 電子發(fā)燒友App
電子發(fā)燒友App


2017年終解讀:語音識(shí)別技術(shù)今年只走了一半的路
這一年,百度開放了語音平臺(tái)DuerOS,阿里補(bǔ)貼了4個(gè)億銷售百萬智能音箱搶占語音入口。而作為語音識(shí)別的先驅(qū)龍頭,大家開始擔(dān)心科大訊飛用近二十年建立起來的技術(shù)壁壘被摧毀,有人扒訊飛的業(yè)務(wù),有人開始扒訊飛十年的財(cái)報(bào)。
這一年的人工智能大潮,無疑讓更多人關(guān)注科大訊飛,關(guān)心在這樣的潮流里,一家深耕語音識(shí)別的公司如何能獲得更多業(yè)務(wù)和利潤(rùn),如何能去迎合AI上升的趨勢(shì),從而滿足人們對(duì)人工智能的所有期望。
其實(shí)這一年,技術(shù)的進(jìn)程還是和往年一樣。(我們從語音識(shí)別的角度來解讀2017年的進(jìn)展,部分技術(shù)解讀來源自對(duì)訊飛的采訪)。
2017,從數(shù)據(jù)提升開始說起
去年IBM、微軟、谷歌和百度都發(fā)布過自家語音識(shí)別進(jìn)展,而今年對(duì)媒體更新詞錯(cuò)率進(jìn)展的有三家:
2017年3月,IBM結(jié)合了 LSTM 模型和帶有 3 個(gè)強(qiáng)聲學(xué)模型的 WaveNet 語言模型。“集中擴(kuò)展深度學(xué)習(xí)應(yīng)用技術(shù)終于取得了 5.5% 詞錯(cuò)率的突破”。相對(duì)應(yīng)的是去年5月的6.9%。
2017年8月,微軟發(fā)布新的里程碑,通過改進(jìn)微軟語音識(shí)別系統(tǒng)中基于神經(jīng)網(wǎng)絡(luò)的聽覺和語言模型,在去年基礎(chǔ)上降低了大約12%的出錯(cuò)率,詞錯(cuò)率為5.1%,聲稱超過專業(yè)速記員。相對(duì)應(yīng)的是去年10月的5.9%,聲稱超過人類。
2017年12月,谷歌發(fā)布全新端到端語音識(shí)別系統(tǒng)(State-of-the-art Speech Recognition With Sequence-to-Sequence Models),詞錯(cuò)率降低至5.6%。相對(duì)于強(qiáng)大的傳統(tǒng)系統(tǒng)有 16% 的性能提升。
大家的目標(biāo)很一致,就是想“超過人類”,之前設(shè)定人類詞錯(cuò)率為5.9%的這個(gè)界線。
總結(jié)來說,因?yàn)镈eep CNN引入之后,語音識(shí)別取得了很大的突破,例如谷歌從2013年到現(xiàn)在,性能提升了20%。
而國(guó)內(nèi)語音識(shí)別的企業(yè)如百度、搜狗、科大訊飛,識(shí)別率都在97%左右。在語音識(shí)別這件事情上,漢語比英語早一年超越人類水平。
去年,科大訊飛又推出了全新的深度全序列卷積神經(jīng)網(wǎng)絡(luò)(DFCNN)語音識(shí)別框架,該框架的表現(xiàn)比學(xué)術(shù)界和工業(yè)界最好的雙向 RNN 語音識(shí)別系統(tǒng)識(shí)別率提升了15% 以上。今年,在實(shí)際應(yīng)用領(lǐng)域,訊飛輸入法的識(shí)別準(zhǔn)確率在今年7月份也終于突破了97%,達(dá)到了98%。
技術(shù)“可用”是第一步,但技術(shù)最終是要落地的,變成產(chǎn)品和服務(wù)才能實(shí)現(xiàn)價(jià)值。
今年技術(shù)應(yīng)用場(chǎng)景有什么變化?
今年的產(chǎn)品落地,讓人聯(lián)想到的首先肯定是智能音箱。
2016年的數(shù)據(jù)統(tǒng)計(jì)表明,中國(guó)智能音箱銷售量占全球比重為0.35%,6萬:1710萬臺(tái)的差距。在2017年雙十一阿里的補(bǔ)貼銷售之后,終于可以說“中國(guó)智能音箱銷量在百萬以上”,“中國(guó)的智能音箱得到了爆炸式的增長(zhǎng)”。但從需求上說,智能音箱的功能集中在聽音樂、鬧鐘、智能家居等,這些功能并不屬于國(guó)人的“剛需”。BAT巨頭都將智能音箱作為語音入口進(jìn)行搶占,也給了我們一種爆發(fā)的假象。
但這一年,應(yīng)用場(chǎng)景無疑是越來越豐富。基于各個(gè)領(lǐng)域的應(yīng)用拓展,智能語音技術(shù)已經(jīng)走出安靜的室內(nèi)或者私人環(huán)境,走上了服務(wù)大廳、賣場(chǎng)及行駛中的汽車等。技術(shù)的應(yīng)用也越來越深入。機(jī)器翻譯、遠(yuǎn)場(chǎng)識(shí)別、智能降噪、多輪交互、智能打斷等技術(shù)的進(jìn)步,也又給智能語音的應(yīng)用場(chǎng)景帶來了更多的變化。
在智能車載領(lǐng)域,2017年科大訊飛發(fā)布的飛魚系統(tǒng)2.0,融合了 Barge-in全雙工語音交互技術(shù),窄波束定向識(shí)別技術(shù),自然語義理解技術(shù),免喚醒技術(shù),多輪對(duì)話技術(shù)等科大訊飛核心技術(shù)。目前,科大訊飛已經(jīng)為超過200款車型,累計(jì)超過1000萬部車輛輸出了語音交互產(chǎn)品。
此外,在新零售領(lǐng)域,智能語音技術(shù)的應(yīng)用也在不斷擴(kuò)展。比如12月18日,科大訊飛和紅星美凱龍發(fā)布戰(zhàn)略合作計(jì)劃,未來由科大訊飛研發(fā)的智能導(dǎo)購(gòu)機(jī)器人“美美”將在全國(guó)紅星美凱龍門店上市。
語音識(shí)別六十年,技術(shù)突破總是艱難而緩慢
語音識(shí)別的研究起源可以追溯到上世紀(jì)50年代,AT&T貝爾實(shí)驗(yàn)室的Audry系統(tǒng)率先實(shí)現(xiàn)了十個(gè)英文數(shù)字識(shí)別。
從上世紀(jì)60年代開始,CMU的Reddy開始進(jìn)行連續(xù)語音識(shí)別的開創(chuàng)性工作。但是這期間進(jìn)展緩慢,以至于貝爾實(shí)驗(yàn)室的約翰·皮爾斯(John Pierce)認(rèn)為語音識(shí)別是幾乎不可能實(shí)現(xiàn)的事情。
上世紀(jì)70年代,計(jì)算機(jī)性能的提升,以及模式識(shí)別基礎(chǔ)研究的發(fā)展,促進(jìn)了語音識(shí)別的發(fā)展。IBM、貝爾實(shí)驗(yàn)室相繼推出了實(shí)時(shí)的PC端孤立詞識(shí)別系統(tǒng)。
上世紀(jì)80年代是語音識(shí)別快速發(fā)展的時(shí)期,引入了隱馬爾科夫模型(HMM)。此時(shí)語音識(shí)別開始從孤立詞識(shí)別系統(tǒng)向大詞匯量連續(xù)語音識(shí)別系統(tǒng)發(fā)展。
上世紀(jì)90年代是語音識(shí)別基本成熟的時(shí)期,但是識(shí)別效果離實(shí)用化還相差甚遠(yuǎn),語音識(shí)別的研究陷入了瓶頸。
關(guān)鍵突破起始于2006年。這一年辛頓(Hinton)提出深度置信網(wǎng)絡(luò)(DBN),促使了深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)研究的復(fù)蘇,掀起了深度學(xué)習(xí)的熱潮。2009年,辛頓以及他的學(xué)生默罕默德(D. Mohamed)將深度神經(jīng)網(wǎng)絡(luò)應(yīng)用于語音的聲學(xué)建模,在小詞匯量連續(xù)語音識(shí)別數(shù)據(jù)庫(kù)TIMIT上獲得成功。2011年,微軟研究院俞棟、鄧力等發(fā)表深度神經(jīng)網(wǎng)絡(luò)在語音識(shí)別上的應(yīng)用文章,在大詞匯量連續(xù)語音識(shí)別任務(wù)上獲得突破。國(guó)內(nèi)外巨頭大力開展語音識(shí)別研究。
科大訊飛的智能語音探索之路
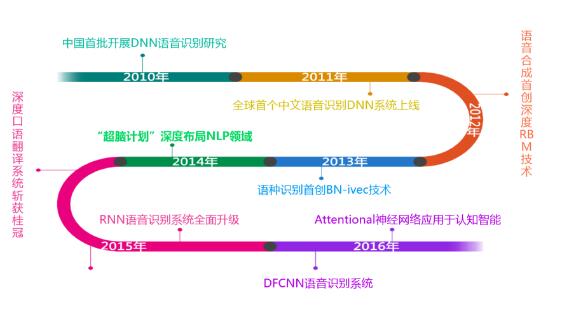
科大訊飛在2010年首批開展DNN語音識(shí)別研究,2011年上線了全球首個(gè)中文語音識(shí)別DNN系統(tǒng)。2012年,在語音合成領(lǐng)域首創(chuàng)RBM技術(shù)。2013年又在語種識(shí)別領(lǐng)域首創(chuàng)BN-ivec技術(shù)。2014年科大訊飛開始深度布局NLP領(lǐng)域,2015年,RNN語音識(shí)別系統(tǒng)全面升級(jí)。
2016年,上線DFCNN(深度全序列卷積神經(jīng)網(wǎng)絡(luò),Deep Fully Convolutional Neural Network)語音識(shí)別系統(tǒng)。在和其他多個(gè)技術(shù)點(diǎn)結(jié)合后,科大訊飛DFCNN的語音識(shí)別框架在內(nèi)部數(shù)千小時(shí)的中文語音短信聽寫任務(wù)上,相比目前業(yè)界最好的語音識(shí)別框架雙向RNN-CTC系統(tǒng)獲得了15%的性能提升,同時(shí)結(jié)合科大訊飛的HPC平臺(tái)和多GPU并行加速技術(shù),訓(xùn)練速度也優(yōu)于傳統(tǒng)的雙向RNN-CTC系統(tǒng)。DFCNN的提出開辟了語音識(shí)別的一片新天地,后續(xù)基于DFCNN框架,還將展開更多相關(guān)的研究工作。
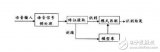
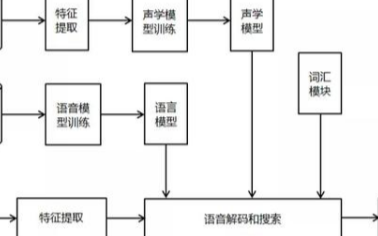
(圖1)DFCNN的結(jié)構(gòu)如圖所示,它直接將一句語音轉(zhuǎn)化成一張語譜圖作為輸入,即先對(duì)每幀語音進(jìn)行傅里葉變換,再將時(shí)間和頻率作為圖像的兩個(gè)維度,然后通過非常多的卷積層和池化(pooling)層的組合,對(duì)整句語音進(jìn)行建模,輸出單元直接與最終的識(shí)別結(jié)果比如音節(jié)或者漢字相對(duì)應(yīng)。
(圖2)
在語音識(shí)別子領(lǐng)域上,今年科大訊飛的智能語音技術(shù)所取得的代表性的成就在自然語言理解領(lǐng)域。7月份,哈工大訊飛實(shí)驗(yàn)室(HFL)刷新了斯坦福大學(xué)發(fā)起的SQuAD(Stanford Question Answering Dataset)機(jī)器閱讀理解挑戰(zhàn)賽全球紀(jì)錄,提交的“基于交互式層疊注意力模型”(Interactive Attention-over-Attention Model)取得了精確匹配77.845%和模糊匹配85.297%的成績(jī),位列世界第一,也是中國(guó)本土研究機(jī)構(gòu)首次取得賽事榜首。
語音合成上,暴風(fēng)雪競(jìng)賽(Blizzard Challenge)是國(guó)際最權(quán)威的語音合成比賽。科大訊飛以語音合成技術(shù)率先達(dá)到4.0分的成績(jī)并連續(xù)12年蟬聯(lián)全球第一名,這是全世界唯一能讓語音合成技術(shù)能夠達(dá)到真人說話水平的系統(tǒng)。5.0分代表播音員的水平,4.0分代表美國(guó)普通老百姓的發(fā)音水平。
在人機(jī)交互系統(tǒng)上,科大訊飛于11月發(fā)布了AIUI2.0系統(tǒng),支持遠(yuǎn)場(chǎng)降噪、方言識(shí)別和多輪對(duì)話的技術(shù)的基礎(chǔ)上又增加了主動(dòng)式對(duì)話、多模態(tài)交互、自適應(yīng)、個(gè)性化識(shí)別等能力并能在嘈雜會(huì)場(chǎng)完成全雙工翻譯功能。
而科大訊飛的云端語音開放平臺(tái),截至2017年12月,累計(jì)終端數(shù)達(dá)到15億,日均交互次數(shù)達(dá)到40億,開發(fā)者團(tuán)隊(duì)數(shù)已達(dá)50萬。
語音識(shí)別還有哪些沒有解決的問題?
深度學(xué)習(xí)應(yīng)用到語音識(shí)別領(lǐng)域之后,詞錯(cuò)率有顯著降低,但是并不代表解決了語音識(shí)別的所有問題。認(rèn)識(shí)這些問題,想辦法去解決,是語音識(shí)別能夠取得進(jìn)步的關(guān)鍵所在,將 ASR(自動(dòng)語音識(shí)別)從“大部分時(shí)間僅適用于一部分人”發(fā)展到“在任何時(shí)候適用于任何人”。
1.口音和噪聲
語音識(shí)別中最明顯的一個(gè)缺陷就是對(duì)口音和背景噪聲的處理。最直接的原因是大部分的訓(xùn)練數(shù)據(jù)都是高信噪比、帶有口音的語言。比如單是為美式口音英語構(gòu)建一個(gè)高質(zhì)量的語音識(shí)別器就需要 5000 小時(shí)以上的轉(zhuǎn)錄音頻,因而僅憑訓(xùn)練數(shù)據(jù)很難解決掉這個(gè)問題。
在中國(guó),口音問題解決得比較好的,是科大訊飛。科大訊飛目前推出了22種方言相關(guān)的語音識(shí)別系統(tǒng),但對(duì)于那些音素體系與漢語不同的方言或外國(guó)語種,在成本問題上還沒有很好的辦法。
2.多人會(huì)話
每個(gè)說話人使用獨(dú)立的麥克風(fēng)進(jìn)行錄音,在同一段音頻流中不存在多個(gè)說話人的語音重疊,這種情況下的語音識(shí)別任務(wù)比較容易。然而,人類即使在多個(gè)說話人同時(shí)說話的時(shí)候也能夠理解說話內(nèi)容。一個(gè)好的會(huì)話語音識(shí)別器必須能夠根據(jù)誰在說話對(duì)音頻進(jìn)行劃分(Diarisation),還應(yīng)該理解多個(gè)說話人語音重疊的音頻(聲源分離)。
在利用語音技術(shù)推動(dòng)輸入和交互模式變革的過程中,仍面臨這些阻礙。多人對(duì)話等場(chǎng)景下的語音識(shí)別率雖然很高,聲紋識(shí)別雖然也已經(jīng)在實(shí)驗(yàn)室實(shí)現(xiàn),但距離實(shí)際應(yīng)用還有一些距離。
3.認(rèn)知智能
語音識(shí)別技術(shù)在質(zhì)檢、安全等方面有很好的應(yīng)用,但是對(duì)于人類所希望達(dá)到100%的識(shí)別率來說,從科研角度看肯定還有很多需要繼續(xù)努力的地方。比如減少語義錯(cuò)誤、理解上下文上(機(jī)器的學(xué)習(xí)和推理),我們才僅觸及皮毛。“ 認(rèn)知智能有沒有真正的突破,是這一輪人工智能熱潮——包括產(chǎn)業(yè)化熱潮——能不能進(jìn)一步打開天花板、進(jìn)一步形成更大規(guī)模的產(chǎn)業(yè)的關(guān)鍵技術(shù)所在”,2017年底,科技部正式發(fā)文將依托科大訊飛建立首個(gè)認(rèn)知智能國(guó)家重點(diǎn)實(shí)驗(yàn)室。
未來五年內(nèi),語音識(shí)別領(lǐng)域仍然存在許多開放性和挑戰(zhàn)性的問題,如,在新地區(qū)、口音、遠(yuǎn)場(chǎng)和低信噪比語音方面的能力擴(kuò)展;在識(shí)別過程中引入更多的上下文;Diarisation 和聲源分離;評(píng)價(jià)語音識(shí)別的語義錯(cuò)誤率和創(chuàng)新方法;超低延遲和高效推理等。盡管語音識(shí)別目前成果斐然,但剩下的難題和已克服的一樣令人生畏。雖然近幾年深度神經(jīng)網(wǎng)絡(luò)的興起使得語音識(shí)別性能獲得了極大的提升,但是我們并不能迷信于現(xiàn)有的技術(shù),總有一天新技術(shù)的提出會(huì)替代現(xiàn)有的技術(shù)。
除技術(shù)外,一個(gè)AI企業(yè)的那些事兒
人工智能催生了大量新技術(shù)、新企業(yè)和新業(yè)態(tài),人工智能火熱背景下, 作為A股人工智能龍頭股科大訊飛,曾在一個(gè)月猛增360多億元,市值突破千億。似乎很正契合普通百姓對(duì)“AI”神化的認(rèn)知。
2017年11月15日,中國(guó)新一代人工智能發(fā)展規(guī)劃暨重大科技項(xiàng)目啟動(dòng)會(huì)在京召開,科技部公布我國(guó)第一批國(guó)家人工智能開放創(chuàng)新平臺(tái),包括:1、依托百度公司建設(shè)自動(dòng)駕駛國(guó)家新一代人工智能開放創(chuàng)新平臺(tái);2、依托阿里云公司建設(shè)城市大腦國(guó)家新一代人工智能開放創(chuàng)新平臺(tái);3、依托騰訊公司建設(shè)醫(yī)療影像國(guó)家新一代人工智能開放創(chuàng)新平臺(tái);4、依托科大訊飛公司建設(shè)智能語音國(guó)家新一代人工智能開放創(chuàng)新平臺(tái)。作為首批入選國(guó)家新一代人工智能開放創(chuàng)新平臺(tái),目前的科大訊飛,用劉慶峰的話說是“現(xiàn)在還未到達(dá)登頂?shù)臓顟B(tài),只能說是已經(jīng)開始登山,剛克服了爬坡之后的艱難,開始到慢慢適應(yīng)的狀態(tài)”,如同語音識(shí)別技術(shù)現(xiàn)狀。
人工智能是個(gè)大趨勢(shì),本身也是需要很重投入的,但它也會(huì)有更長(zhǎng)遠(yuǎn)的影響,所以不能特別短視于此時(shí)此刻的回報(bào)上。“必須具備了強(qiáng)技術(shù),才能形成剛需”,“就是要把技術(shù)做深做透,做到大家真正覺得有剛需”,劉慶峰說,“我們瞄準(zhǔn)著五到十年更前沿的技術(shù)研究”。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論