
 NVIDIA發布Volta顯卡架構,但頻率紅利到頭了?
NVIDIA發布Volta顯卡架構,但頻率紅利到頭了?
NVIDIA這幾年壟斷了高端顯卡市場,從他們的Q1季度財報中雖然也能看到Tegra、數據中心等業務有了明顯增長,不過營收的主力還是游戲PC市場,Q1季度游戲PC市場營收就增長了50%,高端玩家現在買游戲顯卡往往是從GTX 1080 Ti/1080/1070中選一款了。如今Pascal還未顯出頹勢,今天凌晨的GTC 2017主題演講上,NVIDIA CEO黃仁勛發布了Volta架構顯卡,新一輪升級又要來了。
NVIDIA能夠獲得現在的表現很大程度是因為他們的產品路線圖比較連貫,從Kepler到Maxwell,再到現在的Pascal架構,NVIDIA每一代GPU升級都很穩定,短時間內就能完成高端到低端的布局。以Pascal這一代為例,首發的是GTX 1080、GTX 1070,接著是Titan X,陸陸續續又有GTX 1060 6GB及GTX 1060 3GB,還有GTX 1050 Ti、GTX 1050,今年3月份又有GTX 1080 Ti、Titan Xp,馬上還會有GT 1030主打入門級市場——不算不知道,NVIDIA在Pascal這一代的GPU產品組合還真是挺多的。
Pascal顯卡發布一年整了,產品線布局還在完善,不過大家的興趣點現在已經開始向新一代GPU轉移了,特別是今天發布了Volta架構顯卡——Telsa V100,這跟去年Pascal架構首發GP100核心的Telsa P100一樣,也在去年這個時候,我們撰文詳細介紹了GP100核心的改進情況,今天我們也會針對GV100核心及Tesla V100顯卡做更深入的探討。
早上已經有Tesla P100的新聞發布了,大家也了解過基本情況了,我們先來看看Tesla V100加速卡的真身,這次同時展示的是兩個版本的。
Tesla V100顯卡真身:NVLink與PCI-E版大不同
NVLink 2接口的Tesla V100顯卡(點擊放大,圖片來源于Heise)
老黃手里曝光最多的就是這個短小強悍的Tesla V100,它實際上NVLink版的,跟去年的Tesla P100看著很像,畢竟這二者都使用了HBM 2顯存,功耗也沒有明顯增加,應該是直接沿用相同的PCB電路。
PCI-E接口的Tesla V100顯卡(點擊放大,圖片來源于Golem)
PCI-E版的Tesla V100顯卡不太引人注意,找到了上面這張照片,如果跟去年PCI-E版的Tesla P100顯卡對比,可以看出PCI-E版Tesla V100顯卡跟PCI-E版P100有很多不同,散熱器明顯小多了,體積跟NVLink版差不多。
這是去年的PCI-E版Tesla P100加速卡
Telsa V100加速卡規格:Volta架構終于來了
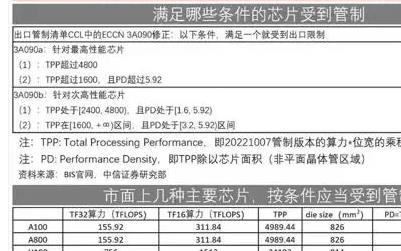
Tesla V100是針對HPC市場設計的,跟普通消費者沒啥關系(屬于吃瓜群眾買不到買不起系列),之所以引人關注是因為它使用的是新一代Volta架構,首發的依然是GV100這種大核心。早上的新聞中大家也看到了它各方面規格都很驚人——815mm2核心面積、211億晶體管、5120個CUDA核心、15TFLOPS浮點性能等等,放在當前的顯卡中簡直是鶴立雞群,拿來跑游戲不知道多爽,可惜老黃不賣給消費級玩家。

NVIDIA Volta/Pascal與AMD Vega顯卡的規格對比
為此我做了一個詳細的規格表,對比的產品除了目前的Tesla P100和Titan Xp之外,還加入了AMD的Vega 10核心的Radeon Instinct MI25顯卡,盡管還沒上市,但AMD早前公布過這款顯卡的一些信息,比如帶寬、浮點性能,不過Vega核心的晶體管、核心面積等關鍵參數還是個謎。
對比GP100核心與GV100核心,可以看出后者規模進一步擴大,SM單元數量從之前的56組提升到了80組,CUDA核心數從3584個提升到5120個,計算單元數量增幅為43%。顯存位寬及容量都沒變化,還是16GB HBM2顯存,不過頻率有所提升,帶寬從前代的720GB/s提升到了900GB/s,非常接近HBM 2顯存理論上1024GB/s的帶寬了(搭配4顆HBM顯存的情況下)。
計算單元的增加也使GV100核心的規模進一步擴大——晶體管數量從目前的153億增加到了211億,核心面積從610mm2提升到815mm2,一舉創造了NVIDIA GPU同時也是現代GPU的核心面積新紀錄。NVIDIA這幾代大核心雖然核心面積有漲有降,不過之前最多是在600mm2級別徘徊,這一次直接做了815mm2的大核心。
與Pascal架構GP100核心相比,Volta的GV100核心在架構上更多地是量變而非質變,不過它在架構也不是說沒升級,這次GV100核心主要的變化就是針對AI人工智能、DL深度學習等新興領域專門做了運算單元,我們下面再說這個。
Volta架構改進:Pascal翻新,新增Tensor單元
在之前解析GTX 1080與Tesla P100時,我們說過主流的GP104核心跟GP100核心是不同的,前者跟Maxwell架構沒多大變化,每組SM單元是128個CUDA核心,GP100上每組SM單元是64個CUDA核心,而后面的GP102核心跟GP100也不同,更像是GP104核心的擴大版,也是每組SM單元128個CUDA核心。

GP100核心架構示意圖
回到GP100與GV100大核心上,他們的架構也是漸進式變化,也是6組GPC計算單元,不過GP100核心每個GPC單元中是10組SM單元,每個SM單元有64個CUDA核心,而GV100大核心中每組GPC單元是14個SM單元,總數應該是84組SM單元,但是現在Tesla V100跟Tesla V100一樣都不是完全體,前者啟用了56組SM單元,后者啟用了80組SM單元,總計80x64=5120個CUDA核心。
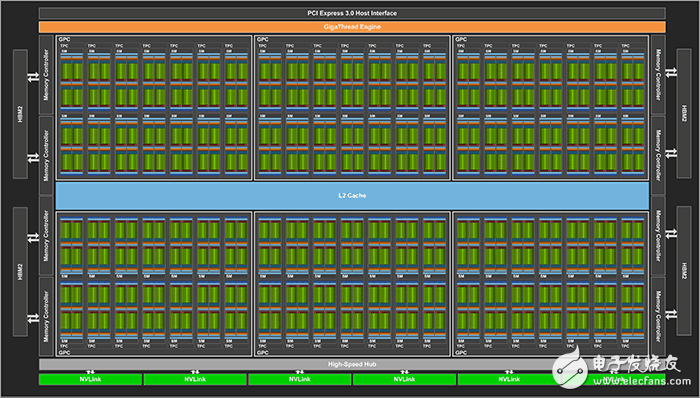
GV100核心架構示意圖
以上算的是典型的FP32單精度運算單元,除此之外還有FP64單元,GV100依然延續了GP100中FP32:FP64=2:1的比例,每個SM單元中有32個FP64單元,理論上有2688個FP64單元,實際啟用的是2560個。
NVIDIA這兩年在深度計算、人工智能等領域投入很多精力,GPU架構也在傳統HPC應用之外開始適應這些新興領域,他們對運算精度要求沒這么高,但對性能要求很高,Pascal顯卡中就開始支持FP16、FP8精度運算,執行這些運算的性能也是翻倍增長。

GV100與GP100核心SM單元的變化
因此在GV100大核心,NVIDIA還加入了專門的Tensor(張量)運算單元,大部分人估計不熟悉這個詞,不過還記得前不久Google搞的那個TPU在AI性能上吊打GPU的新聞嗎?Google的TPU處理器中的T也是Tensor這個詞,大家可以把它當作專用的AI運算單元來看。

GV100核心中增加了專門的Tensor運算單元(圖片來源于Golem網站)
在GV100大核心中,每組SM單元中還有8個Tensor單元,這樣整個SM單元中就是FP32:FP64:Tensor=64:32:8的比例存在,GV100也因此有了Tensor計算能力這個指標,Tesla P100的Tensor計算能力高達120TFLOPS,NVIDIA宣稱它的Tensor性能是Pascal架構的12倍。
Volta支持第二代NVLink技術:300GB/s帶寬
除了針對AI等新興領域改進了Tensor單元之外,GV100核心在總線技術上也有升級,這次使用的是NVLink 2,如果你注意看了上面的架構示意圖,應該可以發現GV100核心是6組NVLink通道,雙向總帶寬可達300GB/s。
相比之下,GP100核心上是4組NVLink通道,每個通道帶寬是40GB/s,總帶寬是160GB/s。
不論NVLink還是NVLink 2總線,相比PCI-E 3.0 x16雙向32GB/s的帶寬都有明顯提升,不過NVLkink并不是通用技術,主要用于IBM和NVIDIA開發的超算平臺,這次GV100核心就會用在雙方合作的Summit超算上,預計今年下半年正式啟用。
Volta工藝升級:這個12nm有點特別
NVIDIA在主題演講中還提到了Volta顯卡的制造工藝,使用的是TSMC的12nm FFN工藝,聽上去要比目前TSMC 16nm工藝更先進,那這種新工藝對Volta顯卡到底有什么改善嗎?我們依照上次的計算簡單評估下不同工藝下的晶體管密度及效能。
由于AMD Vega顯卡的核心面積、晶體管數量都是未知數,所以這里只對比了NVIDIA幾代顯卡的。

GV100核心是12nm工藝,211億晶體管,核心面積815mm2,算下來晶體管密度是每平方毫米25.9百萬晶體管,與16nm工藝的晶體管密度差不多。實際上,TSMC的12nm工藝也是16nm工藝的改良版。根據TSMC此前公布的資料,它實際是基于16nm FFC工藝改進的,性能是后者的1.1倍,功耗只有后者的70%,核心面積則可以縮小20%。
按照TSMC的說法,16nm FinFET Plus依然是他們性能最好的16nm工藝,現在GV100用的12nm工藝在性能上還真不一定能超過16nm FinFET Plus工藝,Tesla V100的加速頻率就比P100要低一些,但從核心面積來看,計算單元規模增加了43%,核心面積只增加了33%,說明這個12nm工藝對縮小面積還是挺管用的。
至于未來的消費級顯卡,GV102、GV104核心上12nm工藝也沒跑了,但顯卡的核心頻率不會再像Pascal對比Maxwell時代那樣大幅提升了,性能提升只能靠計算單元數量增加了。
Volta架構性能:比Pascal提升50%
說到性能,我們再簡單看下NVIDIA官方資料中介紹的GV100性能提升情況:
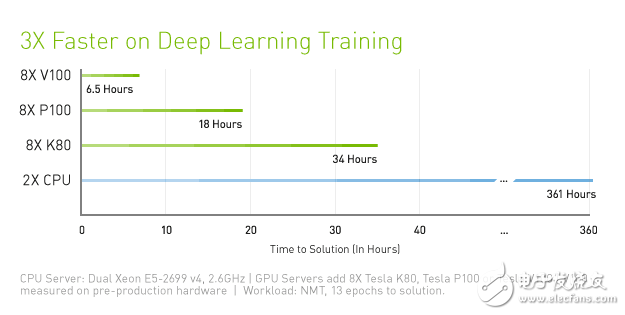
DL深度計算性能三倍快,這個因為有Tensor單元加持,性能暴漲很正常
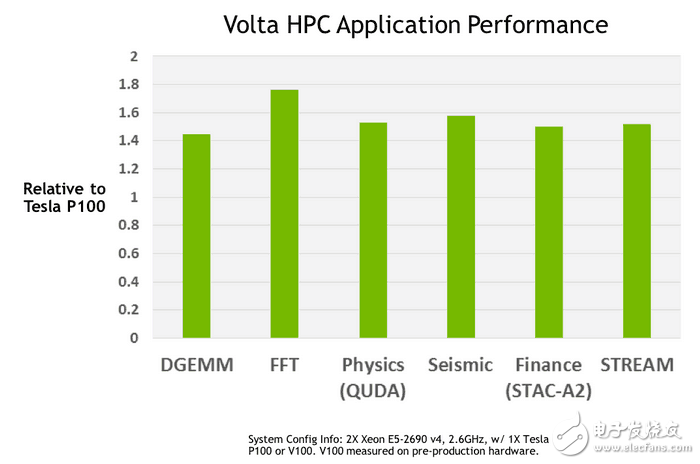
HPC性能提升情況
與Tesla P100加速卡相比,Tesla V100在不同HPC應用中性能提升有所不同,多的能超過70%,少的也有40%以上,官方給出的平均性能提升大約是50%——考慮到計算單元增幅也有43%,性能提升基本上與計算單元數量增幅呈正比,這跟Tesla P100時代頻率大幅提升帶來性能大提升的情況也有所不同。
總結:
GV100核心是為HPC運算市場而生的,跟Tesla P100的GP100核心一樣也不會用于消費級市場,所以這篇文章對我們的意義更多地是分析未來的GV102、GV104核心的GeForce 20系列顯卡的性能及表現。
與GV100一樣,GV102/104核心的CUDA核心數量也會進一步提升,NVIDIA還可以通過閹割對消費級市場沒什么用的FP64、Tensor單元來降低核心面積及成本,一如GP100到GP102那樣。
Volta架構使用的12nm工藝在降低核心面積上很有用,但是從GV100上的頻率來看,12nm下消費級Volta顯卡的核心頻率恐怕也很難有明顯提升了,現在的GTX 10系中高端非公版顯卡核心頻率都能達到2GHz左右,未來的12nm Volta顯卡估計也就是這個水平,甚至還有可能更低一些。
如果是這種情況,NVIDIA要想提高新一代顯卡的性能,那么就只能從CUDA核心數量上著手了,Pascal這一代在頻率上占了很多紅利,Volta又要回到GPU運算單元提升的道路上了。
目前消費級的Volta顯卡還沒有明確的發布時間,今年底有希望推出部分高端產品,不過更有可能的還是2018年Q1季度,所以現在的Pascal顯卡并不會受到什么沖擊,大家現在該買什么卡就買什么卡,不著急的也可以等等AMD發了Vega顯卡之后再看。不過NVIDIA看起來并不擔心AMD的競爭,黃仁勛在之前的財報會議上表態2017年的市場競爭態勢不會有什么變化,換言之就是AMD發布的Polaris 20及Vega 10顯卡對他對不會有什么影響。
































 工商網監
工商網監
評論