 電子發(fā)燒友App
電子發(fā)燒友App


近日,字節(jié)跳動(dòng)聯(lián)合北京大學(xué)的研究團(tuán)隊(duì)發(fā)表了一篇論文《將大型語言模型訓(xùn)練擴(kuò)展至超過10,000塊GPU》,提出一個(gè)用于訓(xùn)練大語言模型的生產(chǎn)系統(tǒng),解決在萬卡集群上訓(xùn)練大模型時(shí)面臨的效率和穩(wěn)定性挑戰(zhàn)。
該論文介紹了系統(tǒng)的設(shè)計(jì)、實(shí)現(xiàn)和部署。此外,文中還提到了萬卡以上的集群規(guī)模遇到的問題及其解決方案。
01、萬卡集群的兩大挑戰(zhàn)
大模型時(shí)代,算力就是生產(chǎn)力。大模型的背后意味著巨大的計(jì)算資源,模型大小和訓(xùn)練數(shù)據(jù)大小是決定模型能力的關(guān)鍵因素。市場(chǎng)的主力玩家們利用數(shù)萬個(gè)GPU構(gòu)建大型人工智能集群,以訓(xùn)練LLM。但當(dāng)GPU集群達(dá)到萬卡規(guī)模,如何實(shí)現(xiàn)高效率、高穩(wěn)定的訓(xùn)練?
第一個(gè)挑戰(zhàn)是實(shí)現(xiàn)大規(guī)模的高效率訓(xùn)練。模型浮點(diǎn)運(yùn)算利用率 (MFU)是實(shí)際吞吐量與假設(shè)最大吞吐量之比,是評(píng)估模型訓(xùn)練效率的通用指標(biāo),可以直接反映端到端的訓(xùn)練速度。為了訓(xùn)練LLM,需要將模型分布為多個(gè)GPU上,并且GPU之間需進(jìn)行大量通信以推動(dòng)進(jìn)展。除了通信之外,如操作符優(yōu)化、數(shù)據(jù)預(yù)處理和GPU內(nèi)存消耗等因素對(duì)MFU也有著顯著影響。
第二個(gè)挑戰(zhàn)是在大規(guī)模上實(shí)現(xiàn)訓(xùn)練的高穩(wěn)定性,即在整個(gè)過程中保持高效率訓(xùn)練。在大模型訓(xùn)練中,穩(wěn)定性十分重要。失敗和延遲雖是大模型訓(xùn)練中的常態(tài),但其故障成本非常高。如何縮短故障恢復(fù)時(shí)間至關(guān)重要,一個(gè)掉隊(duì)者不僅會(huì)影響自己的工作,還會(huì)拖慢數(shù)萬個(gè)GPU的整個(gè)作業(yè)。
為了應(yīng)對(duì)這些挑戰(zhàn),字節(jié)跳動(dòng)提出MegaScale(超大規(guī)模)系統(tǒng),并已部署在自家的數(shù)據(jù)中心。那么字節(jié)是如何解決上述問題的呢?
02、如何實(shí)現(xiàn)大模型的高效訓(xùn)練?
想要在不損害模型準(zhǔn)確性的情況下處理急劇增加的計(jì)算需求,需要采用最先進(jìn)的算法優(yōu)化、通信策略、數(shù)據(jù)流水線管理以及網(wǎng)絡(luò)性能調(diào)優(yōu)技術(shù)。下文深入探討了用于優(yōu)化大型模型訓(xùn)練的方法,以實(shí)現(xiàn)大規(guī)模的高效率訓(xùn)練。
算法優(yōu)化
在算法層面進(jìn)行了一些優(yōu)化,在不影響準(zhǔn)確性的前提下,提高訓(xùn)練效率。主要包括并行transformer塊、滑動(dòng)窗口注意力(SWA)和LAMB優(yōu)化器。
并行transformer塊:采用transformer塊的并行版本,代替標(biāo)準(zhǔn)的序列化公式。這種方法使得注意力塊和MLP塊的計(jì)算可以并行執(zhí)行,從而減少了計(jì)算時(shí)間。先前的研究表明,這種修改不會(huì)降低具有數(shù)千億參數(shù)的模型的質(zhì)量。
滑動(dòng)窗口注意力(SWA)是一種稀疏注意力機(jī)制,它在輸入序列中的每個(gè)標(biāo)記周圍使用固定大小的窗口,比全自注意力更高效。通過堆疊此類窗口注意力層,模型能夠有效地捕獲輸入數(shù)據(jù)中廣泛的上下文信息,同時(shí)創(chuàng)建大感受野,從而在不影響準(zhǔn)確性的情況下加快訓(xùn)練速度。
LAMB優(yōu)化器:大規(guī)模的高效訓(xùn)練通常受到批量大小限制的阻礙。特別是,增加批量大小可能會(huì)對(duì)模型收斂產(chǎn)生不利影響。LAMB優(yōu)化器能夠使BERT的訓(xùn)練批量大小擴(kuò)展到64K,而不影響準(zhǔn)確性。
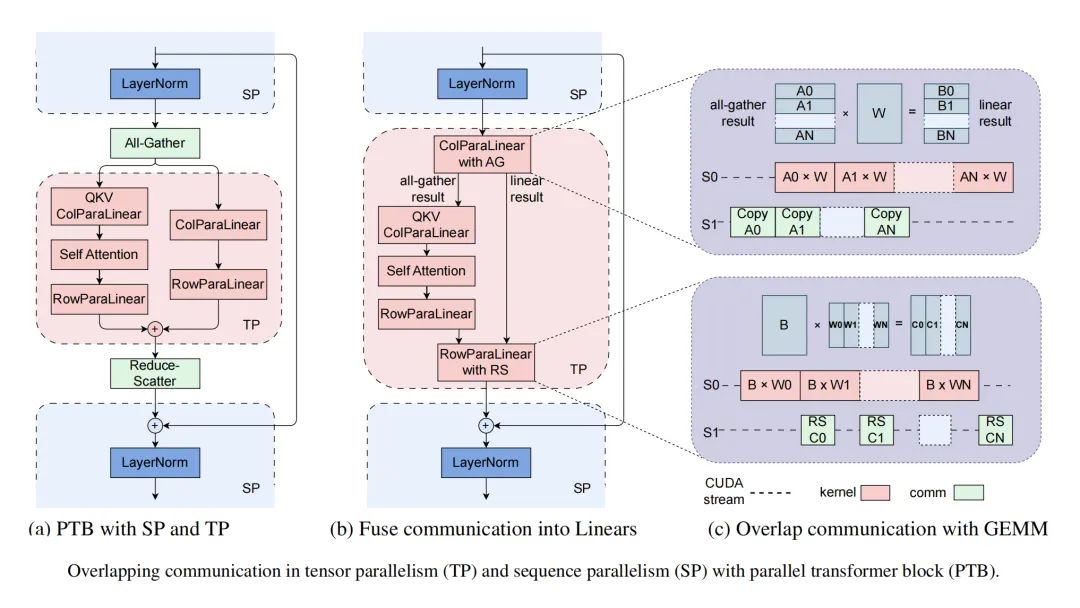
3D并行中的通信重疊
3D并行指張量并行、流水線并行和數(shù)據(jù)并行。
在數(shù)據(jù)并行中有兩個(gè)主要通信操作:all-gather操作和reduce-scatter操作。在3D并行中,單個(gè)設(shè)備可能承載多個(gè)模型塊。重疊是基于模型塊實(shí)現(xiàn)的,以最大化帶寬利用。all-gather操作在模型塊的前向傳遞之前觸發(fā),reduce-scatter操作在它的后向傳遞之后開始。這導(dǎo)致第一個(gè)all-gather操作和最后一個(gè)reduce-scatter操作無法隱藏。受到PyTorch FSDP的啟發(fā),初始的all-gather操作在每次迭代的開始時(shí)被預(yù)取,允許它與數(shù)據(jù)加載操作重疊,有效地將減少了通信時(shí)間。
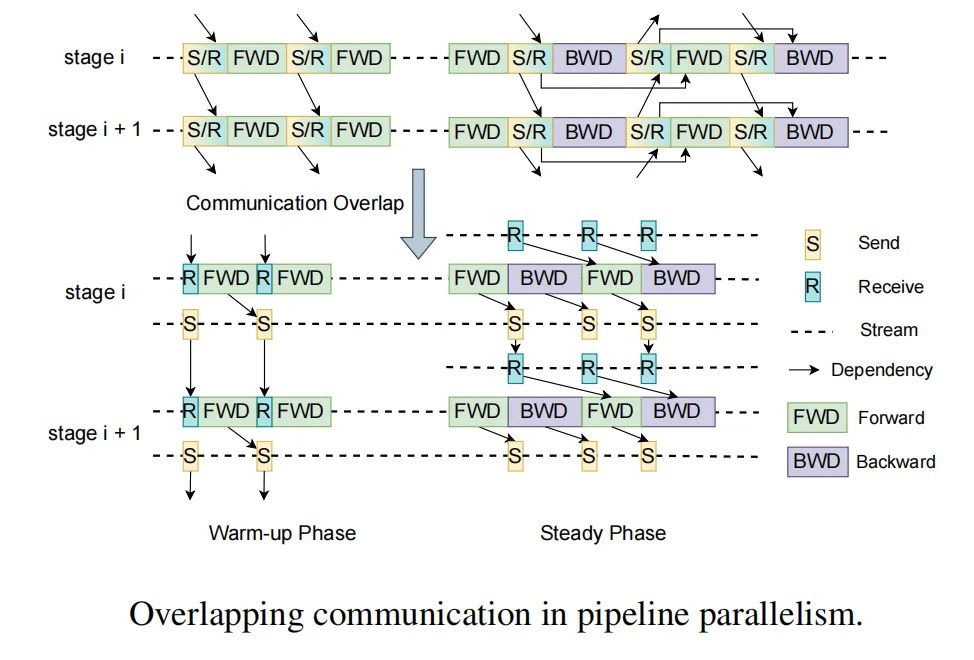
在流水線并行中,MegaScale使用交錯(cuò)1F1B調(diào)度方法,以實(shí)現(xiàn)通信的重疊。在熱身階段,前向傳遞僅依賴于其先前的接收。我們解耦了通常一起實(shí)現(xiàn)的發(fā)送和接收,通過打破這種依賴關(guān)系,使得發(fā)送操作能夠與計(jì)算重疊。在張量/序列并行中,介紹了融合通信和計(jì)算等優(yōu)化策略,以及將GEMM內(nèi)核分成小塊并與通信進(jìn)行流水線執(zhí)行。
高效操作符
盡管在MegatronLM中已經(jīng)對(duì)GEMM操作符進(jìn)行了優(yōu)化,但其他操作符中還有進(jìn)一步增強(qiáng)的機(jī)會(huì)。注意力部分采用了FlashAttention-2,改進(jìn)了不同線程塊和warp之間的工作分配。LayerNorm和GeLU由先前實(shí)現(xiàn)中的細(xì)粒度內(nèi)核組成。通過將這些內(nèi)核融合在一起,減少了與啟動(dòng)多個(gè)內(nèi)核相關(guān)的開銷,并有助于優(yōu)化內(nèi)存訪問模式,從而實(shí)現(xiàn)更好的性能。
數(shù)據(jù)流水線優(yōu)化
數(shù)據(jù)預(yù)處理和加載經(jīng)常被忽視。然而,這些操作在每個(gè)訓(xùn)練步驟開始時(shí)會(huì)產(chǎn)生不可忽視的GPU空閑時(shí)間。優(yōu)化這些操作對(duì)于訓(xùn)練過程的效率至關(guān)重要。
異步數(shù)據(jù)預(yù)處理。數(shù)據(jù)預(yù)處理不在關(guān)鍵路徑上。因此,當(dāng)GPU工作器在每個(gè)訓(xùn)練步驟結(jié)束同步梯度時(shí),可以開始后續(xù)步驟的數(shù)據(jù)預(yù)處理,這就隱藏了預(yù)處理的開銷。
消除冗余數(shù)據(jù)加載器。在分布式訓(xùn)練的典型數(shù)據(jù)加載階段,每個(gè)GPU工作器都配備了自己的數(shù)據(jù)加載器,負(fù)責(zé)將訓(xùn)練數(shù)據(jù)讀入CPU內(nèi)存,然后轉(zhuǎn)發(fā)到GPU。這導(dǎo)致工作線程之間為爭奪磁盤讀取帶寬,因此產(chǎn)生了瓶頸。我們觀察到,在LLM訓(xùn)練設(shè)置中,同一臺(tái)機(jī)器內(nèi)的GPU工作器處于相同的張量并行組。因此,它們每次迭代的輸入本質(zhì)上是相同的。基于這一觀察,我們采用了兩層樹狀的方法,在每臺(tái)機(jī)器上使用一個(gè)專用的數(shù)據(jù)加載器將訓(xùn)練數(shù)據(jù)讀入共享內(nèi)存。隨后,每個(gè)GPU工作器負(fù)責(zé)將必要的數(shù)據(jù)復(fù)制到自己的GPU內(nèi)存中。這就消除了冗余讀取,并顯著提高了數(shù)據(jù)傳輸?shù)男省?/p>
集體通信群初始化
在分布式訓(xùn)練中,初始化階段涉及在GPU工作器之間建立NVIDIA集體通信庫(NCCL)通信組。由于這種開銷在小規(guī)模場(chǎng)景中相對(duì)較小,因此默認(rèn)使用torch.distributed。隨著GPU數(shù)量擴(kuò)展到超過一萬個(gè),naive實(shí)現(xiàn)引入的開銷變得無法忍受。
torch.distributed初始化時(shí)間過長有兩個(gè)原因。第一個(gè)問題在于同步步驟,其中每個(gè)進(jìn)程在初始化特定通信組結(jié)束時(shí)參與了一個(gè)屏障操作。這個(gè)屏障使用TCPStore,以單線程、阻塞的讀寫方式操作。可以用非阻塞和異步的Redis替換TCPStore。第二個(gè)問題與全局屏障的不慎使用有關(guān)。每個(gè)進(jìn)程在初始化其相應(yīng)的通信組后執(zhí)行一個(gè)全局屏障。我們精心設(shè)計(jì)了通信組的初始化順序,以最小化全局屏障的需求,降低了時(shí)間復(fù)雜度。
在未經(jīng)優(yōu)化的情況下,2048張GPU的集群初始化時(shí)間是1047秒,優(yōu)化后可降至5秒以下;萬卡GPU集群的初始化時(shí)間則可降至30秒以下。
網(wǎng)絡(luò)性能調(diào)優(yōu)
分析了3D并行中機(jī)器間的流量,并設(shè)計(jì)了技術(shù)方案來提高網(wǎng)絡(luò)性能。包括網(wǎng)絡(luò)拓?fù)湓O(shè)計(jì)、減少ECMP哈希沖突、擁塞控制和重傳超時(shí)設(shè)置。
網(wǎng)絡(luò)拓?fù)洹N覀兊臄?shù)據(jù)中心網(wǎng)絡(luò)是基于Broadcom Tomahawk 4芯片構(gòu)建的高性能交換機(jī)。每個(gè)Tomahawk芯片的總帶寬為25.6Tbps,具有64×400Gbps端口。三層交換機(jī)以CLOS類似的拓?fù)溥B接,以連接超過10000個(gè)GPU。每層交換機(jī)的下行鏈路和上行鏈路的帶寬比為1:1。也就是說,32個(gè)端口用于下行,32個(gè)端口用于上行。該網(wǎng)絡(luò)以較小的直徑提供了高帶寬,每個(gè)節(jié)點(diǎn)都可以在有限的跳數(shù)內(nèi)與其他節(jié)點(diǎn)通信。
減少ECMP哈希沖突。我們精心設(shè)計(jì)了網(wǎng)絡(luò)拓?fù)洌⒄{(diào)度網(wǎng)絡(luò)流量以減少ECMP哈希沖突。首先,在機(jī)架ToR交換機(jī)上把上行與下行鏈路分開,一個(gè) 400G 下行鏈路端口通過特定的 AOC 電纜分為兩個(gè) 200G 下行鏈路端口,有效降低沖突率。
擁塞控制。在分布式訓(xùn)練中大規(guī)模使用默認(rèn)的DCQCN協(xié)議時(shí),all-to-all通信可能會(huì)導(dǎo)致?lián)砣?a target="_blank">PFC級(jí)別的提高。過度使用PFC可能會(huì)導(dǎo)致頭部阻塞(HoL),從而降低網(wǎng)絡(luò)吞吐量。為了緩解這些問題,我們開發(fā)了一個(gè)結(jié)合了Swift和DCQCN原理的算法,該算法將往返時(shí)間(RTT)的精確測(cè)量與顯式擁塞通知(ECN)的快速擁塞響應(yīng)能力相結(jié)合。這種方法顯著提高了吞吐量,并最小化了與PFC相關(guān)的擁塞。
重傳超時(shí)設(shè)置。NCCL中的參數(shù)可以設(shè)置以控制重傳定時(shí)器和重試次數(shù)。我們調(diào)整這些參數(shù)以在鏈路抖動(dòng)時(shí)快速恢復(fù)。為了進(jìn)一步減少恢復(fù)時(shí)間,我們?cè)贜IC上啟用了adap_retrans功能。此功能支持在較短的時(shí)間間隔內(nèi)進(jìn)行重傳,當(dāng)鏈路抖動(dòng)周期較短時(shí),有助于更快地恢復(fù)傳輸過程。
03、容錯(cuò)性
隨著訓(xùn)練集群擴(kuò)展到超過數(shù)萬個(gè)GPU,軟件和硬件故障幾乎是不可避免的。我們?yōu)長LM訓(xùn)練設(shè)計(jì)了一個(gè)健壯的訓(xùn)練框架,實(shí)現(xiàn)了自動(dòng)故障識(shí)別和快速恢復(fù),在最小的人為干預(yù)和對(duì)正在進(jìn)行的訓(xùn)練任務(wù)最小影響的情況下實(shí)現(xiàn)容錯(cuò)性。
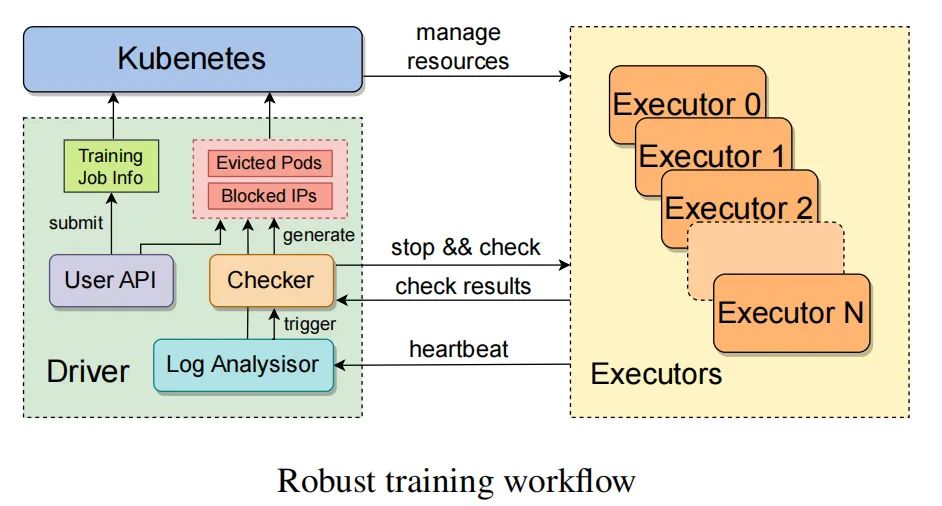
如上圖所示,在接收到訓(xùn)練任務(wù)后,驅(qū)動(dòng)程序進(jìn)程會(huì)與自定義的Kubernetes接口進(jìn)行交互,以便分配計(jì)算資源并為每個(gè)執(zhí)行器啟動(dòng)相應(yīng)的Pod。一個(gè)執(zhí)行器管理一個(gè)節(jié)點(diǎn)。執(zhí)行器完成初始化任務(wù)后將在每個(gè)GPU上創(chuàng)建訓(xùn)練進(jìn)程,并啟動(dòng)一個(gè)健壯的訓(xùn)練守護(hù)進(jìn)程,定期向驅(qū)動(dòng)程序發(fā)送heartbeat以便實(shí)時(shí)檢測(cè)異常并預(yù)警。當(dāng)檢測(cè)到異常狀態(tài)或在預(yù)定時(shí)間內(nèi)未收到狀態(tài)報(bào)告時(shí),會(huì)觸發(fā)故障恢復(fù)程序,將暫停所有正在進(jìn)行的訓(xùn)練任務(wù),并命令它們自我檢查診斷。
一旦識(shí)別出問題節(jié)點(diǎn),驅(qū)動(dòng)程序?qū)⑾騅ubernetes提交要被封鎖的節(jié)點(diǎn)的IP地址,以及在這些節(jié)點(diǎn)上運(yùn)行的Pod信息,Kubernetes將驅(qū)逐故障節(jié)點(diǎn),并用健康節(jié)點(diǎn)替換。此外,還有一個(gè)用戶界面可以手動(dòng)刪除問題節(jié)點(diǎn)。恢復(fù)過程完成后,驅(qū)動(dòng)程序會(huì)從最新的checkpoint恢復(fù)訓(xùn)練。我們優(yōu)化了checkpoint和恢復(fù)過程,以最小化訓(xùn)練進(jìn)度的損失。
為了增強(qiáng)對(duì)訓(xùn)練穩(wěn)定性和性能的監(jiān)控,開發(fā)了一個(gè)精度達(dá)到毫秒級(jí)的監(jiān)控系統(tǒng)。采用不同級(jí)別的監(jiān)控來跟蹤各種指標(biāo)。此外,文中還講述了如何實(shí)現(xiàn)checkpoint快速恢復(fù)、訓(xùn)練故障排除,以及MegaScale部署和運(yùn)營的經(jīng)驗(yàn),感興趣的可下載論文查閱。
04、結(jié)論
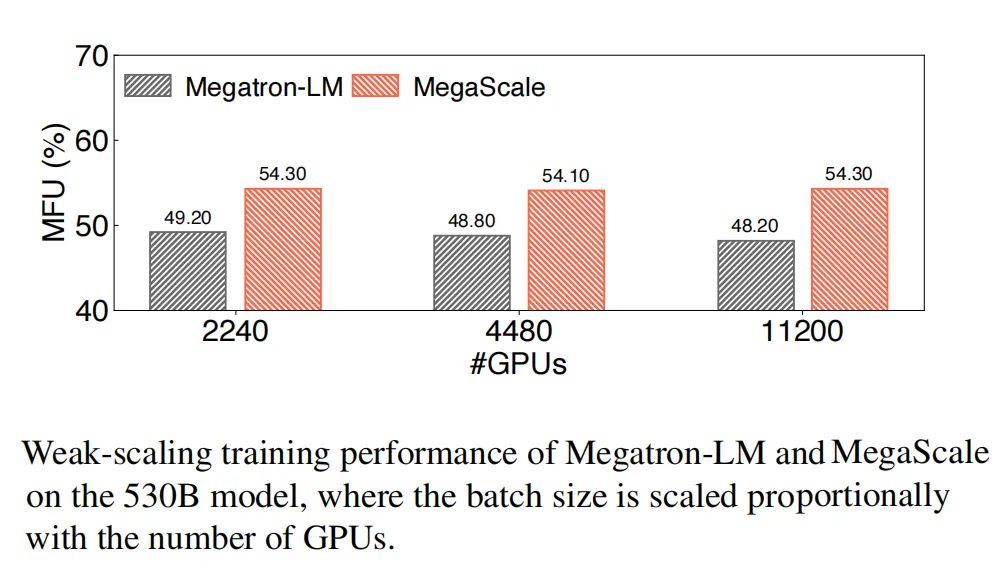
本文深入探討了MegaScale的設(shè)計(jì)、實(shí)現(xiàn)和部署。通過算法-系統(tǒng)協(xié)同設(shè)計(jì),MegaScale優(yōu)化了訓(xùn)練效率。在12288個(gè)GPU上訓(xùn)練一個(gè)175B LLM模型時(shí),MegaScale實(shí)現(xiàn)了55.2%的MFU,比Megatron-LM提高了1.34倍。
我們強(qiáng)調(diào)在整個(gè)訓(xùn)練過程中需要容錯(cuò),并實(shí)現(xiàn)了一個(gè)定制的健壯訓(xùn)練框架,以自動(dòng)定位和修復(fù)故障。此外,還提供了一套全面的監(jiān)控工具,用于深入觀察系統(tǒng)組件和事件,便于復(fù)雜異常的根本原因識(shí)別。我們相信,我們的工作不僅為那些從事LLM訓(xùn)練的人提供了實(shí)用的見解,也為這個(gè)快速發(fā)展的領(lǐng)域的未來研究鋪平了道路。
審核編輯:黃飛
























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論