(yùn)算后會(huì)輸出 Sequence Length × Vocabulary Size 大小的一個(gè)概率分布。有了概率分布就可以采樣一個(gè) Token ID(基于上下文最后一個(gè) Token ID 的分布),這個(gè) ID 也就是給定當(dāng)前上下文(”我們喜歡Rust語言“)時(shí)生成的下一個(gè) Token。接下來就是把這個(gè) ID 拼在剛剛的 4 個(gè) ID 后面(輸入變成 5 個(gè) ID),繼續(xù)重復(fù)這個(gè)過程。
生成
如上所言,生成過程就是從剛剛的概率分布中 “選擇” 出一個(gè) Token ID 作為下一個(gè) Token ID。選擇的方法可以很簡單,比如直接選擇概率最大的,此時(shí)就是 Greedy Search,或 Greedy Decoding。
不過我們平時(shí)用到大模型時(shí)一般都用的是采樣的方法,也就是基于概率分布進(jìn)行采樣。拋硬幣也是一種采樣,按概率分布(0.5,0.5)進(jìn)行采樣,但假設(shè)正面比較重,概率分布就可能變成了(0.8,0.2)了。基于 Vocabulary Size 個(gè)概率值進(jìn)行采樣也是類似的,只不過括號(hào)里的值就是詞表大小那么多個(gè)。
top_p/top_k 采樣是概率值太多了,大部分都是概率很小的 Token,為了避免可能采樣到那些概率很低的 Token(此時(shí)生成的結(jié)果可能很不連貫),干脆就只從前面的 Token 里挑。
top_k 就是把 Token 按概率從大到小排序,然后從前 k 個(gè)里面選擇(采用)下一個(gè) Token;top_p 也是把 Token 按概率從大到小排序,不過是從累積概率大于 p 的 Token 里選。就是這么簡單。
這里有個(gè)小細(xì)節(jié)需要說明,因?yàn)檫x擇了 top_p/k,所以這些備選的 Token 需要重新計(jì)算概率,讓它們的概率和為 1(100%)。
開源代表——LLaMA
接下來,我們把重心放在函數(shù) f(x) 上,以最流行的開源 LLM——LLaMA 為例,簡單介紹一下模型的結(jié)構(gòu)和參數(shù)。
結(jié)構(gòu)
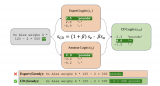
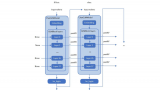
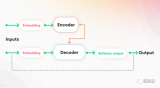
LLaMA 的結(jié)構(gòu)相對(duì)而言比較簡單,如果我們忽略其中的很多細(xì)節(jié),只考慮推理過程,看起來如下圖所示。
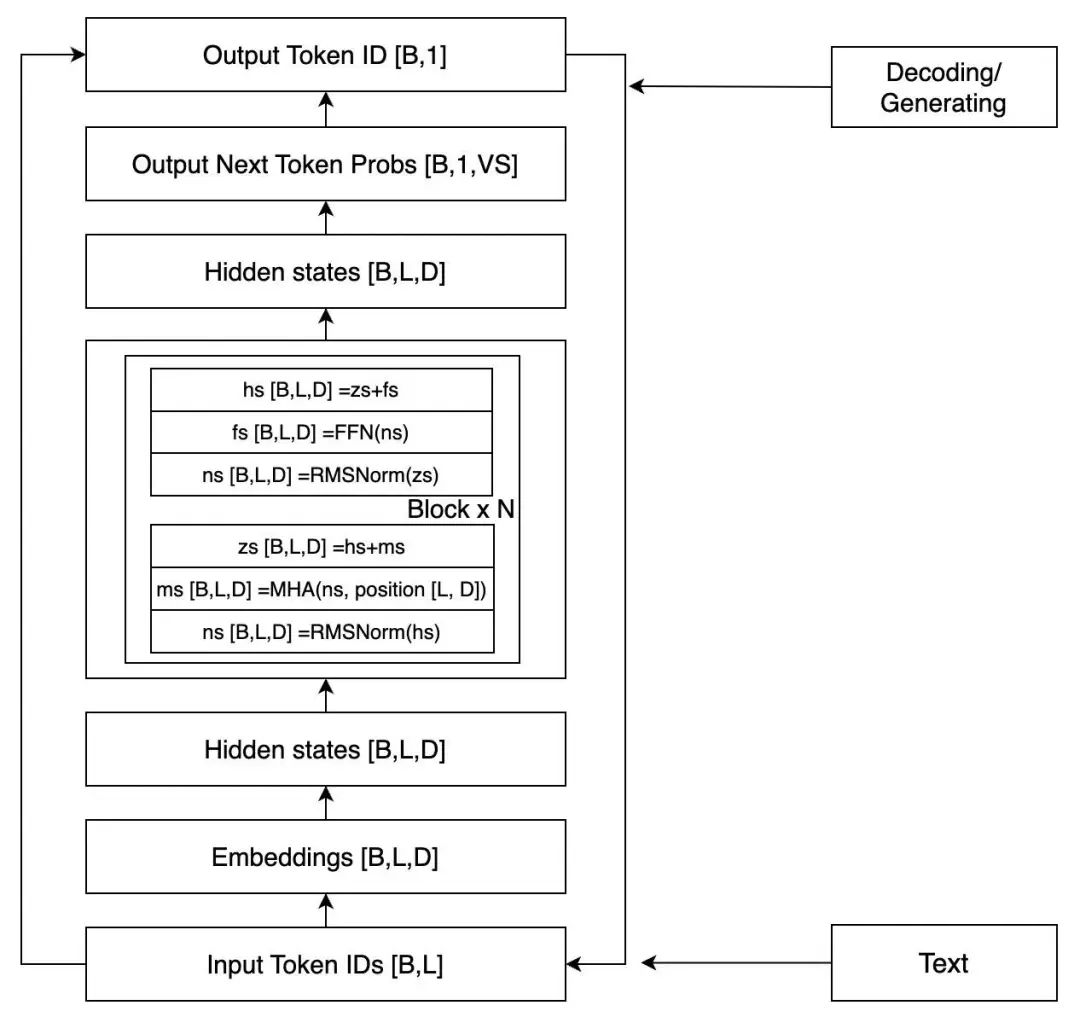
圖中 [] 中的是該位置的張量 shape,B 表示 Batch Size,一般時(shí)候都是批量丟給 GPU 計(jì)算的,L 就是 Sequence Length,D 就是上面提到的 Dim。這是一個(gè)簡化了的架構(gòu)圖,但是足以清晰地表達(dá)模型了。
兩個(gè) Hidden states(以下簡稱 HS),外面(之上和之下)的部分我們前面已經(jīng)提到過了(注意上面部分,[B,L,D] 會(huì)先變成 [B,L,VS],然后取最后一個(gè) Token 就得到了 [B,1,VS]),上面的 HS 會(huì)傳回到 Block 里面,重復(fù) N 次,N 就是模型的層數(shù)。接下來我們就把重點(diǎn)放在中間這個(gè) Block 里。
每個(gè) Block 包括兩個(gè)主要模塊,一個(gè) MHA(Multi-Head Attention)模塊,一個(gè) FFN(Feedforward Network)模塊,每次傳給模塊之前都需要 Normalization,這個(gè)叫 Pre-Normalization,一般用來穩(wěn)定訓(xùn)練。另外,每個(gè)模塊結(jié)束后會(huì)疊加模塊之前的輸入,這個(gè)叫殘差連接,一般能加速收斂。
接下來是 MHA 和 FFN,先看 FFN 模塊,它的大概流程如下(@ 表示矩陣/張量乘法)。
z1 = ns @ up_weights z2 = ns @ gate_weights z3 = z1 * silu(z2) z4 = z3 @ down_weights
整體來看是先將網(wǎng)絡(luò)擴(kuò)大再收縮,擴(kuò)大時(shí)增加了一個(gè)激活處理。silu 函數(shù)大概長這樣:
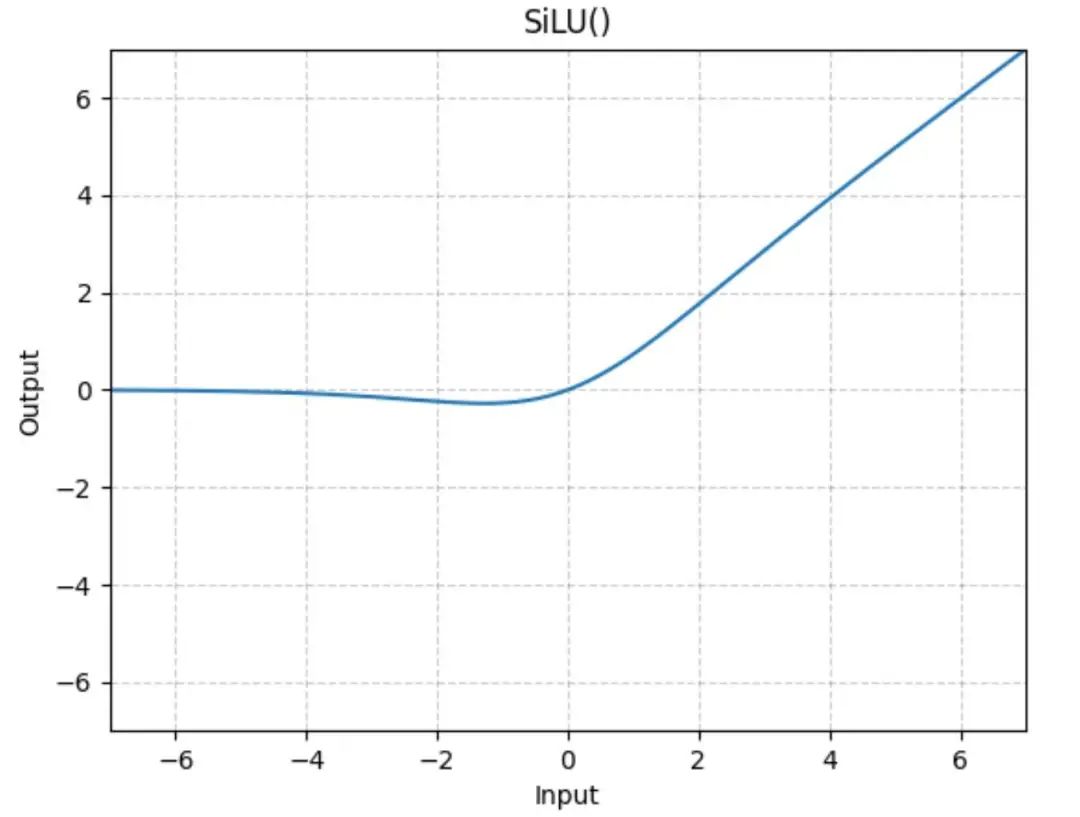
等價(jià)于只激活了一部分參數(shù),這個(gè)非線性激活非常重要,可以讓模型學(xué)習(xí)到更豐富的知識(shí)和表達(dá)。
再就是 MHA 模塊了,大概流程如下(為了更直觀,去掉了 Batch Size 和 Softmax)。
q = ns @ q_weights # (L, D) @ (D, D) = (L, D) k = ns @ k_weights # (L, D) @ (D, D) = (L, D) v = ns @ v_weights # (L, D) @ (D, D) = (L, D) q = q.reshape(L, NH, HD) k = k.reshape(L, NH, HD) v = v.reshpae(L, NH, HD) attn = q.trans(NH, L, HD) @ k.trans(NH, HD, L) # (NH, L, HD) @ (NH, HD, L) = (NH, L, L) v = attn @ v.trans(NH, L, HD) # (NH, L, L) @ (NH, L, HD) = (NH, L, HD) v = v.reshpe(L, NH*HD) # (L, D)
其中,NH 表示 Attention 的 Head 數(shù),HD 表示 Head 的維度。因?yàn)橛?NH 個(gè) Head,所以叫 Multi-Head,但其實(shí)我們看上面的過程,在實(shí)際計(jì)算的時(shí)候它們是合并一起算的。我們不妨只看一個(gè) Head,如下所示。
q = ns @ hq_weights # (L, D) @ (D, HD) = (L, HD) k = ns @ hk_weights # (L, D) @ (D, HD) = (L, HD) v = ns @ hv_weights # (L, D) @ (D, HD) = (L, HD) attn = q @ k.T # (L, HD) @ (HD, L) = (L, L) v = attn @ v # (L, L) @ (L, HD) = (L, HD)
上面的多個(gè) Head 的 v 就是下面的每個(gè) Head 的 v 拼接起來的。
Multi-Head 是多個(gè)注意力頭去執(zhí)行 Attention,其思想是讓每個(gè) Head 去捕獲不同角度/層面的 Attention,這些角度/層面是什么?不是特別清楚(但一定是某種特征),但我們可以通過 Attention 的權(quán)重看出外在 Token 級(jí)別的注意力,知道每個(gè)注意力 Head,哪些 Token 之間有比較強(qiáng)的連接。
參數(shù)
關(guān)于 f(x) 我們已經(jīng)介紹完了,可以發(fā)現(xiàn)這個(gè)函數(shù)其實(shí)還是有點(diǎn)復(fù)雜的。接下來,我們看看參數(shù)情況。
對(duì)一個(gè)一元一次方程(比如 f(x) = ax + b)來說,參數(shù)就兩個(gè):a 和 b,但對(duì)于 LLM 來說,參數(shù)就非常多了,目前常用的是 7B、13B、20B 的級(jí)別,也就是 70億、130億和 200億的參數(shù)規(guī)模。
在神經(jīng)網(wǎng)絡(luò)中,可以把矩陣乘法看作是多元一次方程組的計(jì)算過程,輸入的 Hidden State 維度是 D,就表示未知變量的維度是 D,也就是 D 元一次方程組。
以前面的但 Head Attention 的 q 為例,q_weights 是一個(gè) DxHD 的參數(shù)矩陣,我們把 D 和 HD 設(shè)置的小一點(diǎn)(假設(shè)為4和2),看一個(gè)具體的例子。
torch.manual_seed(42) w = nn.Linear(4, 2, bias=False) # D=4, HD=2 hs = torch.rand((3, 4)) # L=3, D=4 q = hs @ w.weight.T “”“ hq_weights = w.weight.T = tensor([[ 0.3823, -0.1096], [ 0.4150, 0.1009], [-0.1171, -0.2434], [ 0.4593, 0.2936]]) hs = tensor([[0.9408, 0.1332, 0.9346, 0.5936], [0.8694, 0.5677, 0.7411, 0.4294], [0.8854, 0.5739, 0.2666, 0.6274]]) q = tensor([[ 0.5781, -0.1428], [ 0.6784, -0.0923], [ 0.8336, 0.0803]]) ”“”
這個(gè)例子除了維度小一點(diǎn),其他邏輯是一樣的。它對(duì)應(yīng)這么一個(gè)多元方程組。
w11*x11 + w21*x12 + w31*x13 + w41*x14 = y11 w12*x11 + w22*x12 + w32*x13 + w42*x14 = y12 w11*x21 + w21*x22 + w31*x23 + w41*x24 = y21 w12*x21 + w22*x22 + w32*x23 + w42*x24 = y22 w11*x31 + w21*x32 + w31*x33 + w41*x34 = y31 w12*x31 + w22*x32 + w32*x33 + w42*x34 = y32
其中 x 就是 hs,w 就是 hq_weights,寫成數(shù)學(xué)表達(dá)式大概就是下面的這樣。 $$ left[egin{array}{llll} x_{11} & x_{12} & x_{13} & x_{14} x_{21} & x_{22} & x_{23} & x_{24} x_{31} & x_{32} & x_{33} & x_{34} end{array} ight] imesleft[egin{array}{ll} w_{11} & w_{12} w_{21} & w_{22} w_{31} & w_{32} w_{41} & w_{42} end{array} ight]=left[egin{array}{ll} y_{11} & y_{12} y_{21} & y_{22} y_{31} & y_{32} end{array} ight] $$ 對(duì)于這樣的一個(gè) Linear 來說,參數(shù)量就是 2×4=8 個(gè)。現(xiàn)在讓我們看看 LLaMA,就按詞表大小=32000,維度=4096來計(jì)算。
首先是 Embedding 和 LM Head(就是映射到 32000 個(gè) Token 的那個(gè)參數(shù)),它們是一樣的,都是 32000×4096,有時(shí)候這兩個(gè)地方的參數(shù)也可以設(shè)計(jì)成共享的,LM Head 前面也有一個(gè) Normalization,4096 個(gè)參數(shù)。
然后是 Block,MHA 的 qkvo 是 4 個(gè) 4096×4096 的矩陣,F(xiàn)FN 的 gate、up、down 是 11008×4096 的矩陣,再加上兩個(gè) Normalization, 4096×2 個(gè)參數(shù)。每個(gè) Block 參數(shù)量為 4096×(4096×4+11008×3+2)。
這樣得到所有的參數(shù)總和為:32000*4096*2 + 4096 +(4096*(4096*4+11008*3+2))*32 = 6738415616,67億多的樣子,也就是常說的 7B。
Rust與LLaMA
終于來到了 Rust,之所以前面鋪墊那么多,是因?yàn)槿绻覀兺耆皇煜つP偷幕窘Y(jié)構(gòu)和執(zhí)行過程,這個(gè)代碼看起來就會(huì)知其然而不知其所以然。當(dāng)然,即便了解了基本結(jié)構(gòu),里面也有一些細(xì)節(jié)需要單獨(dú)介紹,不過我們會(huì)放在后續(xù)的內(nèi)容。
只看上面的內(nèi)容,我們可以發(fā)現(xiàn) LLM 模型的結(jié)構(gòu)其實(shí)不算特別復(fù)雜,而且其中涉及到大量的矩陣運(yùn)算(至少占到 80% 以上)。關(guān)于矩陣運(yùn)算以及相關(guān)的優(yōu)化,我們也會(huì)在后面慢慢涉及。
LLaMA 的 Rust 實(shí)現(xiàn)有很多個(gè)版本,本次選擇的是來自 karpathy/llama2.c: Inference Llama 2 in one file of pure C 的 Rust 實(shí)現(xiàn)的版本中的:danielgrittner/llama2-rs: LLaMA2 + Rust,而且我們暫時(shí)只會(huì)涉及模型基礎(chǔ)結(jié)構(gòu)部分,其中涉及一些特別的細(xì)節(jié)會(huì)簡單解釋,不深入展開。
配置
首先是配置,如下所示。
struct Config { dim: usize, // transformer dimension hidden_dim: usize, // for ffn layers n_layers: usize, // number of layers n_heads: usize, // number of query heads head_size: usize, // size of each head (dim / n_heads) n_kv_heads: usize, // number of key/value heads shared_weights: bool, vocab_size: usize, // vocabulary size seq_len: usize, // max. sequence length }
dim 就是上面一直說的 Dim,hidden_dim 僅在 FFN 層,因?yàn)?FFN 層需要先擴(kuò)大再縮小。n_heads 和 n_kv_heads 是 Query 的 Head 數(shù)和 KV 的 Head 數(shù),簡單起見可以認(rèn)為它們是相等的。如果我們加載 karpathy 的 15M 的模型,結(jié)果如下。
Config { dim: 288, hidden_dim: 768, n_layers: 6, n_heads: 6, head_size: 48, n_kv_heads: 6, shared_weights: true, vocab_size: 32000, seq_len: 256 }
shared_weights 就是上面提到的 Embedding 和 LM Head 是否共享參數(shù)。
Tokenizer 的功能我們暫且略過,目前只需知道它負(fù)責(zé)將文本轉(zhuǎn)為 ID 列表(encode)以及把 ID 列表轉(zhuǎn)為文本(decode)。
參數(shù)
接下來看模型參數(shù),如下所示。
struct TransformerWeights { // Token Embedding Table token_embedding_table: Vec《f32》, // (vocab_size, dim) // Weights for RMSNorm rms_att_weight: Vec《f32》, // (layer, dim) rms_ffn_weight: Vec《f32》, // (layer, dim) // Weights for matmuls in attn wq: Vec《f32》, // (layer, dim, dim) wk: Vec《f32》, // (layer, dim, dim) wv: Vec《f32》, // (layer, dim, dim) wo: Vec《f32》, // (layer, dim, dim) // Weights for ffn w1: Vec《f32》, // (layer, hidden_dim, dim) w2: Vec《f32》, // (layer, dim, hidden_dim) w3: Vec《f32》, // (layer, hidden_dim, dim) // final RMSNorm rms_final_weights: Vec《f32》, // (dim) // freq_cis for RoPE relatively positional embeddings freq_cis_real: Vec《f32》, // (seq_len, head_size/2) freq_cis_imag: Vec《f32》, // (seq_len, head_size/2) // (optional) classifier weights for the logits, on the last layer wcls: Vec《f32》, // (vocab_size, dim) }
上面的參數(shù)應(yīng)該都比較直觀,我們不太熟悉的應(yīng)該是 freq_ 開頭的兩個(gè)參數(shù),它們是和位置編碼有關(guān)的參數(shù),也就是說,我們每次生成一個(gè) Token 時(shí),都需要傳入當(dāng)前位置的位置信息。
位置編碼在 Transformer 中是比較重要的,因?yàn)?Self Attention 本質(zhì)上是無序的,而語言的先后順序在有些時(shí)候是很重要的,比如 “我喜歡你” 和 “你喜歡我”,“你” 和 “我” 的順序不同,語義也不同。但時(shí)候很多語義又不太響影我們解理語義,不妨再仔細(xì)讀一下剛剛這半句話。你看文本順序雖然變了,但你讀起來毫無障礙。這也是為什么會(huì)有研究說不要位置編碼語言模型也可以,但效果應(yīng)該是不如加了位置編碼的。
模型創(chuàng)建好后,接下來就是加載參數(shù)和執(zhí)行推理。加載參數(shù)要看模型文件的格式設(shè)計(jì),本項(xiàng)目來自 karpathy 的 C 代碼,模型文件被安排成了 bin 文件,按規(guī)定的格式讀取即可,核心代碼如下。
fn byte_chunk_to_vec《T》(byte_chunk: &[u8], number_elements: usize) -》 Vec《T》 where T: Clone, { unsafe { // 獲取起始位置的原始指針 let data = byte_chunk.as_ptr() as *const T; // 從原始指針創(chuàng)建一個(gè) T 類型的切片,注意number_elements是element的數(shù)量,而不是bytes // 這句是 unsafe 的 let slice_data: &[T] = std::from_raw_parts(data, number_elements); // 將切片轉(zhuǎn)為 Vec,需要 T 可以 Clone slice_data.to_vec() } }
byte_chunk 表示原始的字節(jié)切片,number_elements 表示結(jié)果向量中元素的個(gè)數(shù),T 有 Clone 的 Trait 約束,表示 T 必須實(shí)現(xiàn)該 Trait,也就是 T 必須能夠使用 Clone 方法。其他解釋已經(jīng)在代碼中給出了注釋,不再贅述。
加載模型就是讀取原始的 bin 文件并指定對(duì)應(yīng)的參數(shù)大小,我們以 Token Embedding 參數(shù)為例,如下所示。
let token_embedding_table_size = config.vocab_size * config.dim; // offset.。 表示從 offset 往后的所有元素 let token_embedding_table: Vec《f32》 = byte_chunk_to_vec(&mmap[offset.。], token_embedding_table_size);
類似這樣就可以依次把模型參數(shù)讀取進(jìn)來了。
模型
接下來就是最復(fù)雜的模型部分了。這里最大的不同是 Token by Token 的處理,而不是給定一個(gè)上下文生成下一個(gè) Token。我們看一下基本的 Struct,如下所示。
struct LLaMA2《‘a(chǎn)》 { // buffers for current activations x: Vec《f32》, // activation at current timestep (dim,) xb: Vec《f32》, // same, but inside a residual branch (dim,) xb2: Vec《f32》, // additional buffer (dim,) hb: Vec《f32》, // buffer for hidden dimension in the ffn (hidden_dim,) hb2: Vec《f32》, // buffer for hidden dimension in the ffn (hidden_dim,) q: Vec《f32》, // query (dim,) k: Vec《f32》, // key (dim,) v: Vec《f32》, // value (dim,) att: Vec《f32》, // attention scores (n_heads, seq_len) logits: Vec《f32》, // output logits (vocab_size,) // kv cache key_cache: Vec《f32》, // (layer, seq_len, dim) value_cache: Vec《f32》, // (layer, seq_len, dim) // weights & config transformer: &’a TransformerWeights, config: &‘a(chǎn) Config, }
最后兩個(gè)參數(shù)我們上面已經(jīng)介紹過了,其他參數(shù)都是模型推理過程中需要用到的中間結(jié)果和最初的輸入,以及最終的結(jié)果,它們均被初始化成 0。至于為什么有些值是多個(gè)(比如 xb、hb等),是因?yàn)?Block 里面涉及到殘差連接,需要額外保存一個(gè)輸入。
現(xiàn)在我們從 forward 開始,方法如下。
fn forward(&mut self, token: usize, pos: usize) { // fetch the token embedding self.x.copy_from_slice( &self.transformer.token_embedding_table [(token * self.config.dim)。.((token + 1) * self.config.dim)], ); // Note: here it always holds that seqlen == 1 in comparison to the PyTorch implementation for l in 0..self.config.n_layers { self.layer(l, pos); } // final RMSNorm rmsnorm( self.x.as_mut_slice(), self.transformer.rms_final_weights.as_slice(), ); // generate logits, i.e., map activations from dim to vocab_size matmul( self.logits.as_mut_slice(), // out: (vocab_size,) self.transformer.wcls.as_slice(), // W: (vocab_size, dim) self.x.as_slice(), // x: (dim,) ); }
這塊代碼是推理的全流程,一共四個(gè)步驟:取 Embedding、逐層計(jì)算、Normalization、映射到詞表大小的 logits(后續(xù)會(huì)基于此轉(zhuǎn)為概率分布)。
Embedding 是直接從參數(shù)里 copy 出對(duì)應(yīng)索引的參數(shù),無序贅述。
Normalization 用的是 RMS(Root Mean Square)Normalization,基本公式如下。 $$ x’i = frac{x_i} {sqrt{sum{i=1}^N x_i}} * w_i $$ 它是標(biāo)準(zhǔn) Normalization 的簡單形式,但效果尚可,其代碼如下。
fn rmsnorm(x: &mut [f32], weight: &[f32]) { let size = x.len(); let squared_sum = x.iter().fold(0.0, |acc, x| acc + x * x); let rms = 1. / (squared_sum / size as f32).sqrt(); x.iter_mut() .zip(weight.iter()) .for_each(|(x, w)| *x *= rms * w); }
代碼一目了然,先一個(gè) reduce,然后開方取倒數(shù),接著就是遍歷計(jì)算更新每個(gè)參數(shù)值。
最后的矩陣乘法比較標(biāo)準(zhǔn),輸入的 Hidden State(x)因?yàn)橹挥幸粋€(gè) Token,所以可以看成向量,長度為 Dim,與 LM Head 矩陣乘法后就得到一個(gè)詞表大小的輸出值,后續(xù)可以歸一化成概率值(即概率分布)。矩陣乘法代碼如下(準(zhǔn)確來說是向量和矩陣乘法)。
fn matmul(target: &mut [f32], w: &[f32], x: &[f32]) { let in_dim = x.len(); target.par_iter_mut().enumerate().for_each(|(i, t)| { let row_offset = i * in_dim; *t = x .iter() .zip(w[row_offset.。].iter()) .fold(0.0, |result, (x, w)| result + x * w); }); }
這里需要注意的是 offset,因?yàn)閰?shù)是一個(gè) Vec 存儲(chǔ)的一維數(shù)組,要按二維取值,需要每次跳過對(duì)應(yīng)數(shù)量的參數(shù)。剩下的就很清晰了,最終的結(jié)果會(huì)存儲(chǔ)到 target,也就是 self.logits,進(jìn)而會(huì)轉(zhuǎn)為概率分布。
我們把重心放在中間的逐層計(jì)算上,LLM 的核心也在這里。先看 layer 的代碼,如下所示。
fn layer(&mut self, layer: usize, pos: usize) { // Note: we leave the buffer x as it is because we need it for the residual connection rmsnorm_with_dest( self.xb.as_mut_slice(), self.x.as_slice(), &self.transformer.rms_att_weight [layer * self.config.dim.。(layer + 1) * self.config.dim], ); self.attn(layer, pos); // residual connection add_vectors(self.x.as_mut_slice(), self.xb2.as_slice()); // Note: we leave the buffer x as it is because we need it for the residual connection rmsnorm_with_dest( self.xb.as_mut_slice(), self.x.as_slice(), &self.transformer.rms_ffn_weight [layer * self.config.dim.。(layer + 1) * self.config.dim], ); self.ffn(layer); // residual connection add_vectors(self.x.as_mut_slice(), self.xb.as_slice()); }
非常標(biāo)準(zhǔn)的流程(可回看前面的架構(gòu)圖),先歸一化,然后 MHA,殘差連接,再歸一化,F(xiàn)FN,殘差連接。歸一化的代碼剛剛已經(jīng)看過了,這里唯一的不同是將輸出放到第一個(gè)參數(shù)(即 self.xb)里。add_vectors 就是對(duì)應(yīng)元素值求和,結(jié)果放到第一個(gè)參數(shù),這個(gè)比較簡單,我們就不放代碼了。重點(diǎn)就是 ffn 和 attn,它們內(nèi)部涉及大量矩陣乘法,我們開始。
先看 ffn,它比較簡單,主要是幾個(gè)矩陣乘法加非線性激活,代碼如下。
fn ffn(&mut self, layer: usize) { let weight_from = layer * self.config.hidden_dim * self.config.dim; let weight_to = (layer + 1) * self.config.hidden_dim * self.config.dim; // gate z2 matmul( self.hb.as_mut_slice(), // out: (hidden_dim,) &self.transformer.w1[weight_from..weight_to], // W: (hidden_dim, dim) self.xb.as_slice(), // x: (dim,) ); // up z1 matmul( self.hb2.as_mut_slice(), // out: (hidden_dim,) &self.transformer.w3[weight_from..weight_to], // W: (hidden_dim, dim) self.xb.as_slice(), // x: (dim,) ); // z3 for i in 0..self.config.hidden_dim { self.hb[i] = silu(self.hb[i]) * self.hb2[i]; } // down z4 matmul( self.xb.as_mut_slice(), // out: (hidden_dim,) &self.transformer.w2[weight_from..weight_to], // W: (hidden_dim, dim) self.hb.as_slice(), // x: (dim,) ); }
這個(gè)過程和我們《開源代表——LLaMA 結(jié)構(gòu)》一節(jié)中是一一對(duì)應(yīng)的,涉及到的主要是剛剛介紹過的 matmul 和一個(gè) silu,后者我們之前看過它的圖像,代碼如下。
fn silu(x: f32) -》 f32 { x / (1.0 + (-x).exp()) }
表達(dá)式如下所示。 $$ ext{SiLU}(x) = frac{x}{1 + e^{-x}} $$ 好了,最后我們把重心放在 attn 這個(gè)方法上,由于逐 Token 生成時(shí),Query 是當(dāng)前 Token,這沒問題,但 Key 和 Value(Attention 里面的 K和V)是需要?dú)v史 Token 的(不然怎么算注意力)。常見的做法就是把歷史過程中的 K 和 V 緩存起來,每次生成時(shí)順便更新緩存,這樣下次生成時(shí)拿到的就是之前的所有 K 和 V。
先看一下基本的代碼流程,如下所示。
fn attn(&mut self, layer: usize, pos: usize) { // qkv matmuls self.attn_qkv_matmuls(layer); // apply RoPE rotation to the q and k vectors for each head self.attn_rope(layer, pos); // Multi-head attention with caching self.cache_kv(layer, pos); self.multihead_attn(layer, pos); // wo let weight_from = layer * self.config.dim * self.config.dim; let weight_to = (layer + 1) * self.config.dim * self.config.dim; matmul( self.xb2.as_mut_slice(), // out: (dim,) &self.transformer.wo[weight_from..weight_to], // W: (dim, dim) self.xb.as_slice(), // x: (dim,) ); }
最后的 wo 比較簡單,不再贅述。一開始的 qkv 也比較簡單,都是矩陣乘法,如下所示。
fn attn_qkv_matmuls(&mut self, layer: usize) { let weight_from = layer * self.config.dim * self.config.dim; let weight_to = (layer + 1) * self.config.dim * self.config.dim; matmul( self.q.as_mut_slice(), // out: (dim,) &self.transformer.wq[weight_from..weight_to], // W: (dim, dim) self.xb.as_slice(), // x: (dim,) ); matmul( self.k.as_mut_slice(), // out: (dim,) &self.transformer.wk[weight_from..weight_to], // W: (dim, dim) self.xb.as_slice(), // x: (dim,) ); matmul( self.v.as_mut_slice(), // out: (dim,) &self.transformer.wv[weight_from..weight_to], // W: (dim, dim) self.xb.as_slice(), // x: (dim,) ); }
還剩下三個(gè)方法:attn_rope、cache_kv 和 multihead_attn,我們分別看一下。
第一個(gè)用來加入位置信息,參數(shù)是一開始算好的,這里直接取出對(duì)應(yīng)位置的值進(jìn)行計(jì)算。代碼如下所示。
fn attn_rope(&mut self, layer: usize, pos: usize) { // apply RoPE rotation to the q and k vectors for each head let freq_cis_real_offset = pos * self.config.head_size / 2; let freq_cis_imag_offset = pos * self.config.head_size / 2; for i in (0..self.config.dim).step_by(2) { let q0 = self.q[i]; let q1 = self.q[i + 1]; let k0 = self.k[i]; let k1 = self.k[i + 1]; let cos = self.transformer.freq_cis_real [freq_cis_real_offset + (i % self.config.head_size) / 2]; let sin = self.transformer.freq_cis_imag [freq_cis_imag_offset + (i % self.config.head_size) / 2]; self.q[i] = q0 * cos - q1 * sin; self.q[i + 1] = q1 * cos + q0 * sin; self.k[i] = k0 * cos - k1 * sin; self.k[i + 1] = k1 * cos + k0 * sin; } }
這部分代碼就是把位置信息注入到 Q 和 K 中,其理論分析比較復(fù)雜,此處不展開。
cache_kv 比較簡單,直接把當(dāng)前的 K 和 V 存起來即可,如下所示。
fn cache_kv(&mut self, layer: usize, pos: usize) { // cache the key, value for the current timestep (pos) let layer_offset = layer * self.config.seq_len * self.config.dim; // offset to get to the cache of the current layer let cache_from = layer_offset + pos * self.config.dim; let cache_to = layer_offset + (pos + 1) * self.config.dim; self.key_cache[cache_from..cache_to].copy_from_slice(&self.k.as_slice()); self.value_cache[cache_from..cache_to].copy_from_slice(&self.v.as_slice()); }
因?yàn)槲覀儾淮_定用戶生成的 Token 長度,所以就把最大長度(seq_len)的所有位置都占上,因?yàn)槭前磳哟娴模恳粚佣加杏?jì)算,所以需要層的 ID。每一層、每個(gè)位置都緩存 dim 個(gè)中間結(jié)果。
最后就是最重要的 multihead_attn 了,這里面的主要邏輯是計(jì)算 attention 分?jǐn)?shù),然后得到 attention 之后的結(jié)果,代碼如下。
fn multihead_attn(&mut self, layer: usize, pos: usize) { // offset to get to the cache of the current layer let layer_offset_for_cache = layer * self.config.seq_len * self.config.dim; // 縮放因子 let sqrt_d = (self.config.head_size as f32).sqrt(); // att 和 xb 分別按指定大小切塊 // attn_scores每一塊是seq_len長度,共n_head(NH)塊,即按 head 處理 // xb每一塊是head_size長度,共n_head(NH)塊 self.att.par_chunks_exact_mut(self.config.seq_len) .zip(self.xb.par_chunks_exact_mut(self.config.head_size)) .enumerate() .for_each(|(h, (attn_scores, xb))| { assert_eq!(attn_scores.len(), self.config.seq_len); assert_eq!(xb.len(), self.config.head_size); // get query vector of the timestep pos for the current head // 第h個(gè)head,Q是當(dāng)前Token,(1, HD) let q_from = h * self.config.head_size; let q_to = (h + 1) * self.config.head_size; let q = &self.q[q_from..q_to]; // Compute temp = (K * q_pos) / sqrt(dim) // K和V是要包含歷史Token,(L, HD) // q @ k.T 得到的是 (1,HD)@(HD,L)=(1, L) 大小的 attention score // 這里循環(huán)L(pos)次,所以每一個(gè)位置的值是 (1,HD)@(HD,1)=(1,1),即點(diǎn)積 for t in 0.。=pos { // key_cache[l, t] let timestep_and_layer_offset = layer_offset_for_cache + t * self.config.dim; // for the current key, select the correct range which corresponds to the current head let key_vector_from = timestep_and_layer_offset + h * self.config.head_size; let key_vector_to = timestep_and_layer_offset + (h + 1) * self.config.head_size; let key_vector = &self.key_cache[key_vector_from..key_vector_to]; attn_scores[t] = inner_product(q, key_vector) / sqrt_d; } // softmax the scores to get attention weights, from 0..pos inclusively // 歸一化得到概率 softmax(&mut attn_scores[。.(pos + 1)]); // Compute temp2^T * V // 計(jì)算加權(quán)的v // attention是 (1,L),V是(L,HD),每個(gè)HD的權(quán)重是attention[i] xb.fill(0.0); for t in 0.。=pos { // value_cache[l, t] let timestep_and_layer_offset = layer_offset_for_cache + t * self.config.dim; // for the current value, select the correct range which corresponds to the current head let value_vector_from = timestep_and_layer_offset + h * self.config.head_size; let value_vector_to = timestep_and_layer_offset + (h + 1) * self.config.head_size; let value_vector = &self.value_cache[value_vector_from..value_vector_to]; // weighted sum with attention scores as weights let attention_weight = attn_scores[t]; for i in 0..self.config.head_size { xb[i] += attention_weight * value_vector[i]; } } }); }
上面的過程是分 Head 計(jì)算的,需要我們深刻理解前面《開源代表——LLaMA 結(jié)構(gòu)》一小節(jié)的內(nèi)容,具體解釋可以參考代碼里的注釋。值得一提的是,分 Head 計(jì)算是并行的。
另外,有個(gè)新方法 inner_product 是點(diǎn)積,也就是對(duì)應(yīng)元素相乘后求和,代碼如下。
fn inner_product(x: &[f32], y: &[f32]) -》 f32 { zip(x, y).fold(0.0, |acc, (a, b)| acc + a * b) }
比較簡單,不再贅述。
生成
最后就是生成(或 Decoding)過程。代碼略有不同,我們先看下。
fn generate(&mut self, prompt_tokens: &Vec《usize》, n_tokens: usize, temperature: f32) -》 Vec《usize》 { let mut tokens = vec![]; tokens.reserve(n_tokens); let mut token = BOS_TOKEN; tokens.push(token); // forward through the prompt to fill up the KV-cache! for (pos, prompt_token) in prompt_tokens.iter().enumerate() { self.forward(token, pos); token = *prompt_token; tokens.push(token); } // complete the prompt for pos in prompt_tokens.len()。.(n_tokens - 1) { self.forward(token, pos); if temperature == 0.0 { token = argmax(self.logits.as_slice()); } else { // Apply temperature and then sample. self.logits.iter_mut().for_each(|p| *p = *p / temperature); softmax(&mut self.logits.as_mut_slice()); token = sample(self.logits.as_slice()); } tokens.push(token); } tokens }
這里有兩個(gè)值得注意的地方。
第一個(gè)是推理 Prompt(即第一次輸入時(shí)的 Context),此時(shí)給定的 Context 是多個(gè) Token 組成的,執(zhí)行該過程目的是填充 KV Cache。
第二個(gè)是采樣過程,temperature=0.0 時(shí),就是 Greedy Search,每次返回概率最大位置的 Token;否則,會(huì)先應(yīng)用 temperature,然后按照概率分布進(jìn)行采樣。temperature 參數(shù)會(huì)平滑概率分布,值越大,平滑力度越大,更有可能生成多樣的結(jié)果。softmax 用來把一系列值歸一化成概率分布(所有值加起來和為 1.0)。我們重點(diǎn)看看這個(gè) sample 方法,它的主要思想是根據(jù)概率分布進(jìn)行采樣,也就是高概率的位置更容易被采樣到,低概率的位置更不容易被采樣到。代碼如下。
fn sample(probs: &[f32]) -》 usize { let mut rng = rand::thread_rng(); let mut cdf = 0.0; let r = rng.gen_range(0.0..1.0); for (i, p) in probs.iter().enumerate() { cdf += p; if cdf 》 r { return i; } } probs.len() - 1 }
隨機(jī)生成 0-1 之間的一個(gè)值(均勻分布),計(jì)算累積概率,當(dāng)累積概率大于剛剛生成的值時(shí),返回此時(shí)的位置。這樣就可以保證是按照概率分布進(jìn)行采樣的。我們舉個(gè)具體的例子,如下所示。
// 假設(shè)概率分布為 probs = [0.1, 0.2, 0.1, 0.5, 0.1] // 累積概率為 accu_probs = [0.1, 0.3, 0.4, 0.9, 1.0]
假設(shè)隨機(jī)值為 r,因?yàn)樗蔷鶆蚍植嫉模月湓诓煌瑓^(qū)間的概率與該區(qū)間的長度成正比。我們看上面的累積概率,可以得出如下結(jié)果。
r落在區(qū)間返回 Index
[0, 0.1)0
[0.1, 0.3)1
[0.3, 0.4)2
[0.4, 0.9)3
[0.9, 1.0)4
也就是說返回 Index=3 的概率為 0.5,其他同理。
拿到 Token 向量后只要用 Tokenizer 解碼即可得到生成的文本。
小結(jié)
本文我們首先簡單介紹了 LLM 相關(guān)的背景,著重討論了關(guān)于 Token 和生成過程,這是應(yīng)用 LLM 時(shí)非常重要的兩個(gè)知識(shí)點(diǎn)。然后我們介紹了開源 LLM 的代表——LLaMA 的模型結(jié)構(gòu)和參數(shù),給大家一個(gè)整體的感知和認(rèn)識(shí)。最后就是 Rust 的實(shí)現(xiàn),主要包括配置、參數(shù)、模型和生成四個(gè)方面,其中最重要的就是模型部分,模型部分最重要、也最難理解的是 Multi-Head Attention 的計(jì)算。主要是因?yàn)榫唧w的計(jì)算過程都是把矩陣運(yùn)算給展開了,這需要對(duì)模型有一定程度的理解。
這種展開的寫法其實(shí)是比較底層的實(shí)現(xiàn),如果能在上面抽象一層,直接操縱矩陣或張量,那計(jì)算起來應(yīng)該會(huì)簡單很多。事實(shí)上,大部分框架都是這么做的,比如 Python 的 NumPy 、PyTorch等,當(dāng)然 Rust 也有類似的框架,比如 NumPy 對(duì)應(yīng)的 ndarray,以及 Rust 版本的深度學(xué)習(xí)框架。使用這些框架時(shí),我們使用的是矩陣/張量(或者叫多維數(shù)組)這個(gè)對(duì)象,所有的操作也都在這個(gè)粒度進(jìn)行,這無疑極大地提高了編程效率。同時(shí),還可以利用這些框架底層的性能優(yōu)化。
不過,有時(shí)候當(dāng)我們需要框架暫未支持的更細(xì)致的優(yōu)化、或在一個(gè)框架不支持的設(shè)備上運(yùn)行時(shí),這種 Pure X(此處為 Rust)的方式就比較方便靈活了。
總的來說,算法是多樣的,實(shí)現(xiàn)更是多樣的,優(yōu)化更更是無止境的,吾輩唯有不斷前行,持續(xù)向上。
審核編輯:黃飛































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論