 電子發(fā)燒友App
電子發(fā)燒友App


大部分人都聽說過個(gè)性化推薦,也知道千人千面,那么個(gè)性化推薦系統(tǒng)到底是怎么樣的?最近做了一點(diǎn)總結(jié)。
現(xiàn)在的人們面對(duì)信息過載問題日益嚴(yán)重,好的個(gè)性化推薦將能夠很好的提升用戶體驗(yàn),提高用戶使用產(chǎn)品完成任務(wù)的效率,更好的留住用戶,進(jìn)一步擴(kuò)大產(chǎn)品的盈利。
對(duì)于一些電商類的產(chǎn)品,個(gè)性化推薦也能幫助減少馬太效應(yīng)和長尾效應(yīng)的影響,使商品的利用率更高,盈利增長。
【注】
馬太效應(yīng):產(chǎn)品中熱門的東西會(huì)被更多人看到,熱門的東西會(huì)變得更加熱門,而冷門的東西更加冷門。
長尾理論:某些條件下,需求和銷量不高的產(chǎn)品所占據(jù)的市場(chǎng)份額,可以和主流產(chǎn)品的市場(chǎng)份額相比。
對(duì)于推薦系統(tǒng)的解釋分為4部分
一、常見的推薦算法原理(時(shí)間、位置影響)
目前常見的一些推薦如下:
基于內(nèi)容推薦:分析用戶看過的內(nèi)容(歷史內(nèi)容等 )再進(jìn)行推薦。
基于用戶的協(xié)同過濾推薦(UserCF):給用戶推薦和他興趣相似的其它用戶喜歡的物品。
基于物品的協(xié)同過濾推薦(ItemCF):給用戶推薦和他之前喜歡的物品相似的物品。
基于標(biāo)簽的推薦:內(nèi)容有標(biāo)簽,用戶也會(huì)因?yàn)橛脩粜袨楸淮蛏蠘?biāo)簽,通過給用戶打標(biāo)簽或是用戶給產(chǎn)品打標(biāo)簽為其推薦物品。
隱語義模型推薦(LFM):通過隱含特征推薦和用戶興趣匹配的物品。
社會(huì)化推薦:讓好友給自己推薦物品。
根據(jù)時(shí)間上下文推薦:利用用戶訪問產(chǎn)品的時(shí)間優(yōu)化推薦算法,或是根據(jù)季節(jié)性時(shí)令性變化進(jìn)行推薦。(如春節(jié)推薦春節(jié)相關(guān)物品)
基于地理位置的推薦(LARS):根據(jù)用戶的地理位置進(jìn)行推薦。
其中比較常見的就是前4種推薦,7、8實(shí)際上是在基本的推薦算法上加上了一層根據(jù)時(shí)間和位置的加權(quán)篩選。
各種推薦算法是可以疊加在一起的,根據(jù)不同算法的權(quán)重調(diào)整,給用戶最為精準(zhǔn)智能的推薦。
(一)、基于內(nèi)容的推薦
基于內(nèi)容的推薦是基礎(chǔ)的推薦策略。如果你瀏覽或購買過某種類型的內(nèi)容,則給你推薦這種類型下的其他內(nèi)容。
基于內(nèi)容的推薦好處在于易于理解,但不足在于推薦不夠智能,多樣性和新穎性不足。
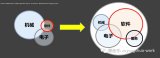
比如下圖中用戶某一天想買的是單反,但購買單反不是一個(gè)頻繁的行為,且買的是高端單反,那么接下來給用戶推薦的全是高端單反,推薦的轉(zhuǎn)化率就會(huì)低很多。
又或者是根據(jù)瀏覽歷史推薦,但假如我已經(jīng)買過了該物品,再給我推薦,重復(fù)購買的可能性會(huì)低很多。
(二)、基于用戶的協(xié)同過濾算法:
基于用戶的協(xié)同過濾(UserCF)算法,通過用戶對(duì)不同內(nèi)容的行為,來評(píng)測(cè)用戶之間的相似性,基于用戶之間的相似性做出推薦。這部分推薦本質(zhì)上是給用戶推薦和他相似的人感興趣的東西。
比如你曾經(jīng)喜歡(多次觀看)的電影都是科幻類的電影,如異形,終結(jié)者、星球大戰(zhàn)等,通過數(shù)據(jù)分析我找到了和你一樣看過異形,終結(jié)者,星球大戰(zhàn)的人,我發(fā)現(xiàn)他還經(jīng)常看復(fù)仇者聯(lián)盟的電
影,那么我則可以推薦你很有可能也會(huì)喜歡看復(fù)仇者聯(lián)盟,那么我就可以向你推薦復(fù)仇者聯(lián)盟。
以下對(duì)UserCF進(jìn)行比較詳細(xì)的說明,其余的算法會(huì)類似:
用 N(u)表示用戶u曾經(jīng)有過正反饋的物品集合
用N(v)表示用戶v曾經(jīng)有過正反饋的物品集合
用jaccard公式表示u和v的興趣相似度:
W(uv)=|N(u)∩N(v)|/|N(u)∪N(v)| 或者 用余弦相似度 W(uv)=|N(u)∩N(v)|/√|N(u)||N(v)|
對(duì)應(yīng)的表如下,該表的意思是用戶A對(duì)物品{a,b,c}有有過行為,對(duì){a,b,c}是感興趣的,用戶B對(duì){a,c}是感興趣的
那么用余弦公式計(jì)算用戶A和用戶B的興趣相似度就是W(ab)=|{a,b,c}∩{a,c}|/√|{a,b,c}||{a,c}|=1/√6
實(shí)際上的話,很多用戶之間并沒有對(duì)同樣的物品產(chǎn)生行為,即|N(u)∩N(v)|=0,為了優(yōu)化這種情況,我們可以先計(jì)算出|N(u)∩N(v)|≠0的用戶(u,v)再除以分母√|N(u)||N(v)|
首先需要建立物品到用戶的倒排表,對(duì)于每個(gè)物品都保存該物品產(chǎn)生過行為的用戶列表,令稀疏矩陣C[u][v]=|N(u)∩N(v)|,假設(shè)用戶u和用戶v同時(shí)屬于倒排表K個(gè)物品對(duì)應(yīng)的用戶列表
即C[u][v]=K,接著掃描倒排表中每個(gè)物品對(duì)應(yīng)的用戶列表,將用戶列表中兩兩用戶對(duì)應(yīng)的C[u][v]加1,最終就可以得到所有用戶之間不為0的C[u][v]
如圖,建立了一個(gè)4X4的用戶相似度矩陣,對(duì)于物品a,將W[A][B]和W[B][A]加1,對(duì)于物品b,將W[A][C]和W[C][A]加1,掃描完所有物品后,可以得到最終的W矩陣,這里的W就是余弦
相似度公式的分子,再除以分母√|N(u)||N(v)| 就可以得到最終的用戶興趣相似度。
得到了用戶興趣相似度后,根據(jù)UserCF算法給用戶推薦和他興趣最相似的K個(gè)用戶喜歡的物品,以下的公式計(jì)算了UserCF中用戶u對(duì)物品i的感興趣程度,公式如下:
S(u,k):用戶u興趣最接近的K個(gè)用戶
N(i):對(duì)物品i有行為的用戶集合
W(uv):用戶u和用戶v的興趣相似度
rvi:用戶v對(duì)物品i的興趣,因?yàn)槭褂玫氖菃我恍袨榈碾[反饋數(shù)據(jù),所以所有的rvi=1
以上的算法公式還比較粗糙,如果兩個(gè)人購買了同一個(gè)物品,不能說明他們的興趣一定相同,因此可以對(duì)算法進(jìn)行改進(jìn),提高算法的性能。
新的公式會(huì)通過降權(quán)懲罰用戶u和用戶v共同興趣列表中熱門物品對(duì)他們相似度對(duì)影響。
不同的算法有各自不同的效果,也會(huì)有不同的限制和缺點(diǎn),在使用中也要結(jié)合產(chǎn)品的用戶不停調(diào)整優(yōu)化,達(dá)到最好的效果。
UserCF的限制和缺點(diǎn):用戶數(shù)越來越大的話,計(jì)算用戶之間的相似度矩陣,系統(tǒng)運(yùn)行的時(shí)間,復(fù)雜度,整體的成本都會(huì)大幅度增加。
(三)、基于物品的協(xié)同過濾算法
基于物品的協(xié)同過濾(ItemCF)算法,通過分析用戶的行為記錄計(jì)算物品之間的相似度,比如物品A和物品B具有很大的相似度是因?yàn)橄矚gA的用戶大都也喜歡物品B。
比如下圖中,我曾經(jīng)搜索過桌面擺件招財(cái)貓,然后系統(tǒng)推薦給我了同樣是桌面擺件的摩托車模型。
計(jì)算物品之間的相似度
根據(jù)物品之間的相似度和用戶的歷史行為給用戶生成推薦列表
W(i,j)=|N(i)∩N(j)|/√|N(i)||N(j)|
N(i)和N(j)表示喜歡物品i的用戶數(shù),ItemCF的算法結(jié)構(gòu)基本與UserCF的算法類似,這里不做過多說明了。
算法并不萬能,需要不斷調(diào)整和優(yōu)化,或是根據(jù)形態(tài)簡(jiǎn)化算法。
UserCF的推薦更社會(huì)化,反映了用戶所在的小型興趣群體中物品的熱門程度,更快。
ItemCF的推薦更加個(gè)性化,反映了用戶自己興趣,用戶興趣需要穩(wěn)定持久。
UserCF
性能:適用于用戶較少的場(chǎng)合,用戶多則計(jì)算相似矩陣代價(jià)大
領(lǐng)域:實(shí)效性強(qiáng),用戶個(gè)性化興趣不太明顯的領(lǐng)域
實(shí)時(shí)性:用戶有新行為,不一定造成推薦結(jié)果的立即變化
冷啟動(dòng):新用戶對(duì)很少的物品產(chǎn)生行為后,不能立即對(duì)其進(jìn)行個(gè)性化推薦。新物品上線后,一旦有用戶對(duì)物品進(jìn)行了行為,將可以將新物品推薦給和他產(chǎn)生行為的用戶興趣相似的其它用戶。
ItemCF
性能:適用于物品數(shù)明顯小于用戶數(shù)的場(chǎng)合,如果物品較多,矩陣計(jì)算代價(jià)大
領(lǐng)域:長尾物品豐富,用戶個(gè)性化需求強(qiáng)烈的領(lǐng)域
實(shí)時(shí)性:用戶有新行為,一定會(huì)導(dǎo)致推薦結(jié)果的實(shí)時(shí)變化
冷啟動(dòng):新用戶只要對(duì)一個(gè)物品產(chǎn)生行為,就可以給他推薦和該物品相關(guān)的其它物品。不能在不離線更新物品相似度表的情況下將新物品推薦給用戶。
兩種算法的一些限制:
若某個(gè)物品太過熱門,則所有推薦中都可能出現(xiàn)該物品,需要對(duì)熱門物品作出懲罰,懲罰公式xxxx
不同領(lǐng)域的最熱門物品之間往往有比較高的相似度。(僅靠用戶數(shù)據(jù)不能解決這個(gè)問題)
(四)、基于標(biāo)簽的推薦
基于標(biāo)簽的推薦一般分為兩種,一種是通過給用戶的某些特征打上標(biāo)簽,另一種則是讓用戶自己給物品打上標(biāo)簽,這里主要講用戶給物品打標(biāo)簽(UGC)。
基于UGC的標(biāo)簽推薦主要是利用用戶打標(biāo)簽的行為為其推薦物品,在用戶給物品打標(biāo)簽時(shí)也要提供合適該物品的標(biāo)簽。用戶用標(biāo)簽描述對(duì)物品的看法,標(biāo)簽是反應(yīng)用戶興趣的重要數(shù)據(jù)源。
一個(gè)用戶行為的數(shù)據(jù)集一般由一個(gè)三元組的集合表示,其中記錄{u,i,b}表示用戶u給物品i打上了標(biāo)簽b(當(dāng)然實(shí)際中會(huì)包含用戶屬性、物品屬性等,更為復(fù)雜)。
–(具體的算法這里隱去,了解原理即可)–
給用戶提供標(biāo)簽一般有 這么幾種方法 :
給用戶推薦一個(gè)系統(tǒng)中最熱門的標(biāo)簽
給用戶推薦物品i上最熱門的標(biāo)簽
給用戶推薦他自己經(jīng)常使用的標(biāo)簽
將方法2和方法3融合,通過一個(gè)系數(shù)將上面的推薦結(jié)果線性加權(quán),生成最終的推薦結(jié)果
常見的基于標(biāo)簽(UGC)的推薦有豆瓣:
(五)、隱語義模型LFM
LFM的核心思想:通過隱含特征聯(lián)系用戶興趣和物品
對(duì)于某個(gè)用戶,首先要得到他的興趣分類,然后從分類中挑選他可能喜歡的物品,要得到他喜歡的的物品分類需要考慮到3個(gè)問題:
1.如何給物品分類?
目前比較簡(jiǎn)單的做法是通過人工給物品分類,按照不同的物品分類方法。
另外則是通過隱含語義分析技術(shù),采用基于用戶行為統(tǒng)計(jì)的自動(dòng)聚類來解決這個(gè)問題,比較著名的模型和方法有pLSA,LDA,隱含類別模型,隱含主題模型,矩陣分析等等。
2.如何確定用戶對(duì)哪些物品感興趣,以及感興趣的程度?
推薦系統(tǒng)的用戶行為分為隱性反饋和顯性反饋,主要討論隱性反饋數(shù)據(jù)集 ,這種數(shù)據(jù)集只有正樣本(用戶喜歡什么物品),沒有負(fù)樣本(用戶對(duì)什么物品不感興趣),在隱性反饋數(shù)據(jù)集上應(yīng)用LFM解決推薦的問題需要給每個(gè)用戶生成負(fù)樣本,有這么幾種方法:
對(duì)于一個(gè)用戶,用他沒有過行為的物品作為負(fù)樣本
對(duì)于一個(gè)用戶,用他沒有過行為的物品中均勻采樣出一些物品作為負(fù)樣本
對(duì)于一個(gè)用戶,從他沒有過行為的物品中采樣出一些物品作為負(fù)樣本,采樣時(shí),保證每個(gè)用戶的正負(fù)樣本數(shù)目相當(dāng)
對(duì)于一個(gè)用戶,從他沒有過行為的物品中采樣出一些物品作為負(fù)樣本,采樣時(shí),偏重不熱門的物品。
采負(fù)樣本的一些原則:
對(duì)于每個(gè)用戶,采樣時(shí)要保證正負(fù)樣本的平衡。
對(duì)于每個(gè)用戶采樣負(fù)樣本時(shí),要選取那些熱門,而用戶沒有行為的物品。
綜合以上的方法結(jié)合用戶行為頻率計(jì)算確定用戶感興趣的物品和程度。
3.對(duì)一個(gè)給定的類,選擇哪些屬于這個(gè)類的物品推薦給用戶,以及如何確定這些物品在一個(gè)類中的權(quán)重?
這個(gè)問題主要的解決方法就是通過1.2的計(jì)算結(jié)果綜合算法得出,根據(jù)算法計(jì)算調(diào)整不同物品的權(quán)重,通過迭代不斷優(yōu)化算法中的參數(shù)。
LFM中重要的參數(shù)有(僅了解就可以,具體需要結(jié)合算法公式):
隱特征的個(gè)數(shù)F
算法學(xué)習(xí)的速率
正則化參數(shù)
負(fù)樣本/正樣本比例
LFM具有學(xué)習(xí)能力,能實(shí)現(xiàn)自我學(xué)習(xí)不斷優(yōu)化模型。
(六)、社會(huì)化推薦
根據(jù)某機(jī)構(gòu)的調(diào)查,在購買物品時(shí),90%左右的用戶會(huì)相信朋友的推薦,70%的用戶會(huì)相信網(wǎng)上其他用戶對(duì)商品的評(píng)論。
在互聯(lián)網(wǎng)中最明顯的社會(huì)化推薦則是利用社交網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行推薦,利用社交網(wǎng)絡(luò)數(shù)據(jù)推薦一般可以從以下幾個(gè)方面入手:
電子郵箱的社交關(guān)系信息
用戶注冊(cè)信息
用戶的位置數(shù)據(jù),web的IP和手機(jī)的GPS
討論組和論壇
聊天工具中的好友關(guān)系列表
社交網(wǎng)站中的好友關(guān)系數(shù)據(jù)
基于社交信息的社會(huì)化推薦能夠利用好友的關(guān)系,解決一部分冷啟動(dòng)的問題。
情況1.你通過朋友的分享進(jìn)入的,你朋友在網(wǎng)站中玩的比較久,有推薦數(shù)據(jù)。由于你之前在該網(wǎng)站沒有任何數(shù)據(jù),那么我要想給你推薦物品,就可以根據(jù)你朋友的推薦列表來給你推薦你可能會(huì)喜歡的東西。
情況2.如果你是剛來到一個(gè)網(wǎng)站,你沒有朋友, 我想給你做社會(huì)化推薦的話,可以根據(jù)你的注冊(cè)信息、位置,共同興趣等給你推薦好友,再給你做好友推薦。
(七)、根據(jù)時(shí)間上下文推薦
上下文包括用戶訪問推薦系統(tǒng)的時(shí)間、地點(diǎn)、心情等,根據(jù)時(shí)間上下文的推薦是希望能夠準(zhǔn)確預(yù)測(cè)用戶在某個(gè)特定時(shí)刻或某段時(shí)刻的興趣。
比如電商產(chǎn)品在賣衣服時(shí),冬天推薦的衣物和夏天推薦的衣物是不同的。如下圖,淘寶網(wǎng)在冬季的推薦:
時(shí)間信息對(duì)用戶興趣的影響主要表現(xiàn)在以下幾個(gè)方面:
用戶的興趣是變化的
物品是有生命周期的
季節(jié)效應(yīng)
考慮到時(shí)間信息后,推薦系統(tǒng)也從一個(gè)靜態(tài)系統(tǒng)變成了一個(gè)時(shí)變的系統(tǒng),而用戶行為數(shù)據(jù)也變成了時(shí)間序列。
在給定數(shù)據(jù)集后,可以通過統(tǒng)計(jì)以下信息研究推薦系統(tǒng)的時(shí)間特性:
數(shù)據(jù)集每天獨(dú)立用戶數(shù)的增長情況(平穩(wěn)階段、增長階段、衰落階段等)
系統(tǒng)的物品變化情況
用戶訪問情況
推薦系統(tǒng)的實(shí)時(shí)性
用戶的興趣是不斷變化的,其變化體現(xiàn)在用戶不斷增加的新行為中,一個(gè)實(shí)時(shí)的推薦系統(tǒng)需要能夠?qū)崟r(shí)響應(yīng)用戶新的行為,讓推薦列表不斷變化,從而滿足用戶不斷變化的興趣。
實(shí)時(shí)的推薦系統(tǒng)應(yīng)該滿足:
對(duì)用戶行為的存取有實(shí)時(shí)性(在用戶訪問推薦系統(tǒng)時(shí)計(jì)算)。
對(duì)推薦算法本身有實(shí)時(shí)性(考慮到用戶近期行為和長期行為)。
推薦算法的時(shí)間多樣性:推薦系統(tǒng)每天推薦結(jié)果的變化程度,有的推薦系統(tǒng)中用戶經(jīng)常能看到不同的推薦結(jié)果。
時(shí)間上下文的推薦算法
推薦最新最熱門的物品
時(shí)間上下文的ItemCF算法,利用用戶行為離線計(jì)算物品之間的相似度,根據(jù)用戶的歷史行為和物品相似度矩陣,給用戶做在線個(gè)性化推薦。
物品的相似度計(jì)算:用戶在像個(gè)很短的時(shí)間內(nèi)喜歡的物品有更高的相似度。
在線推薦:用戶近期行為相比用戶很久之前的行為,更能體現(xiàn)用戶現(xiàn)在的興趣。
3.時(shí)間上文的UserCF算法
用戶的興趣相似度計(jì)算:如果兩個(gè)用戶同時(shí)喜歡相同的物品,則興趣相似度越大。
相似興趣用戶的最近行為(推薦與其興趣相似的用戶最近喜歡的物品)。
(八)、基于地理位置的推薦
基于位置的推薦算法(LARS)會(huì)根據(jù)用戶所在的國家、城市、街道探尋規(guī)律進(jìn)行推薦,找到用戶地點(diǎn)和興趣相關(guān)的特征,主要包括興趣本地化和活動(dòng)本地化。
LARS的基本思想是將數(shù)據(jù)集根據(jù)用戶的位置劃分成很多子集,位置是一個(gè)樹狀結(jié)構(gòu),比如國家、省、市、區(qū)、縣的結(jié)構(gòu),因此數(shù)據(jù)集也會(huì)劃分成一個(gè)樹狀結(jié)構(gòu)。
根據(jù)用戶的位置,將其分配到一個(gè)葉子節(jié)點(diǎn)中,而該節(jié)點(diǎn)會(huì)包括了所有和他同一位置的用戶行為數(shù)據(jù)集。
LARS會(huì)利用該葉子節(jié)點(diǎn)上的用戶行為數(shù)據(jù),通過ItemCF或UserCF給用戶推薦。
數(shù)據(jù)集會(huì)包括(用戶、用戶位置、物品、物品位置、物品評(píng)分)的記錄
比如大眾點(diǎn)評(píng)的推薦:
二、推薦系統(tǒng)的冷啟動(dòng)問題
推薦系統(tǒng)的冷啟動(dòng)問題指的是,當(dāng)推薦系統(tǒng)剛部署后,沒有用戶行為時(shí)或物品數(shù)據(jù)時(shí),推薦系統(tǒng)并不能根據(jù)用戶行為數(shù)據(jù)給用戶推薦物品。一般分為用戶冷啟動(dòng)、物品冷啟動(dòng)和系統(tǒng)冷啟動(dòng)。
通常有一些辦法可以緩和冷啟動(dòng)問題
1.利用用戶注冊(cè)信息推薦:即獲取用戶的注冊(cè)信息,然后對(duì)用戶分類,給用戶推薦他所屬分類中可能感興趣的物品。 將關(guān)聯(lián)的查詢結(jié)果按照一個(gè)權(quán)重相加,利用的用戶信息越多,就能越精準(zhǔn)
地匹配用戶興趣。
2.給用戶一些內(nèi)容選擇合適的物品啟動(dòng)用戶的興趣:選擇一些熱門的,有代表性、區(qū)分性、多樣性的物品推薦給用戶。
3.利用物品的內(nèi)容信息推薦給用戶:可以通過人工篩選出一些用戶會(huì)感興趣的物品推薦。
三、推薦系統(tǒng)的架構(gòu)
如果一個(gè)系統(tǒng)中將各種用戶行為、特征和任務(wù)都考慮進(jìn)去,系統(tǒng)會(huì)非常復(fù)雜,難以配置。因此推薦系統(tǒng)需要由多個(gè)推薦引擎組成,每個(gè)推薦引擎負(fù)責(zé)一類特真和一種任務(wù),而推薦系統(tǒng)只是
將推薦引擎的結(jié)果按照一定權(quán)重或優(yōu)先級(jí)合并、排序,然后返回。
這樣的優(yōu)勢(shì)在于:每一個(gè)引擎代表了一種推薦策率,可通過對(duì)單一的引擎調(diào)整來優(yōu)化推薦系統(tǒng)。
如何設(shè)計(jì)一個(gè)推薦引擎成了推薦系統(tǒng)設(shè)計(jì)的核心部分。
模塊A:從數(shù)據(jù)庫或緩存中拿到用戶行為數(shù)據(jù),通過分析不同行為,生成當(dāng)前用戶的特征向量。
模塊B:將用戶的特征向量通過特征-物品相關(guān)舉證轉(zhuǎn)換為初始推薦物品列表。
模塊C:對(duì)初始的推薦列表進(jìn)行過濾,排名等處理,生成最終的推薦結(jié)果。
生成用戶特征向量:用戶特征向量一般包括兩種:
從用戶的注冊(cè)信息提取,包括用戶的人口統(tǒng)計(jì)學(xué)特征等,在推薦時(shí)直接拿到用戶他惡政數(shù)據(jù)生成特征向量。
從用戶行為中計(jì)算出來
通過用戶行為生成特征(需要考慮以下幾點(diǎn)):
用戶行為的種類(用戶會(huì)對(duì)物品產(chǎn)生很多種不同的行為)。
用戶行為產(chǎn)生的時(shí)間(近期行為比較重要)。
用戶行為的次數(shù)(一般行為次數(shù)多的物品權(quán)重越高)。
物品的熱門程度(用戶對(duì)很熱門的物品產(chǎn)生行為可能是在跟風(fēng),推薦引擎在生成用戶特征時(shí)會(huì)加重不熱門物品對(duì)應(yīng)特征的權(quán)重)。













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論