 電子發燒友App
電子發燒友App


Yann LeCun在很多演講中反復提到一個著名的“蛋糕”比喻:
如果人工智能是一塊蛋糕,那么強化學習( Reinforcement Learning)是蛋糕上的一粒櫻桃,監督學習(Supervised Learning)是外面的一層糖霜,無監督學習( Unsupervised Learning)則是蛋糕胚。
目前我們只知道如何制作糖霜和櫻桃,卻不知如何制作蛋糕胚。

到12月初巴塞羅那的NIPS 2016時,LeCun就開始使用“預測學習”(Predictive Learning)這個新詞,來代替蛋糕胚“無監督學習”了。
LeCun在演講中說道:
我們一直在錯過一個關鍵因素就是預測(或無監督)學習,這是指:機器給真實環境建模、預測可能的未來、并通過觀察和演示來理解世界是如何運行的能力。
這是一個有趣的微妙的變化,暗示了LeCun對于“蛋糕”看法的改變。其觀點認為在加速AI發展進程之前,有很多的基礎性工作要完成。換句話就是,通過增加更多的能力(比如記憶、知識基礎和智能體)來建立目前的監督式學習,這意味著在我們能夠建造那個“預測性的基礎層級”之前,還有很多漫長艱辛的路途要走。
在其最新的NIPS 2016的演講中,LeCun放出了這么一張PPT,列出了AI發展中的障礙:

機器需要學習/理解世界是如何運行的(包括物理世界、數字世界、人等,獲得一定程度的常識)
機器需要學習大量的背景知識(通過觀察和行動實現)
機器需要觀察世界的狀態(以做出精準的預測和計劃)
機器需要更新并記憶對世界狀態的估測(關注重大事件,記住相關事件)
機器需要推理和規劃(預測哪些行為,會最終導致理想的世界狀態)
預測學習,很顯然要求其能夠不僅在無人監督的情況下學習,而且還能夠習得一種預測世界的模型。LeCun正在嘗試改變我們對AI的固有分類的原因,或許是在表明,AI離最終的目標還有很多艱辛的路途要走。
最近受雇于蘋果的Ruslan Salakhudinov教授曾做過一個關于無監督學習的演講,在他演示的這張PPT的最右下角,提到了“生成對抗網絡”(GANs)。
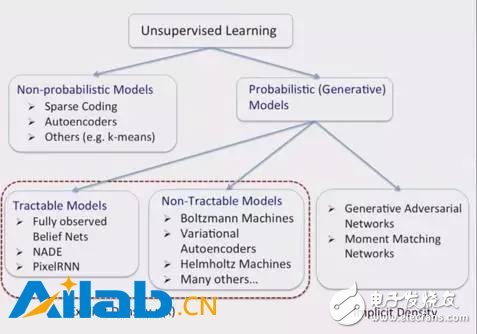
GANs由相互競爭的神經網絡組成:生成器和辨別器,前者試圖產生假的圖像,后者鑒別出真正的圖像。
GANs系統有趣的特點就是,一個封閉的形狀損失函數并不是必須的。實際上,一些系統能夠發現自己的損失函數,這是很令人驚喜的。但GANs網絡的一個缺點,就是很難訓練,這當中需要為一個非合作性的雙方博弈,找到一個納什均衡。
Lecun在一個最近的關于無監督學習的演講中稱,對抗性網絡是“20年來機器學習領域最酷的想法”。
Elon Musk所資助的非營利研究組織OpenAI,對生成模型格外偏愛。他們的動力可以總結為理查德·費曼的一句名言“不是我創造的,我就不能理解”(What I cannot create, I do not understand)。費曼這里其實是指“首要原則”(First Principles)思考方法:通過構建驗證過的概念來理解事物。
在AI領域,或許就是指:如果一個機器能夠生成具有高度真實感的模型(這是一大飛躍),那么它就發展出了對預測模型的理解。這恰好就是GANs所采取的方法。
這些圖片都是由GANs系統根據給定詞匯生成的。比如,給定詞匯有“紅腳鷸”、“螞蟻”、“修道院”和"火山",便生成了如下圖像。
這些生成的圖像很令人驚艷,我想很多人類都不會畫得這樣好。
當然,這個系統也不是完美的,比如下面這些圖像就搞砸了。但是,我見過很多人在玩“畫圖猜詞”游戲時畫得比這些糟糕多了。
目前的共識是,這些生成模型并不能準確捕捉到給定任務的“語義”:它們其實并不能理解“螞蟻”、“紅腳鷸”、"火山"等詞的意義,但卻能很好地進行模仿和預測。這些圖片并不是機器基于原有訓練圖片庫的再創造,而是根據通用模型(Generalized Model)所推斷出的非常接近現實的結果。
這種使用對抗性網絡的方法,異于經典的機器學習方法。我們有兩個互相競爭的神經網絡,但又好像在共同協作達成一種“泛化能力”( Generalization)。
在經典的機器學習領域,研究人員先定義一個目標函數,然后使用他最喜愛的優化算法。但這當中有一個問題,那就是我們都無法準確得知所定的目標函數是否是正確的。而GANs令人驚喜的地方在于,它們甚至能夠習得自己的目標函數!
這里一個迷人的發現就是,深度學習系統可塑性極強。經典的機器學習認為目標函數和約束條件都是固定的觀念,或者認為最優算法是固定的觀念,此時并不適用于機器學習領域了。而更令人驚喜的是,甚至元級(Meta-Level)方法也能夠使用,也就是說,深度學習系統可以學習“如何學習”了。










 工商網監
工商網監
評論