 電子發燒友App
電子發燒友App


隨著云計算和超大規模數據中心對帶寬網絡設備和連通性的要求越來越高,交換機技術從 25Tb/s 升級到了 51Tb/s,并很快會達到 100Tb/s。業界已選擇以太網來推動交換機市場,目前采用 112G SerDes 或 PHY 技術,未來將采用 224G SerDes。正如 Arista Network 聯合創始人兼董事長 Andreas Bechtolsheim 在圖 1 中強調的那樣,112G SerDes 的部署將在 2025 年達到峰值。本文介紹了設計師如何克服設計挑戰(例如功耗、面積、封裝、信號完整性、電源完整性),以及使用 112G 以太網 PHY IP 實現 800G 以太網 HPC 系統。
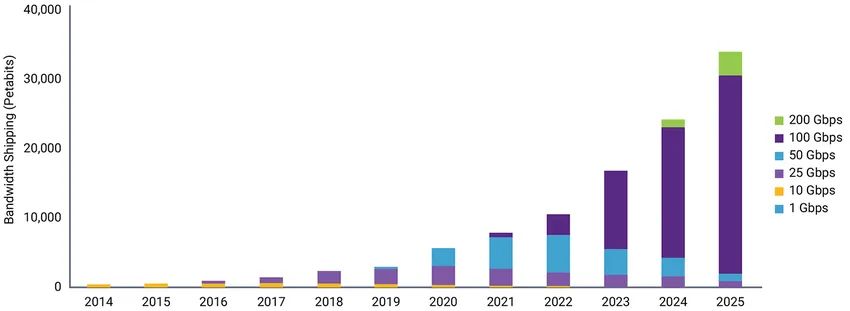
圖 1:交換機芯片 SerDes 的速度從每通道 100G 提升到 200G
來源:市場焦點:通往 800G 及更高速率之路 - Arista Networks
設計挑戰
面積和功耗
隨著使用更低功率調制技術(如PAM-4)和高速 SerDes 技術(如 112 以太網 PHY)的增加,從 7nm 到 5nm 到 3nm 過渡到更先進的工藝技術,降低功率和縮減面積成為一個關鍵焦點。此外,由于良率問題,晶粒尺寸也存在限制。因為服務器盒和計算盒必須安裝在機架單元中的同一機箱中,因此,為了保持相同的大小,以太網交換機SoC中的組件需要更密集的集成,如圖 2 所示。

圖 2:數據中心和 ToR 交換機 SoC 中服務器機架的空間限制
然而,SoC 組件的這種密集集成導致功耗增大,并且需要昂貴的冷卻系統。所有這些因素都使得面積、功耗和延遲成為高密度交換機的關鍵指標或挑戰。它們還會影響性能,因為交換機的 SoC 包含數百條通道,使得系統性能比單個 SerDes 性能更重要。
演進到共封裝光學器件
數據中心光學器件也在不斷演變,以支持更高帶寬的網絡需求。光學和 ASIC 都必須解決光開關互連中的面積、功率和延遲問題,并將光開關的電氣 I/O 功耗降至最低。圖 3 顯示了可插拔光學電源的演變,這是目前的首選技術。
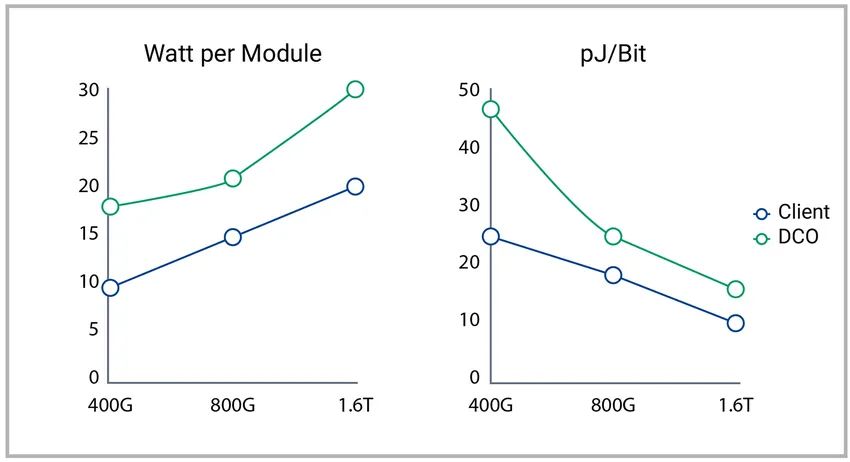
圖 3:每比特光學器件功率顯著下降
資料來源:市場焦點:通往 800G 及更高速率之路 - Arista Networks 包括甚短距離 (VSR) 和直接驅動(無 DSP)在內的各種SerDes架構正在解決交換機和光學模塊中的功耗挑戰。在下一代數據中心中,主機側具有 VSR PHY 的超高速可插拔光學器件的功耗將低于中距離或長距離 PHY的功耗。因此,放置在交換機 SoC 附近,與 VSR PHY(消耗 2.5-3 pJ/b)的共封裝光學器件 (CPO) 的概念正在不斷發展。目前,CPO 概念的 12Tb/s,25Tb/s 器件已經可用,51Tb/s 處于試點階段,預計很快會達到 100Tb/s 的批量部署。交換機接口上的長距離 PHY(無論是共封裝還是直接驅動光學組件)也可以通過消除 retimer 來降低功耗。一種新興的 2.5D/3D 硅光子光學連接技術,它使從高密度可插拔 (OSFP-XD) 到 CPOs 的一系列光模塊成為可能。SerDes IP 提供商持續關注生態系統,以繼續應對功耗挑戰。
信號完整性
盡量減少影響上市時間的風險因素是 SoC 設計師的關鍵目標。克服系統信號完整性挑戰便是其中的一個風險因素。100Gbps 的高速信號彼此之間必須具有最小的串擾 (xtalk) 影響,同時避開晶粒邊緣。增加封裝層數是解決方案之一,但會導致成本更高。為了滿足高速 SerDes 串擾規格,同時最大限度地減少出線層數量和外緣尺寸,設計師必須優化通過封裝的高速信號路徑。封裝設計師和信號完整性專家必須與 SerDes 設計師一起創建 SerDes 封裝信號位置圖,并進行布線研究和高頻仿真以驗證符合串擾規格。由于晶粒尺寸限制,51Tb/s 交換機和 AI 加速器需要將 112G SerDes 或 PHY 放置在所有晶粒邊緣和多個堆疊中。由于信號出線方向不同,因此需要對南北 (N/S)、東西 (E/W) 方向進行封裝出線的研究。此外,設計師需要考慮宏單元的雙重堆疊。此外,還需要考慮附近的功耗和接地平面及其阻抗。
設計師還必須:
使用不同電源(數字和模擬)創建多通道 SerDes(51Tb/s 交換機的 512 通道)的配電網絡 (PDN)
假設所有物理設備在任務模式下同時切換,執行電源完整性仿真
驗證電源交流紋波和最大值/最小值。使用 AC PDN 分析和瞬態仿真來驗證 SerDes 的直流規格限制
使用 PDN 共享 RL 模型執行 PDN 設計假設分析
與封裝和 PCB 一起進行 IR 壓降分析
保持最低的 PCB 低通濾波器 (LPF) 直流阻抗以及 PDN 直流阻抗
具有有限金屬層的宏單元的多個堆疊可能需要間隔,或者宏單元和數字邏輯之間的通道可以放置在此類通道/間隔中。SoC 實施者需要提供穩定的電源結構,并在通道上提供足夠的電源,以盡量減少任何 IR 壓降問題。在設計階段的早期,對全芯片進行的 IR 壓降分析將顯示通道中的任何弱電網。由于 IR 壓降修復而導致的電源結構和數字邏輯布局的任何變化都可能影響設計分區,也可能改變芯片平面布局。因此,早期分析對于減少任何對進度的影響是非常重要的。
以太網 MAC、PCS、PHY 實現
400G 和 800G 以太網的實現需要多個 PCS、MAC 和 PHY。SoC 設計師可以在考慮晶粒邊緣限制和核心區域限制后,在有或沒有宏單元堆疊時實現晶粒設計。這些晶粒塊可以是 N/S 和 E/W 方向,或是與方向無關的。通過有效的塊分區,可以實現兩個方向的單個晶粒。采用塊分區和優化的單個塊大小的假設分析可以靈活地重復使用晶粒所有邊緣周圍的塊。如果在早期設計階段發現了時序問題,就可以進行設計改進,例如在不影響延遲的情況下,如果塊之間相距很遠,就可以進行流水線設計。圖 4 展示了單個 800G 以太網晶粒的實現。
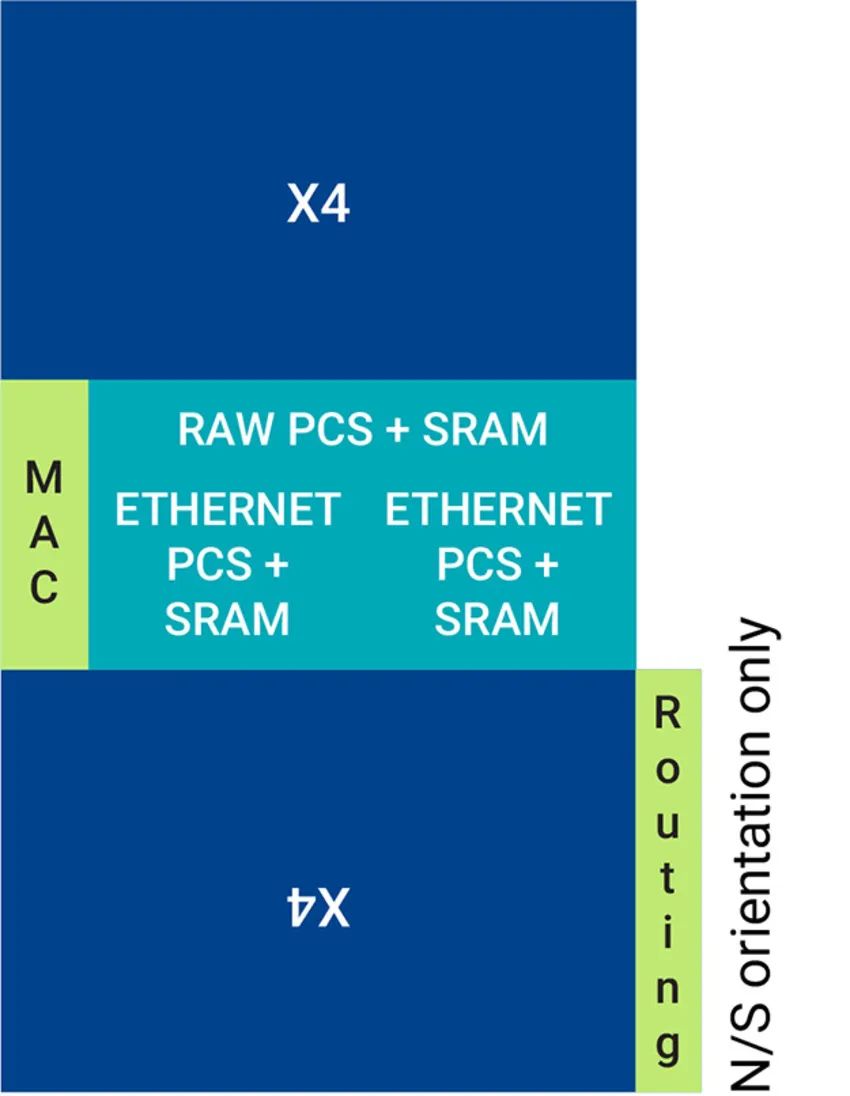
圖 4:可以把 PCS 和 MAC 放置在頂部 X4 宏和底部翻轉 X4 宏之間的間隙中,以實現靈活的時序收斂
上述實施方式對于南北方向晶粒邊緣上的高速信號的出線可能是行不通的。各種布局的試驗需要數月的嘗試和問題分析,例如將單個塊放置在所需通道中,并最小化內核芯片區域,都會導致時間延遲。由于多達 100 個通道設計和有限的晶粒面積和邊緣長度,具有指定邊界框的自上而下的設計方法正變得至關重要。塊式實現可確保所有晶粒邊緣的可重用性和無縫集成。
演進之路
? ? 112G SerDes 或 PHY 正在推動云數據中心的下一代計算、存儲和網絡創新,以實現高性能計算和 AI/ML。實現 112G SerDes 或 PHY 技術的以太網交換機 SoC 設計師必須考慮一系列關鍵指標或挑戰,如電源、面積、延遲、芯片堆疊、信號完整性、電源完整性和實現,所有這些都是在設計師已經很短的設計時間表中增加的任務。 借助先進 FinFET 節點中的經過硅驗證的 PAM-4 112G 以太網 PHY,以及 PCS、MAC 和先進 AI/ML 驅動的 EDA 工具,SoC 設計師能夠實現最佳的功耗、性能、面積和延遲,同時解決系統可靠性、電源完整性和信號完整性問題。 新思科技已完成了所有必要的工作,例如封裝逃逸研究、PHY、SRAM、PCS 和 MAC 布局優化,包括分區和平面圖、引腳布局、位置和路由、時序收斂和電遷移驗證/IR 壓降分析,幫助用戶成功完成例化上百個 112G SerDes 通道的大型 SoC 的定案。新思科技可以通過其邏輯庫、內存編譯器、EDA 工具、系統解決方案(如 3DIC)、集成的第三方工具(如 Apache/Redhawk),以及與 PHY、MAC、PCS 設計師,實現專家和系統專家的密切合作,給客戶提供一個全面的解決方案。也就是說,新思科技可為 112G 以太網 PHY、PCS 和 MAC 提供易于集成的交付產品,并提供專家級支持,幫助客戶縮短設計周期,加快產品上市時間。























 工商網監
工商網監
評論