") Ampere Altra系列處理器的鎖和內(nèi)存序
Ampere Altra系列處理器的鎖和內(nèi)存序
AMPERE ALTRA和AMPERE ALTRA MAX 的鎖機(jī)制
讓我們先來(lái)了解一些基本的問(wèn)題。Arm 在 Arm?v8.2-A 架構(gòu)中引入了大型系統(tǒng)擴(kuò)展(Large System Extensions, LSE),它用單個(gè)原子指令取代了鎖操作的指令序列。這里 (https://dev.to/aws-builders/large-system-extensions-for-aws-graviton-processors-3eci)是一個(gè)非常不錯(cuò)的總結(jié)。雖然舊的 Arm 版本在功能上可以很好地工作,但隨著核心數(shù)量的增加和鎖的爭(zhēng)用更加頻繁,預(yù)計(jì)性能會(huì)受到影響。Ampere Altra 和 Ampere Altra Max 支持 LSE,并配備了可擴(kuò)展的鎖性能。
為了說(shuō)明使用的指令之間的差異,讓我們看看 gcc 的處理方式
__atomic_fetch_add()。在本例中,將鎖值減 1:
__atomic_fetch_add(&lockptr->lockval, -1, __ATOMIC_ACQ_REL);
使用* -march =armv8.2-a*選項(xiàng)編譯,編譯器生成帶有原子指令的代碼:
998: f8f60280 ldaddal x22, x0, [x20]
另一方面,設(shè)置* -march =armv8-a*(不支持LSE),生成一個(gè)不同的序列:
9a4: c85ffe60 ldaxr x0, [x19] 9a8: d1000400 sub x0, x0, #0x1 9ac: c801fe60 stlxr w1, x0, [x19] 9b0: 35ffffa1 cbnz w1, 9a4
為了使序列具有原子性,需要一個(gè)單獨(dú)的監(jiān)視器。ldaxr 獲得一個(gè)地址標(biāo)記,在本例中為 [x19]。然后執(zhí)行減法,然后存儲(chǔ)回內(nèi)存位置。但是,只有當(dāng)存儲(chǔ)(store)時(shí)的標(biāo)記與加載(Load)中的標(biāo)記匹配時(shí),存儲(chǔ)才會(huì)成功。stlxr 之后的條件分支 cbnz 檢查存儲(chǔ)是否成功,這意味著 load 和 store 中的標(biāo)記匹配。如果不是,則跳回序列的開頭,在本例中是地址 0x9a4。
這里值得注意的是,如果沒有 LSE 指令,這個(gè)指令序列可能要執(zhí)行幾次才能被認(rèn)為成功。使用 LSE, ldaddal 指令可以保證以一條指令完成,不需要循環(huán)。
圖 1 顯示了當(dāng)線程數(shù)從 1 增加到 80 時(shí),使用 LSE 和不使用 LSE 時(shí)每秒獲得排他鎖的性能差異。
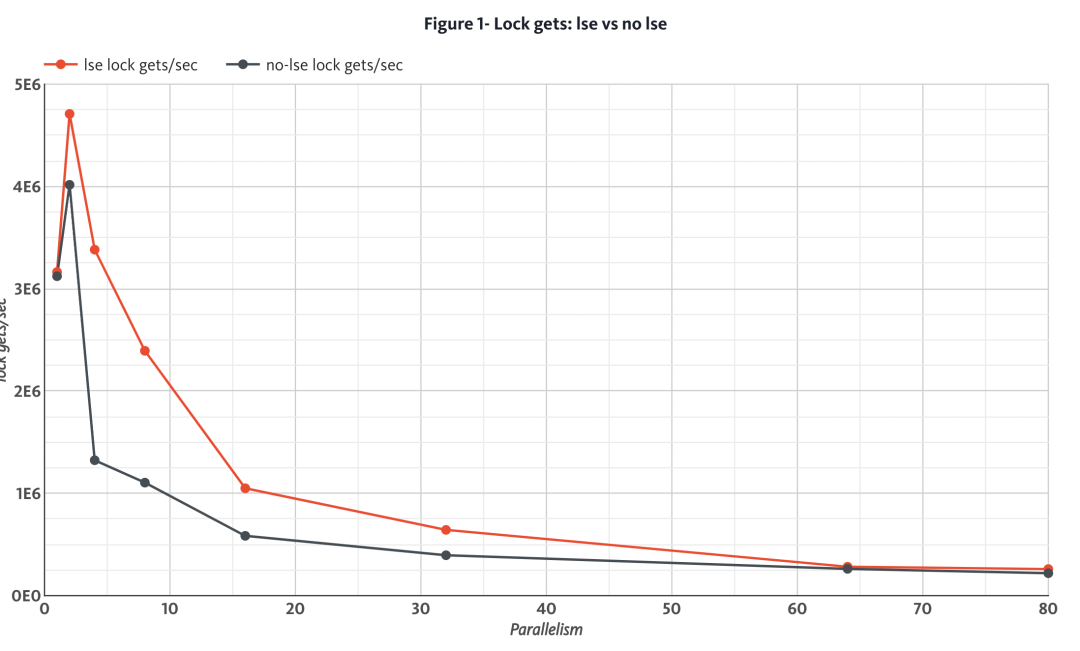
圖 1
通常,Compare 和 Exchange 硬件指令用于在軟件中實(shí)現(xiàn)鎖。需要注意的是,這些指令必須是原子指令。
原子在這里是什么意思呢?這些指令首先獲得包含鎖的緩存行(Cache Line)的所有權(quán),并將其加載到 CPU 的本地緩存中。然后將當(dāng)前值與隨指令提交的比較值進(jìn)行比較。如果相等,作為指令一部分提交的新值將替換當(dāng)前值。如果不相等,則保持當(dāng)前值。這方面的原子性意味著整個(gè)序列由一個(gè)線程執(zhí)行,而沒有其他線程訪問(wèn)緩存行,由硬件保證。
鎖的種類
在軟件中可以實(shí)現(xiàn)不同類型的鎖,如互斥鎖(mutexes)、票據(jù)鎖(ticket)和自旋鎖(spinlocks)。如前所述,不同的鎖類型在軟件中實(shí)現(xiàn),硬件提供類似 cmpxchg 或 fetchadd 的指令。相同的鎖類型在不同的硬件上運(yùn)行,只有使用的指令不同。
如何實(shí)現(xiàn)鎖機(jī)制
這是一個(gè)非常重要的問(wèn)題。讓我們把它分解成兩個(gè)選項(xiàng):1) 使用可用的庫(kù)和 2) 使用原子指令來(lái)實(shí)現(xiàn)專有的鎖定算法。
選項(xiàng)1有幾個(gè)優(yōu)點(diǎn)。庫(kù)已經(jīng)存在,不需要自定義實(shí)現(xiàn),而且經(jīng)過(guò)了充分測(cè)試,通常將會(huì)在未來(lái)的庫(kù)版本中進(jìn)行維護(hù)。例如pthread_mutex_lock和pthread_rwlock。聽起來(lái)不錯(cuò),那么有什么缺點(diǎn)呢? 缺乏統(tǒng)計(jì)數(shù)據(jù)可能是一個(gè)問(wèn)題。沒有向應(yīng)用程序返回任何信息,報(bào)告旋轉(zhuǎn)(spins)或線程被調(diào)度出多少次。此外,庫(kù)實(shí)現(xiàn)可能不太適合某些應(yīng)用程序,因?yàn)閹?kù)更通用。

pthread_mutex_lock
https://pubs.opengroup.org/onlinepubs/007908799/xsh/pthread_mutex_lock.html
選項(xiàng) 2 更復(fù)雜。它需要實(shí)現(xiàn)鎖定函數(shù)并維護(hù)它們。但是,它可以獲得一些好處,因?yàn)樗菍iT為應(yīng)用程序設(shè)計(jì)的。鎖定原語(yǔ)和原子指令可以通過(guò)內(nèi)聯(lián)匯編(inline assembly)或利用編譯器的支持來(lái)實(shí)現(xiàn)。同樣,使用內(nèi)聯(lián)程序集編寫代碼需要應(yīng)用程序維護(hù)該段代碼。
對(duì)于編譯器,gcc提供了atomic built-in function,它允許應(yīng)用程序使用低級(jí)函數(shù),這些函數(shù)將被編譯成 Arm 原子指令。這些內(nèi)置函數(shù)為應(yīng)用程序提供了原子指令和內(nèi)存序指令的不同方法。代碼也更易于移植。但是,使用*-mcpu或-march*的正確設(shè)置來(lái)編譯應(yīng)用程序來(lái)生成 Arm LSE 指令是很重要的。Ampere Altra 和 Ampere Altra Max 使用 Neoverse-n1 架構(gòu),其中就包括LSE。
atomic built-in function
https://gcc.gnu.org/onlinedocs/gcc/_005f_005fatomic-Builtins.html
然而,使用原子指令實(shí)現(xiàn)鎖需要設(shè)計(jì)決策。如果鎖被持有,旋轉(zhuǎn)(spinning)是否合理?轉(zhuǎn)幾圈?線程在旋轉(zhuǎn)一定次數(shù)后如果不成功,是否應(yīng)該放棄?在旋轉(zhuǎn)環(huán)中需要后退,還是直線旋轉(zhuǎn)? 這些只是需要解決的問(wèn)題中的一部分。
其他的設(shè)計(jì)決策
1鎖的數(shù)據(jù)類型和大小
通常,應(yīng)用程序使用 int 或long 作為鎖。用于原子操作的內(nèi)置函數(shù)(Built-in functions)從內(nèi)存中讀取鎖值。如果應(yīng)用程序也直接讀取鎖值,鎖類型應(yīng)該有“volatile”前綴,例如 volatile long。使用 volatile,編譯器生成從內(nèi)存中讀取數(shù)據(jù)的指令。否則,該值可能在寄存器中而沒有更新,從而錯(cuò)過(guò)對(duì)鎖位置的更新。
2鎖的粒度
由于競(jìng)爭(zhēng),粗粒度鎖有可能成為性能瓶頸。另一方面,如果每個(gè)資源都有自己的鎖來(lái)保護(hù),那么將需要大量?jī)?nèi)存來(lái)存儲(chǔ)鎖。必須是一種折衷設(shè)計(jì),以避免任何不利因素。
3鎖對(duì)齊
編譯器對(duì)結(jié)構(gòu)進(jìn)行正確對(duì)齊。如果應(yīng)用程序管理自己的內(nèi)存,那么鎖的位置可能與鎖的大小不一致。在最壞的情況下,鎖可能跨越兩條緩存行。在 AArch64 上,對(duì)未對(duì)齊鎖的原子操作會(huì)導(dǎo)致 SIGBUS (硬件向操作系統(tǒng)發(fā)出信號(hào),表明 CPU 不能尋址內(nèi)存地址的總線錯(cuò)誤,在這種情況下是由于未對(duì)齊訪問(wèn))。從積極的方面來(lái)看,獲得 SIGBUS 需要固定對(duì)齊,而不是隱藏很少被發(fā)現(xiàn)的性能問(wèn)題。
4假共享
虛假分享是什么意思?即同一高速緩存行上的獨(dú)立數(shù)據(jù)對(duì)性能有不良影響,鎖數(shù)組就屬于這一類。這些鎖保護(hù)不同的關(guān)鍵區(qū)域。但是,對(duì)同一緩存行上鎖的原子操作會(huì)影響該緩存行上的所有鎖。重要的是,原子性不是針對(duì)鎖本身,而是針對(duì)包含鎖的整個(gè)緩存行。
5在 cmpxchg 之前做測(cè)試
在執(zhí)行 cmpxchg 指令之前讀取自旋循環(huán)(spinloop)中的鎖值可能對(duì)爭(zhēng)用鎖有利。Cmpxchg 需要緩存行的所有權(quán),而test將以共享模式獲取緩存行,從而避免失效。然而,這可能會(huì)增加執(zhí)行的 spin 數(shù)量。
6如果可能的話,在無(wú)鎖時(shí)
使用fetchadd 而不是 cmpxchg
釋放鎖需要返回線程為獲取鎖而執(zhí)行的操作。Cmpxchg,特別是對(duì)于共享鎖或讀寫鎖,需要一個(gè)循環(huán),并且由于鎖值的變化而可能會(huì)重試操作。然而,fetchadd 不需要循環(huán),沒有比較,因此它會(huì)成功。
7鎖定持有時(shí)間
通常指臨界區(qū)域內(nèi)的指令數(shù)或在臨界區(qū)域內(nèi)花費(fèi)的時(shí)間。時(shí)間是一個(gè)更好的度量標(biāo)準(zhǔn),因?yàn)榕R界區(qū)域可能只有很少的指令。然而,所有的指令都可以從內(nèi)存中讀取。嵌套鎖屬于同一類別。無(wú)法獲得內(nèi)部鎖以及 spinning 或 sleeping 會(huì)影響外部鎖的保持時(shí)間。減少關(guān)鍵區(qū)域的保持時(shí)間總是好的,如果數(shù)據(jù)在本地緩存而不是內(nèi)存中就更好了。
8搶占
不幸的是,線程在持有鎖時(shí)可能會(huì)被重新調(diào)度。如果鎖處于獨(dú)占模式,這意味著沒有其他線程能夠獲得鎖。在考慮性能問(wèn)題時(shí),要記住這一點(diǎn)。較短的保持時(shí)間將降低搶占的可能性。
內(nèi)存序
如前所述,正確的內(nèi)存排序指令對(duì)于正確性很重要。AArch64 遵循一種寬松的內(nèi)存模型。使用 LSE, AArch64 指令強(qiáng)制執(zhí)行特定的內(nèi)存順序。例如,cmpxchg 指令集有獲取(CASA 指令)、釋放(CASL 指令)以及獲取和釋放(CASAL 指令)的版本。硬件保證這些指令遵循其特定指令的內(nèi)存模型。這取決于軟件使用適當(dāng)?shù)闹噶睢Mǔ#琣cquire 用于鎖獲取,Release 用于鎖釋放。但是,如果應(yīng)用程序在無(wú)鎖之后讀取數(shù)據(jù)(例如,如果該鎖有任何等待程序),那么空閑程序的 release 語(yǔ)義可能會(huì)導(dǎo)致問(wèn)題,因?yàn)閷?duì)等待程序結(jié)構(gòu)的讀取可能會(huì)提升到空閑程序之上,因此在空閑程序之后,寄存器中就會(huì)出現(xiàn)陳舊的數(shù)據(jù)。在這些情況下,最好使用 acquire 和 release 語(yǔ)義。同樣,這取決于應(yīng)用程序?qū)崿F(xiàn)。gcc 編譯器直接在內(nèi)置函數(shù)中使用這些指令,如下列網(wǎng)址所示。
https://gcc.gnu.org/onlinedocs/gcc/_005f_005fatomic-Builtins.html
總結(jié)
Ampere 系列處理器正以其持續(xù)增加的核心數(shù)量不斷挑戰(zhàn)性能極限,并具備使用鎖的多線程應(yīng)用程序可擴(kuò)展性的所有要素。使用 LSE,在硬件中提供原子指令以獲得更好的鎖性能。正如我們?cè)诒疚乃吹降模瑧?yīng)用程序開發(fā)人員可以通過(guò)鎖庫(kù)或正確實(shí)現(xiàn)鎖定算法來(lái)充分利用這些指令。
關(guān)于 Ampere Computing
Ampere Computing 是一家現(xiàn)代化半導(dǎo)體企業(yè),致力于塑造云計(jì)算的未來(lái),并推出了世界上首款云原生處理器。為可持續(xù)云而生,Ampere 云原生處理器兼具最高性能和最佳每瓦性能,助力加速多種云計(jì)算應(yīng)用的交付,為云提供行業(yè)領(lǐng)先的性能、能效和可擴(kuò)展性。
審核編輯:湯梓紅
-
處理器
+關(guān)注
關(guān)注
68文章
19409瀏覽量
231201 -
ARM
+關(guān)注
關(guān)注
134文章
9169瀏覽量
369239 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3055瀏覽量
74337 -
指令
+關(guān)注
關(guān)注
1文章
611瀏覽量
35817 -
Ampere
+關(guān)注
關(guān)注
1文章
70瀏覽量
4566
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Ampere推出業(yè)內(nèi)首款擁有最多內(nèi)核數(shù)量的云原生處理器系列
業(yè)界首款!Ampere發(fā)布有80個(gè)核心的ARM處理器
Ampere發(fā)布業(yè)內(nèi)首款80核ARM架構(gòu)64位處理器Altra 并已開始向云服務(wù)和邊緣計(jì)算客戶出樣
Ampere全新推出業(yè)界首款80核服務(wù)器處理器Ampere Altra?處理器
安晟培半導(dǎo)體Ampere Altra處理器推出,應(yīng)用于云和邊緣計(jì)算數(shù)據(jù)中心中
詳細(xì)解說(shuō)Ampere Altra性能測(cè)試與結(jié)果對(duì)比
Ampere Altra處理器實(shí)現(xiàn)Arm架構(gòu)運(yùn)行虛擬機(jī)
HPE正式發(fā)布搭載Ampere云原生處理器的HPE ProLiant RL300 Gen11平臺(tái)
Ampere Computing發(fā)布全新AmpereOne系列處理器,192個(gè)自研核
Ampere全新AmpereOne系列處理器,多達(dá)192個(gè)單線程Ampere核
Ampere發(fā)布AmpereOne系列處理器,單顆處理器支持最高192個(gè)物理核心

優(yōu)化指南-Ampere? Altra?系列處理器的鎖和內(nèi)存序

全新AmpereOne系列處理器,一款192核的云原生CPU





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論